 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterResearch: Rethinking Long-Horizon Agents via Markovian State Reconstruction
Nov 10, 2025Recent advances in deep-research agents have shown promise for autonomous knowledge construction through dynamic reasoning over external sources. However, existing approaches rely on a mono-contextual paradigm that accumulates all information in a single, expanding context window, leading to context suffocation and noise contamination that limit their effectiveness on long-horizon tasks. We introduce IterResearch, a novel iterative deep-research paradigm that reformulates long-horizon research as a Markov Decision Process with strategic workspace reconstruction. By maintaining an evolving report as memory and periodically synthesizing insights, our approach preserves consistent reasoning capacity across arbitrary exploration depths. We further develop Efficiency-Aware Policy Optimization (EAPO), a reinforcement learning framework that incentivizes efficient exploration through geometric reward discounting and enables stable distributed training via adaptive downsampling. Extensive experiments demonstrate that IterResearch achieves substantial improvements over existing open-source agents with average +14.5pp across six benchmarks and narrows the gap with frontier proprietary systems. Remarkably, our paradigm exhibits unprecedented interaction scaling, extending to 2048 interactions with dramatic performance gains (from 3.5\% to 42.5\%), and serves as an effective prompting strategy, improving frontier models by up to 19.2pp over ReAct on long-horizon tasks. These findings position IterResearch as a versatile solution for long-horizon reasoning, effective both as a trained agent and as a prompting paradigm for frontier models.
MARS: Optimizing Dual-System Deep Research via Multi-Agent Reinforcement Learning
Oct 06, 2025Large Reasoning Models (LRMs) often exhibit a tendency for overanalysis in simple tasks, where the models excessively utilize System 2-type, deliberate reasoning, leading to inefficient token generation. Furthermore, these models face challenges in adapting their reasoning capabilities to rapidly changing environments due to the static nature of their pretraining data. To address these issues, advancing Large Language Models (LLMs) for complex reasoning tasks requires innovative approaches that bridge intuitive and deliberate cognitive processes, akin to human cognition's dual-system dynamic. This paper introduces a Multi-Agent System for Deep ReSearch (MARS) enabling seamless integration of System 1's fast, intuitive thinking with System 2's deliberate reasoning within LLMs. MARS strategically integrates multiple external tools, such as Google Search, Google Scholar, and Python Interpreter, to access up-to-date information and execute complex computations, while creating a specialized division of labor where System 1 efficiently processes and summarizes high-volume external information, providing distilled insights that expand System 2's reasoning context without overwhelming its capacity. Furthermore, we propose a multi-agent reinforcement learning framework extending Group Relative Policy Optimization to simultaneously optimize both systems with multi-turn tool interactions, bin-packing optimization, and sample balancing strategies that enhance collaborative efficiency. Extensive experiments demonstrate MARS achieves substantial improvements of 3.86% on the challenging Humanity's Last Exam (HLE) benchmark and an average gain of 8.9% across 7 knowledge-intensive tasks, validating the effectiveness of our dual-system paradigm for complex reasoning in dynamic information environments.
WebResearcher: Unleashing unbounded reasoning capability in Long-Horizon Agents
Sep 16, 2025



Recent advances in deep-research systems have demonstrated the potential for AI agents to autonomously discover and synthesize knowledge from external sources. In this paper, we introduce WebResearcher, a novel framework for building such agents through two key components: (1) WebResearcher, an iterative deep-research paradigm that reformulates deep research as a Markov Decision Process, where agents periodically consolidate findings into evolving reports while maintaining focused workspaces, overcoming the context suffocation and noise contamination that plague existing mono-contextual approaches; and (2) WebFrontier, a scalable data synthesis engine that generates high-quality training data through tool-augmented complexity escalation, enabling systematic creation of research tasks that bridge the gap between passive knowledge recall and active knowledge construction. Notably, we find that the training data from our paradigm significantly enhances tool-use capabilities even for traditional mono-contextual methods. Furthermore, our paradigm naturally scales through parallel thinking, enabling concurrent multi-agent exploration for more comprehensive conclusions. Extensive experiments across 6 challenging benchmarks demonstrate that WebResearcher achieves state-of-the-art performance, even surpassing frontier proprietary systems.
Efficient and Adaptive Simultaneous Speech Translation with Fully Unidirectional Architecture
Apr 16, 2025



