 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Robust and Efficient Multi-Agent Reinforcement Learning Framework for Traffic Signal Control
Mar 12, 2026Reinforcement Learning (RL) in Traffic Signal Control (TSC) faces significant hurdles in real-world deployment due to limited generalization to dynamic traffic flow variations. Existing approaches often overfit static patterns and use action spaces incompatible with driver expectations. This paper proposes a robust Multi-Agent Reinforcement Learning (MARL) framework validated in the Vissim traffic simulator. The framework integrates three mechanisms: (1) Turning Ratio Randomization, a training strategy that exposes agents to dynamic turning probabilities to enhance robustness against unseen scenarios; (2) a stability-oriented Exponential Phase Duration Adjustment action space, which balances responsiveness and precision through cyclical, exponential phase adjustments; and (3) a Neighbor-Based Observation scheme utilizing the MAPPO algorithm with Centralized Training with Decentralized Execution (CTDE). By leveraging centralized updates, this approach approximates the efficacy of global observations while maintaining scalable local communication. Experimental results demonstrate that our framework outperforms standard RL baselines, reducing average waiting time by over 10%. The proposed model exhibits superior generalization in unseen traffic scenarios and maintains high control stability, offering a practical solution for adaptive signal control.
Monte Carlo Tree Search in the Presence of Transition Uncertainty
Dec 18, 2023Monte Carlo Tree Search (MCTS) is an immensely popular search-based framework used for decision making. It is traditionally applied to domains where a perfect simulation model of the environment is available. We study and improve MCTS in the context where the environment model is given but imperfect. We show that the discrepancy between the model and the actual environment can lead to significant performance degradation with standard MCTS. We therefore develop