 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-based Regularization for Action Smoothness in Robotic Control with Reinforcement Learning
Jul 05, 2024

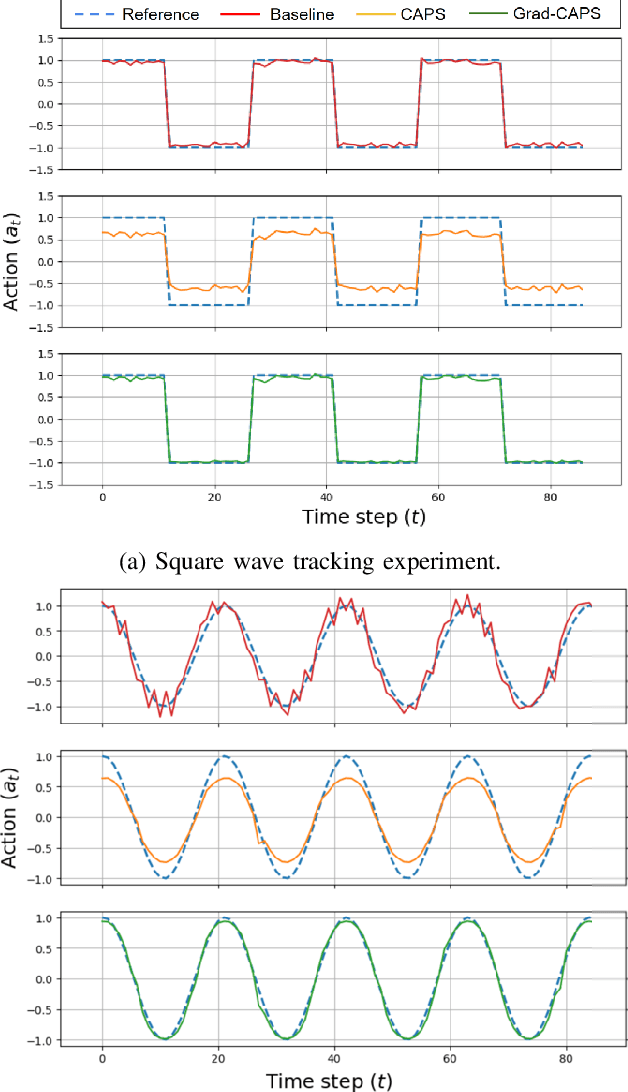
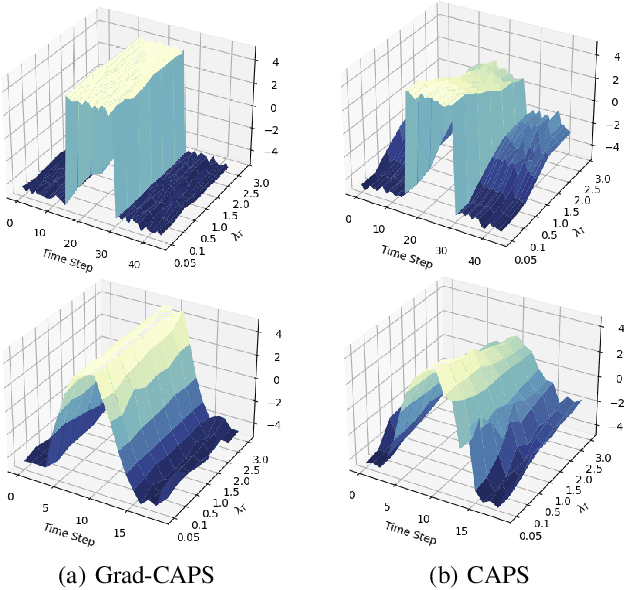
Deep Reinforcement Learning (DRL) has achieved remarkable success, ranging from complex computer games to real-world applications, showing the potential for intelligent agents capable of learning in dynamic environments. However, its application in real-world scenarios presents challenges, including the jerky problem, in which jerky trajectories not only compromise system safety but also increase power consumption and shorten the service life of robotic and autonomous systems. To address jerky actions, a method called conditioning for action policy smoothness (CAPS) was proposed by adding regularization terms to reduce the action changes. This paper further proposes a novel method, named Gradient-based CAPS (Grad-CAPS), that modifies CAPS by reducing the difference in the gradient of action and then uses displacement normalization to enable the agent to adapt to invariant action scales. Consequently, our method effectively reduces zigzagging action sequences while enhancing policy expressiveness and the adaptability of our method across diverse scenarios and environments. In the experiments, we integrated Grad-CAPS with different reinforcement learning algorithms and evaluated its performance on various robotic-related tasks in DeepMind Control Suite and OpenAI Gym environments. The results demonstrate that Grad-CAPS effectively improves performance while maintaining a comparable level of smoothness compared to CAPS and Vanilla agents.
Image-based Regularization for Action Smoothness in Autonomous Miniature Racing Car with Deep Reinforcement Learning
Jul 17, 2023



