 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-Based Conditioning for Action Policy Smoothness in Autonomous Miniature Car Racing with Reinforcement Learning
May 19, 2022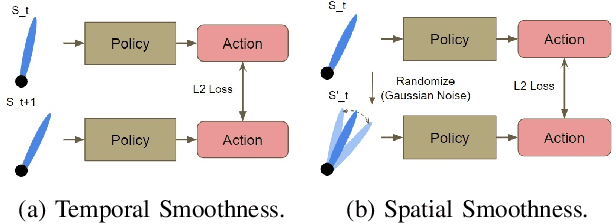


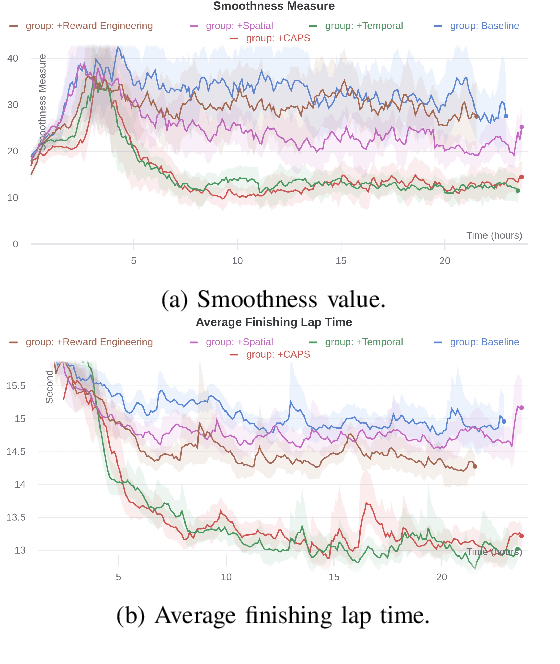
In recent years, deep reinforcement learning has achieved significant results in low-level controlling tasks. However, the problem of control smoothness has less attention. In autonomous driving, unstable control is inevitable since the vehicle might suddenly change its actions. This problem will lower the controlling system's efficiency, induces excessive mechanical wear, and causes uncontrollable, dangerous behavior to the vehicle. In this paper, we apply the Conditioning for Action Policy Smoothness (CAPS) with image-based input to smooth the control of an autonomous miniature car racing. Applying CAPS and sim-to-real transfer methods helps to stabilize the control at a higher speed. Especially, the agent with CAPS and CycleGAN reduces 21.80% of the average finishing lap time. Moreover, we also conduct extensive experiments to analyze the impact of CAPS components.
Sim-To-Real Transfer for Miniature Autonomous Car Racing
Nov 11, 2020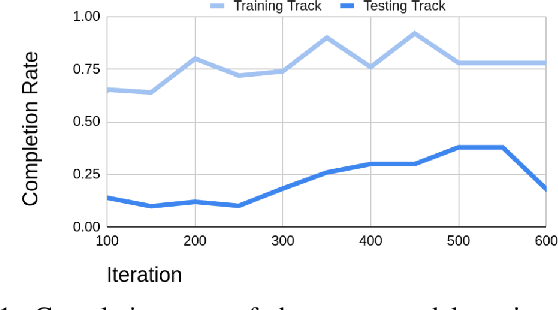
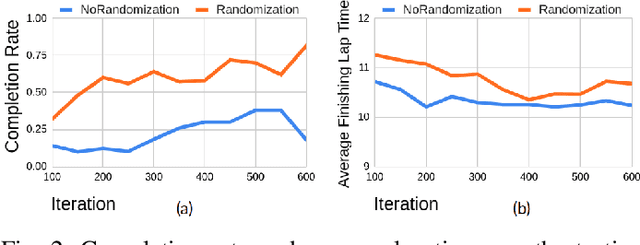
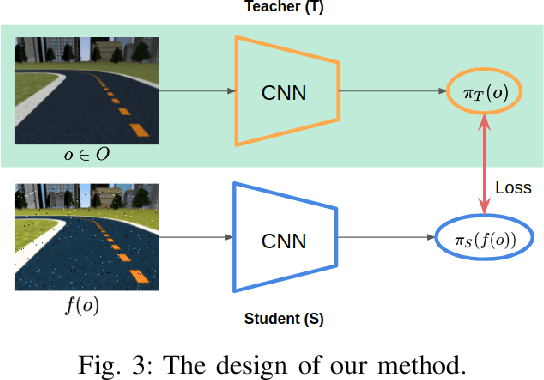
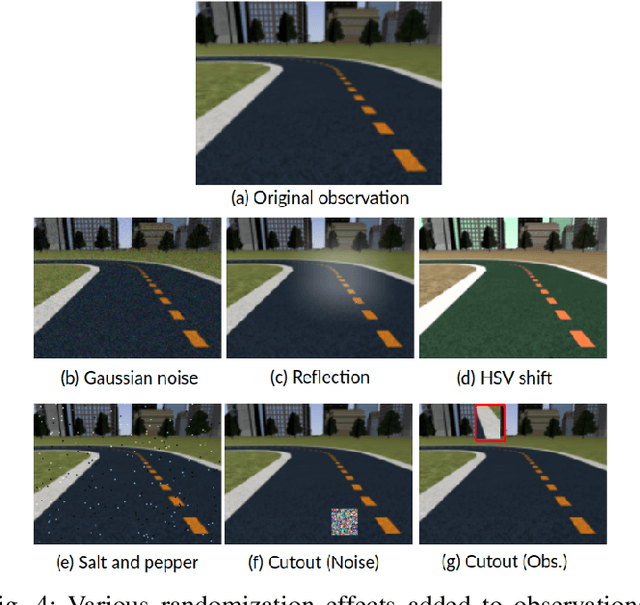
Sim-to-real, a term that describes where a model is trained in a simulator then transferred to the real world, is a technique that enables faster deep reinforcement learning (DRL) training. However, differences between the simulator and the real world often cause the model to perform poorly in the real world. Domain randomization is a way to bridge the sim-to-real gap by exposing the model to a wide range of scenarios so that it can generalize to real-world situations. However, following domain randomization to train an autonomous car racing model with DRL can lead to undesirable outcomes. Namely, a model trained with randomization tends to run slower; a higher completion rate on the testing track comes at the expense of longer lap times. This paper aims to boost the robustness of a trained race car model without compromising racing lap times. For a training track and a testing track having the same shape (and same optimal paths), but with different lighting, background, etc., we first train a model (teacher model) that overfits the training track, moving along a near optimal path. We then use this model to teach a student model the correct actions along with randomization. With our method, a model with 18.4\% completion rate on the testing track is able to help teach a student model with 52\% completion. Moreover, over an average of 50 trials, the student is able to finish a lap 0.23 seconds faster than the teacher. This 0.23 second gap is significant in tight races, with lap times of about 10 to 12 seconds.