 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePARL: Position-Aware Relation Learning Network for Document Layout Analysis
Jan 12, 2026Document layout analysis aims to detect and categorize structural elements (e.g., titles, tables, figures) in scanned or digital documents. Popular methods often rely on high-quality Optical Character Recognition (OCR) to merge visual features with extracted text. This dependency introduces two major drawbacks: propagation of text recognition errors and substantial computational overhead, limiting the robustness and practical applicability of multimodal approaches. In contrast to the prevailing multimodal trend, we argue that effective layout analysis depends not on text-visual fusion, but on a deep understanding of documents' intrinsic visual structure. To this end, we propose PARL (Position-Aware Relation Learning Network), a novel OCR-free, vision-only framework that models layout through positional sensitivity and relational structure. Specifically, we first introduce a Bidirectional Spatial Position-Guided Deformable Attention module to embed explicit positional dependencies among layout elements directly into visual features. Second, we design a Graph Refinement Classifier (GRC) to refine predictions by modeling contextual relationships through a dynamically constructed layout graph. Extensive experiments show PARL achieves state-of-the-art results. It establishes a new benchmark for vision-only methods on DocLayNet and, notably, surpasses even strong multimodal models on M6Doc. Crucially, PARL (65M) is highly efficient, using roughly four times fewer parameters than large multimodal models (256M), demonstrating that sophisticated visual structure modeling can be both more efficient and robust than multimodal fusion.
FocalOrder: Focal Preference Optimization for Reading Order Detection
Jan 12, 2026Reading order detection is the foundation of document understanding. Most existing methods rely on uniform supervision, implicitly assuming a constant difficulty distribution across layout regions. In this work, we challenge this assumption by revealing a critical flaw: \textbf{Positional Disparity}, a phenomenon where models demonstrate mastery over the deterministic start and end regions but suffer a performance collapse in the complex intermediate sections. This degradation arises because standard training allows the massive volume of easy patterns to drown out the learning signals from difficult layouts. To address this, we propose \textbf{FocalOrder}, a framework driven by \textbf{Focal Preference Optimization (FPO)}. Specifically, FocalOrder employs adaptive difficulty discovery with exponential moving average mechanism to dynamically pinpoint hard-to-learn transitions, while introducing a difficulty-calibrated pairwise ranking objective to enforce global logical consistency. Extensive experiments demonstrate that FocalOrder establishes new state-of-the-art results on OmniDocBench v1.0 and Comp-HRDoc. Our compact model not only outperforms competitive specialized baselines but also significantly surpasses large-scale general VLMs. These results demonstrate that aligning the optimization with intrinsic structural ambiguity of documents is critical for mastering complex document structures.
Self-Modifying State Modeling for Simultaneous Machine Translation
Jun 04, 2024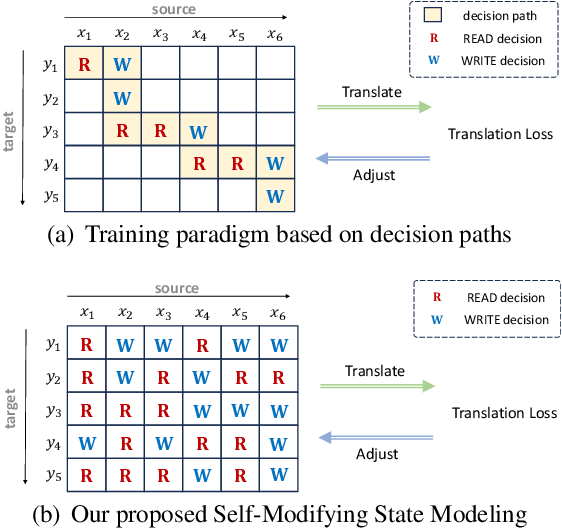


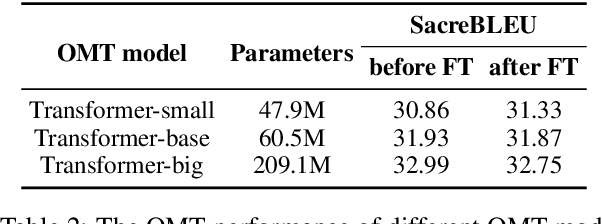
Simultaneous Machine Translation (SiMT) generates target outputs while receiving stream source inputs and requires a read/write policy to decide whether to wait for the next source token or generate a new target token, whose decisions form a \textit{decision path}. Existing SiMT methods, which learn the policy by exploring various decision paths in training, face inherent limitations. These methods not only fail to precisely optimize the policy due to the inability to accurately assess the individual impact of each decision on SiMT performance, but also cannot sufficiently explore all potential paths because of their vast number. Besides, building decision paths requires unidirectional encoders to simulate streaming source inputs, which impairs the translation quality of SiMT models. To solve these issues, we propose \textbf{S}elf-\textbf{M}odifying \textbf{S}tate \textbf{M}odeling (SM$^2$), a novel training paradigm for SiMT task. Without building decision paths, SM$^2$ individually optimizes decisions at each state during training. To precisely optimize the policy, SM$^2$ introduces Self-Modifying process to independently assess and adjust decisions at each state. For sufficient exploration, SM$^2$ proposes Prefix Sampling to efficiently traverse all potential states. Moreover, SM$^2$ ensures compatibility with bidirectional encoders, thus achieving higher translation quality. Experiments show that SM$^2$ outperforms strong baselines. Furthermore, SM$^2$ allows offline machine translation models to acquire SiMT ability with fine-tuning.
Dynamic Context Selection for Document-level Neural Machine Translation via Reinforcement Learning
Oct 09, 2020
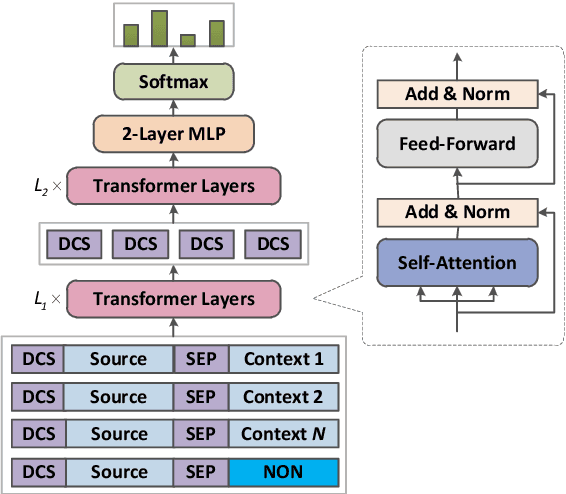


Document-level neural machine translation has yielded attractive improvements. However, majority of existing methods roughly use all context sentences in a fixed scope. They neglect the fact that different source sentences need different sizes of context. To address this problem, we propose an effective approach to select dynamic context so that the document-level translation model can utilize the more useful selected context sentences to produce better translations. Specifically, we introduce a selection module that is independent of the translation module to score each candidate context sentence. Then, we propose two strategies to explicitly select a variable number of context sentences and feed them into the translation module. We train the two modules end-to-end via reinforcement learning. A novel reward is proposed to encourage the selection and utilization of dynamic context sentences. Experiments demonstrate that our approach can select adaptive context sentences for different source sentences, and significantly improves the performance of document-level translation methods.