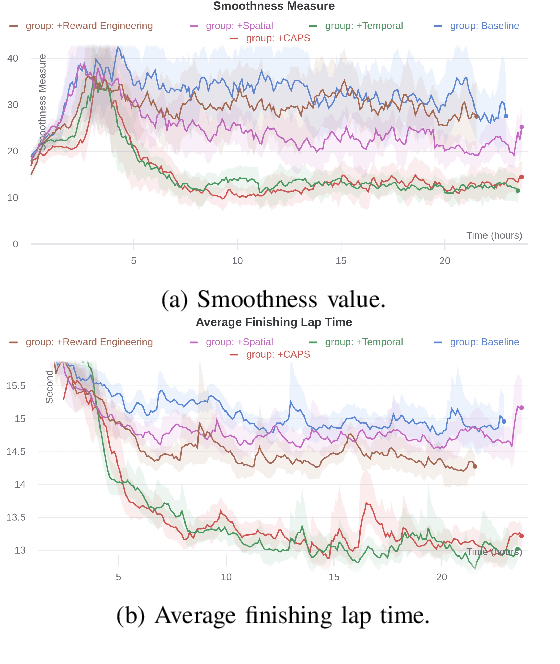
Deep reinforcement learning has achieved significant results in low-level controlling tasks. However, for some applications like autonomous driving and drone flying, it is difficult to control behavior stably since the agent may suddenly change its actions which often lowers the controlling system's efficiency, induces excessive mechanical wear, and causes uncontrollable, dangerous behavior to the vehicle. Recently, a method called conditioning for action policy smoothness (CAPS) was proposed to solve the problem of jerkiness in low-dimensional features for applications such as quadrotor drones. To cope with high-dimensional features, this paper proposes image-based regularization for action smoothness (I-RAS) for solving jerky control in autonomous miniature car racing. We also introduce a control based on impact ratio, an adaptive regularization weight to control the smoothness constraint, called IR control. In the experiment, an agent with I-RAS and IR control significantly improves the success rate from 59% to 95%. In the real-world-track experiment, the agent also outperforms other methods, namely reducing the average finish lap time, while also improving the completion rate even without real world training. This is also justified by an agent based on I-RAS winning the 2022 AWS DeepRacer Final Championship Cup.
Image-Based Conditioning for Action Policy Smoothness in Autonomous Miniature Car Racing with Reinforcement Learning
May 19, 2022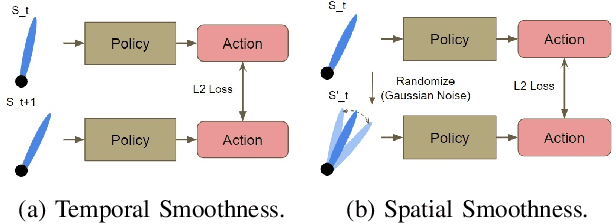


In recent years, deep reinforcement learning has achieved significant results in low-level controlling tasks. However, the problem of control smoothness has less attention. In autonomous driving, unstable control is inevitable since the vehicle might suddenly change its actions. This problem will lower the controlling system's efficiency, induces excessive mechanical wear, and causes uncontrollable, dangerous behavior to the vehicle. In this paper, we apply the Conditioning for Action Policy Smoothness (CAPS) with image-based input to smooth the control of an autonomous miniature car racing. Applying CAPS and sim-to-real transfer methods helps to stabilize the control at a higher speed. Especially, the agent with CAPS and CycleGAN reduces 21.80% of the average finishing lap time. Moreover, we also conduct extensive experiments to analyze the impact of CAPS components.