Uncertainty Adapted MCTS (UA-MCTS), a more robust algorithm within the MCTS framework. We estimate the transition uncertainty in the given model, and direct the search towards more certain transitions in the state space. We modify all four MCTS phases to improve the search behavior by considering these estimates. We prove, in the corrupted bandit case, that adding uncertainty information to adapt UCB leads to tighter regret bound than standard UCB. Empirically, we evaluate UA-MCTS and its individual components on the deterministic domains from the MinAtar test suite. Our results demonstrate that UA-MCTS strongly improves MCTS in the presence of model transition errors.
Sim-To-Real Transfer for Miniature Autonomous Car Racing
Nov 11, 2020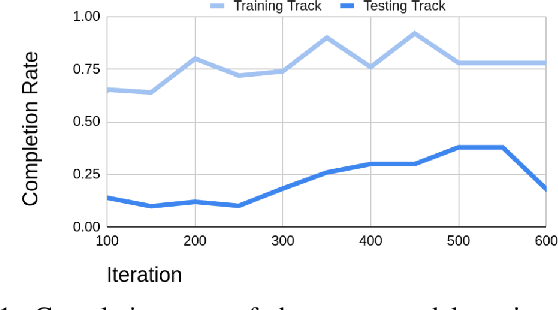
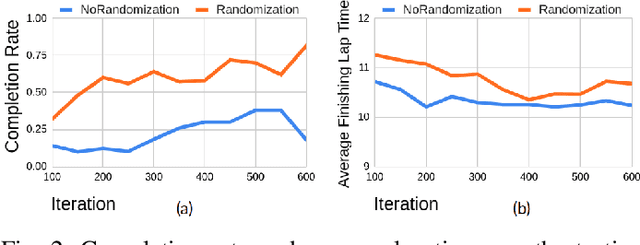
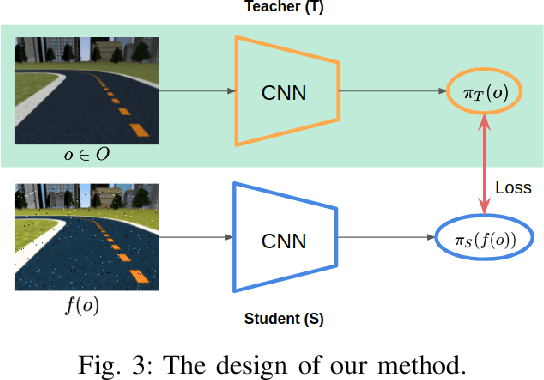
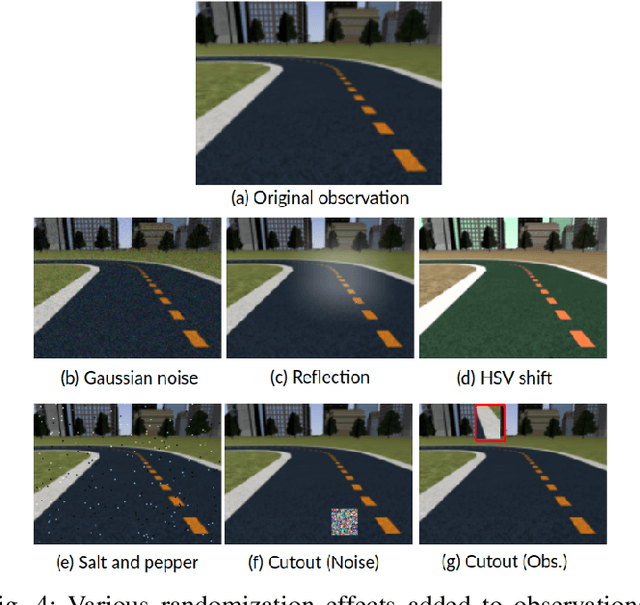
Sim-to-real, a term that describes where a model is trained in a simulator then transferred to the real world, is a technique that enables faster deep reinforcement learning (DRL) training. However, differences between the simulator and the real world often cause the model to perform poorly in the real world. Domain randomization is a way to bridge the sim-to-real gap by exposing the model to a wide range of scenarios so that it can generalize to real-world situations. However, following domain randomization to train an autonomous car racing model with DRL can lead to undesirable outcomes. Namely, a model trained with randomization tends to run slower; a higher completion rate on the testing track comes at the expense of longer lap times. This paper aims to boost the robustness of a trained race car model without compromising racing lap times. For a training track and a testing track having the same shape (and same optimal paths), but with different lighting, background, etc., we first train a model (teacher model) that overfits the training track, moving along a near optimal path. We then use this model to teach a student model the