 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrankenstein Optimizer: Harnessing the Potential by Revisiting Optimization Tricks
Mar 04, 2025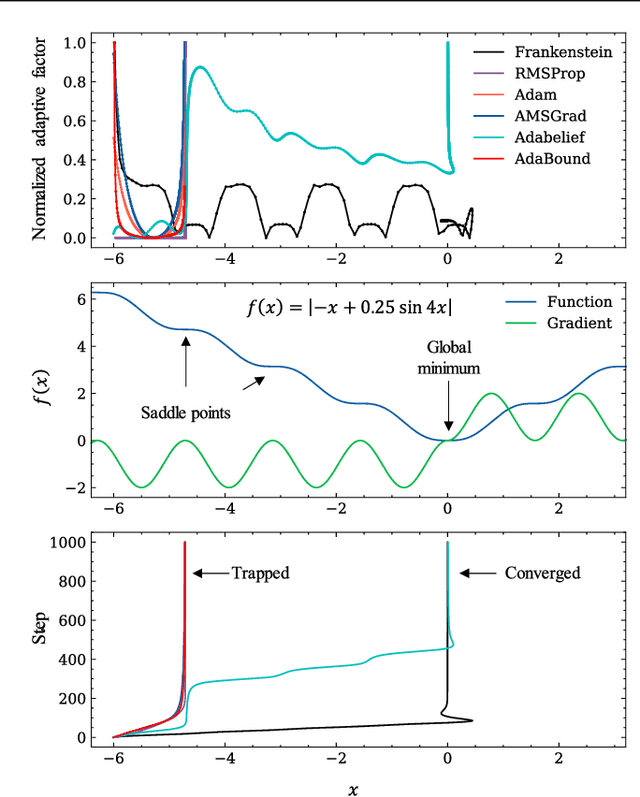
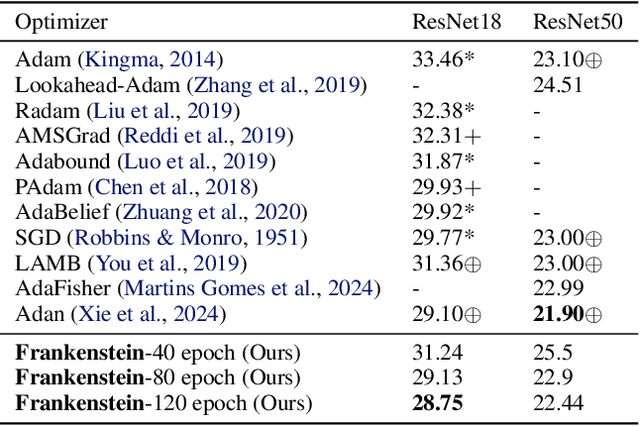
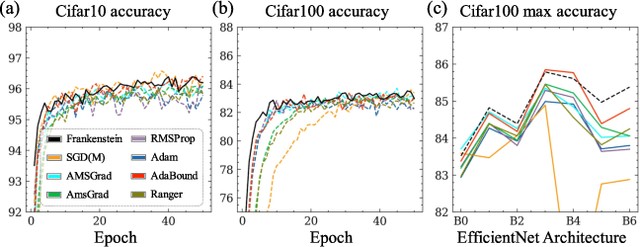
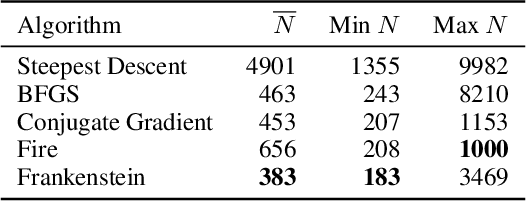
Gradient-based optimization drives the unprecedented performance of modern deep neural network models across diverse applications. Adaptive algorithms have accelerated neural network training due to their rapid convergence rates; however, they struggle to find ``flat minima" reliably, resulting in suboptimal generalization compared to stochastic gradient descent (SGD). By revisiting various adaptive algorithms' mechanisms, we propose the Frankenstein optimizer, which combines their advantages. The proposed Frankenstein dynamically adjusts first- and second-momentum coefficients according to the optimizer's current state to directly maintain consistent learning dynamics and immediately reflect sudden gradient changes. Extensive experiments across several research domains such as computer vision, natural language processing, few-shot learning, and scientific simulations show that Frankenstein surpasses existing adaptive algorithms and SGD empirically regarding convergence speed and generalization performance. Furthermore, this research deepens our understanding of adaptive algorithms through centered kernel alignment analysis and loss landscape visualization during the learning process.