 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR2GenGPT: Radiology Report Generation with Frozen LLMs
Paper and Code
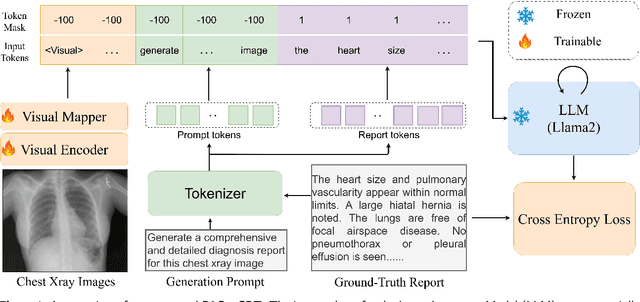
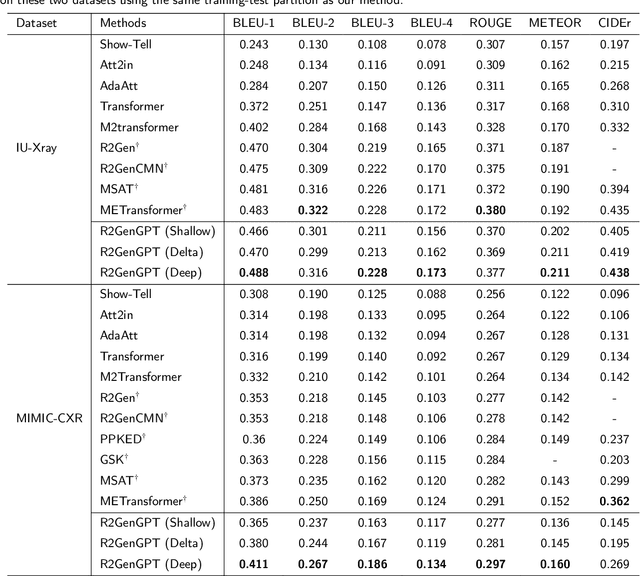
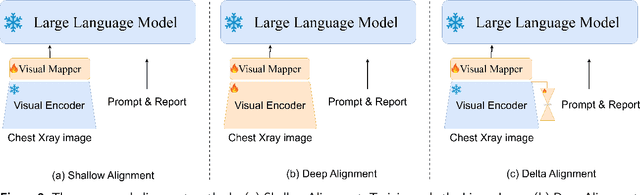
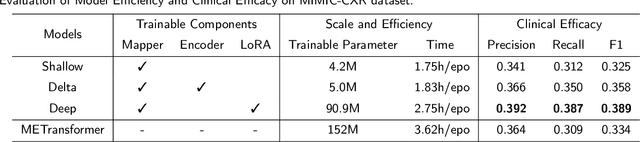
Large Language Models (LLMs) have consistently showcased remarkable generalization capabilities when applied to various language tasks. Nonetheless, harnessing the full potential of LLMs for Radiology Report Generation (R2Gen) still presents a challenge, stemming from the inherent disparity in modality between LLMs and the R2Gen task. To bridge this gap effectively, we propose R2GenGPT, which is a novel solution that aligns visual features with the word embedding space of LLMs using an efficient visual alignment module. This innovative approach empowers the previously static LLM to seamlessly integrate and process image information, marking a step forward in optimizing R2Gen performance. R2GenGPT offers the following benefits. First, it attains state-of-the-art (SOTA) performance by training only the lightweight visual alignment module while freezing all the parameters of LLM. Second, it exhibits high training efficiency, as it requires the training of an exceptionally minimal number of parameters while achieving rapid convergence. By employing delta tuning, our model only trains 5M parameters (which constitute just 0.07\% of the total parameter count) to achieve performance close to the SOTA levels. Our code is available at https://github.com/wang-zhanyu/R2GenGPT.