correct actions along with randomization. With our method, a model with 18.4\% completion rate on the testing track is able to help teach a student model with 52\% completion. Moreover, over an average of 50 trials, the student is able to finish a lap 0.23 seconds faster than the teacher. This 0.23 second gap is significant in tight races, with lap times of about 10 to 12 seconds.
Accelerating and Improving AlphaZero Using Population Based Training
Mar 13, 2020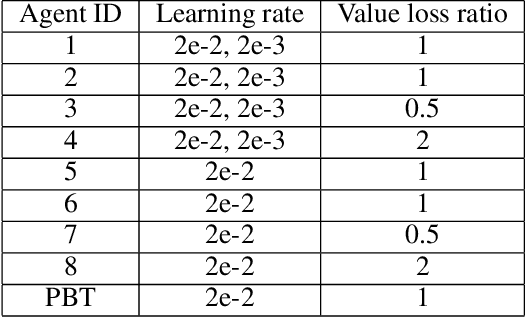
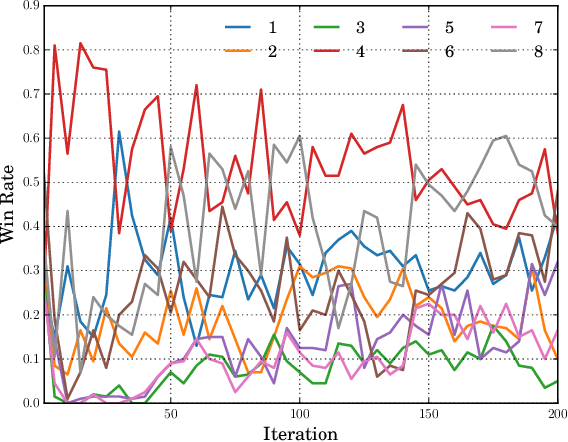
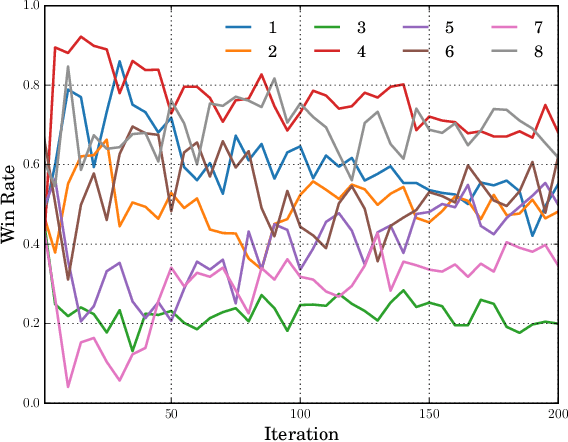
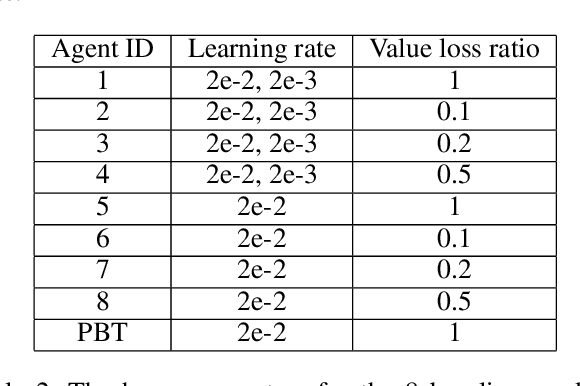
AlphaZero has been very successful in many games. Unfortunately, it still consumes a huge amount of computing resources, the majority of which is spent in self-play. Hyperparameter tuning exacerbates the training cost since each hyperparameter configuration requires its own time to train one run, during which it will generate its own self-play records. As a result, multiple runs are usually needed for different hyperparameter configurations. This paper proposes using population based training (PBT) to help tune hyperparameters dynamically and improve strength during training time. Another significant advantage is that this method requires a single run only, while incurring a small additional time cost, since the time for generating self-play records remains unchanged though the time for optimization is increased following the AlphaZero training algorithm. In our experiments for 9x9 Go, the PBT method is able to achieve a higher win rate for 9x9 Go than the baselines, each with its own hyperparameter configuration and trained individually. For 19x19 Go, with PBT, we are able to obtain improvements in playing strength. Specifically, the PBT agent can obtain up to 74% win rate against ELF OpenGo, an open-source state-of-the-art AlphaZero program using a neural network of a comparable capacity. This is compared to a saturated non-PBT agent, which achieves a win rate of 47% against ELF OpenGo under the same circumstances.