Simultaneous speech translation (SimulST) produces translations incrementally while processing partial speech input. Although large language models (LLMs) have showcased strong capabilities in offline translation tasks, applying them to SimulST poses notable challenges. Existing LLM-based SimulST approaches either incur significant computational overhead due to repeated encoding of bidirectional speech encoder, or they depend on a fixed read/write policy, limiting the efficiency and performance. In this work, we introduce Efficient and Adaptive Simultaneous Speech Translation (EASiST) with fully unidirectional architecture, including both speech encoder and LLM. EASiST includes a multi-latency data curation strategy to generate semantically aligned SimulST training samples and redefines SimulST as an interleaved generation task with explicit read/write tokens. To facilitate adaptive inference, we incorporate a lightweight policy head that dynamically predicts read/write actions. Additionally, we employ a multi-stage training strategy to align speech-text modalities and optimize both translation and policy behavior. Experiments on the MuST-C En$\rightarrow$De and En$\rightarrow$Es datasets demonstrate that EASiST offers superior latency-quality trade-offs compared to several strong baselines.
Self-Modifying State Modeling for Simultaneous Machine Translation
Jun 04, 2024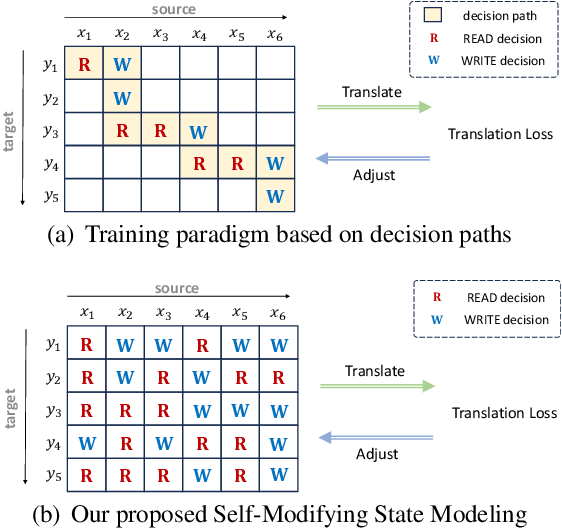


Simultaneous Machine Translation (SiMT) generates target outputs while receiving stream source inputs and requires a read/write policy to decide whether to wait for the next source token or generate a new target token, whose decisions form a \textit{decision path}. Existing SiMT methods, which learn the policy by exploring various decision paths in training, face inherent limitations. These methods not only fail to precisely optimize the policy due to the inability to accurately assess the individual impact of each decision on SiMT performance, but also cannot sufficiently explore all potential paths because of their vast number. Besides, building decision paths requires unidirectional encoders to simulate streaming source inputs, which impairs the translation quality of SiMT models. To solve these issues, we propose \textbf{S}elf-\textbf{M}odifying \textbf{S}tate \textbf{M}odeling (SM$^2$), a novel training paradigm for SiMT task. Without building decision paths, SM$^2$ individually optimizes decisions at each state during training. To precisely optimize the policy, SM$^2$ introduces Self-Modifying process to independently assess and adjust decisions at each state. For sufficient exploration, SM$^2$ proposes Prefix Sampling to efficiently traverse all potential states. Moreover, SM$^2$ ensures compatibility with bidirectional encoders, thus achieving higher translation quality. Experiments show that SM$^2$ outperforms strong baselines. Furthermore, SM$^2$ allows offline machine translation models to acquire SiMT ability with fine-tuning.