 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtreme Zero-Shot Learning for Extreme Text Classification
Paper and Code
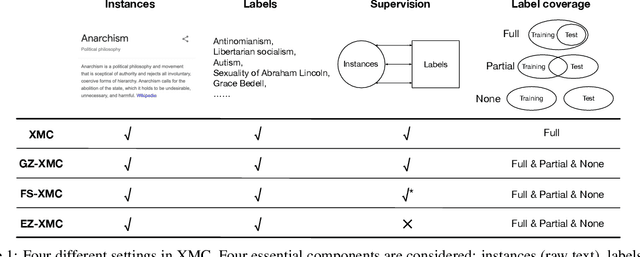
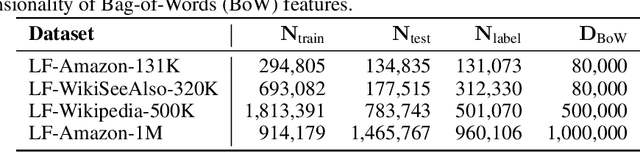
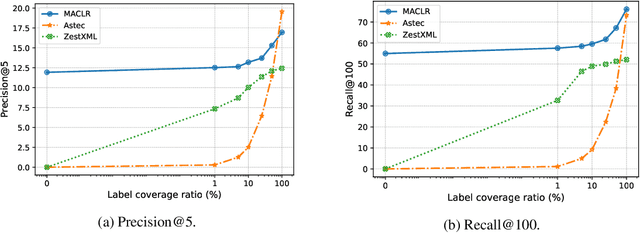
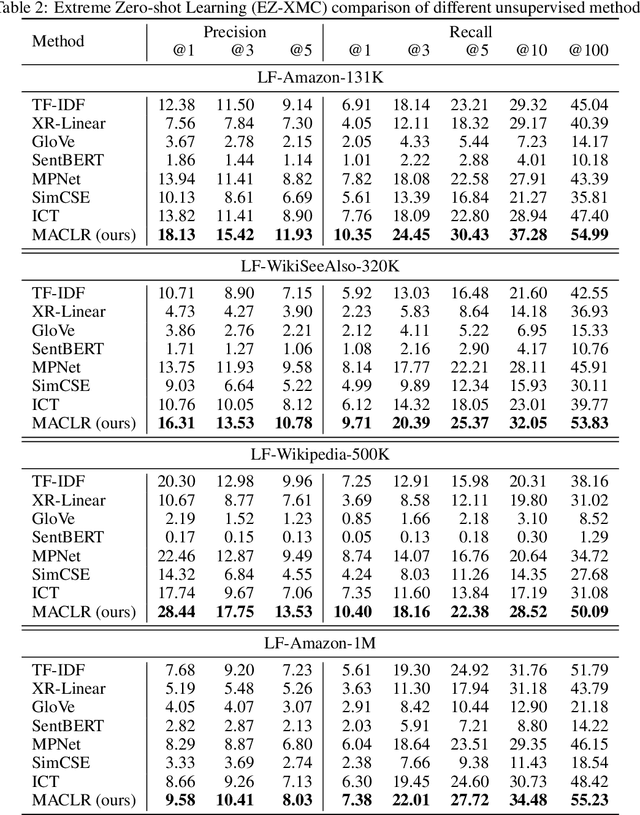
The eXtreme Multi-label text Classification (XMC) problem concerns finding most relevant labels for an input text instance from a large label set. However, the XMC setup faces two challenges: (1) it is not generalizable to predict unseen labels in dynamic environments, and (2) it requires a large amount of supervised (instance, label) pairs, which can be difficult to obtain for emerging domains. Recently, the generalized zero-shot XMC (GZ-XMC) setup has been studied and ZestXML is proposed accordingly to handle the unseen labels, which still requires a large number of annotated (instance, label) pairs. In this paper, we consider a more practical scenario called Extreme Zero-Shot XMC (EZ-XMC), in which no supervision is needed and merely raw text of instances and labels are accessible. Few-Shot XMC (FS-XMC), an extension to EZ-XMC with limited supervision is also investigated. To learn the semantic embeddings of instances and labels with raw text, we propose to pre-train Transformer-based encoders with self-supervised contrastive losses. Specifically, we develop a pre-training method MACLR, which thoroughly leverages the raw text with techniques including Multi-scale Adaptive Clustering, Label Regularization, and self-training with pseudo positive pairs. Experimental results on four public EZ-XMC datasets demonstrate that MACLR achieves superior performance compared to all other leading baseline methods, in particular with approximately 5-10% improvement in precision and recall on average. Moreover, we also show that our pre-trained encoder can be further improved on FS-XMC when there are a limited number of ground-truth positive pairs in training. By fine-tuning the encoder on such a few-shot subset, MACLR still outperforms other extreme classifiers significantly.