Multiple Policy Value Monte Carlo Tree Search
May 31, 2019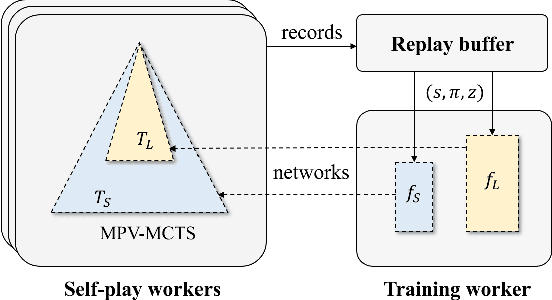
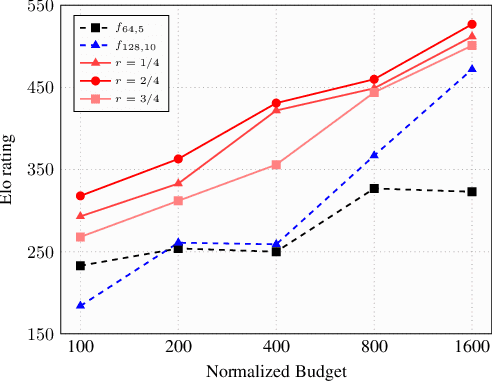
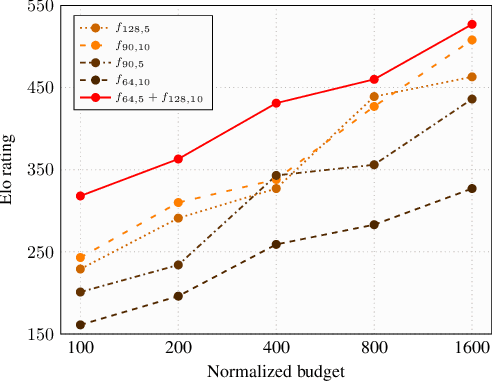
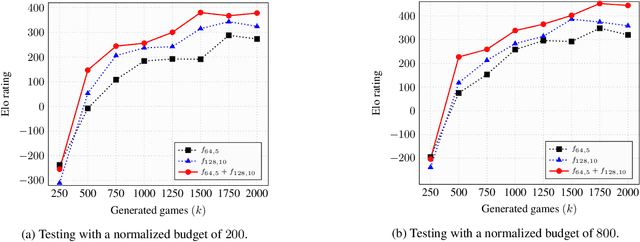
Many of the strongest game playing programs use a combination of Monte Carlo tree search (MCTS) and deep neural networks (DNN), where the DNNs are used as policy or value evaluators. Given a limited budget, such as online playing or during the self-play phase of AlphaZero (AZ) training, a balance needs to be reached between accurate state estimation and more MCTS simulations, both of which are critical for a strong game playing agent. Typically, larger DNNs are better at generalization and accurate evaluation, while smaller DNNs are less costly, and therefore can lead to more MCTS simulations and bigger search trees with the same budget. This paper introduces a new method called the multiple policy value MCTS (MPV-MCTS), which combines multiple policy value neural networks (PV-NNs) of various sizes to retain advantages of each network, where two PV-NNs f_S and f_L are used in this paper. We show through experiments on the game NoGo that a combined f_S and f_L MPV-MCTS outperforms single PV-NN with policy value MCTS, called PV-MCTS. Additionally, MPV-MCTS also outperforms PV-MCTS for AZ training.
Human vs. Computer Go: Review and Prospect
Jun 07, 2016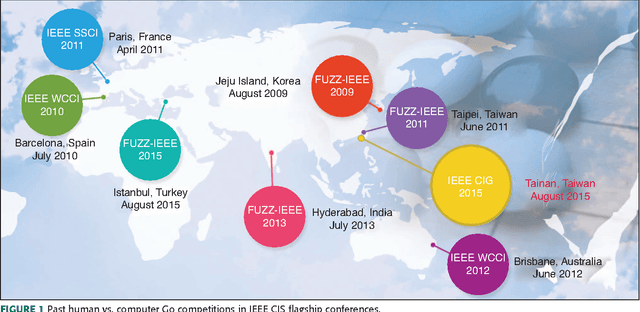
The Google DeepMind challenge match in March 2016 was a historic achievement for computer Go development. This article discusses the development of computational intelligence (CI) and its relative strength in comparison with human intelligence for the game of Go. We first summarize the milestones achieved for computer Go from 1998 to 2016. Then, the computer Go programs that have participated in previous IEEE CIS competitions as well as methods and techniques used in AlphaGo are briefly introduced. Commentaries from three high-level professional Go players on the five AlphaGo versus Lee Sedol games are also included. We conclude that AlphaGo beating Lee Sedol is a huge achievement in artificial intelligence (AI) based largely on CI methods. In the future, powerful computer Go programs such as AlphaGo are expected to be instrumental in promoting Go education and AI real-world applications.