 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriching Physical-Virtual Interaction in AR Gaming by Tracking Identical Real Objects
Feb 24, 2025



Augmented reality (AR) games, particularly those designed for headsets, have become increasingly prevalent with advancements in both hardware and software. However, the majority of AR games still rely on pre-scanned or static scenes, and interaction mechanisms are often limited to controllers or hand-tracking. Additionally, the presence of identical objects in AR games poses challenges for conventional object tracking techniques, which often struggle to differentiate between identical objects or necessitate the installation of fixed cameras for global object movement tracking. In response to these limitations, we present a novel approach to address the tracking of identical objects in an AR scene to enrich physical-virtual interaction. Our method leverages partial scene observations captured by an AR headset, utilizing the perspective and spatial data provided by this technology. Object identities within the scene are determined through the solution of a label assignment problem using integer programming. To enhance computational efficiency, we incorporate a Voronoi diagram-based pruning method into our approach. Our implementation of this approach in a farm-to-table AR game demonstrates its satisfactory performance and robustness. Furthermore, we showcase the versatility and practicality of our method through applications in AR storytelling and a simulated gaming robot. Our video demo is available at: https://youtu.be/rPGkLYuKvCQ.
PEARL: Parallelized Expert-Assisted Reinforcement Learning for Scene Rearrangement Planning
May 10, 2021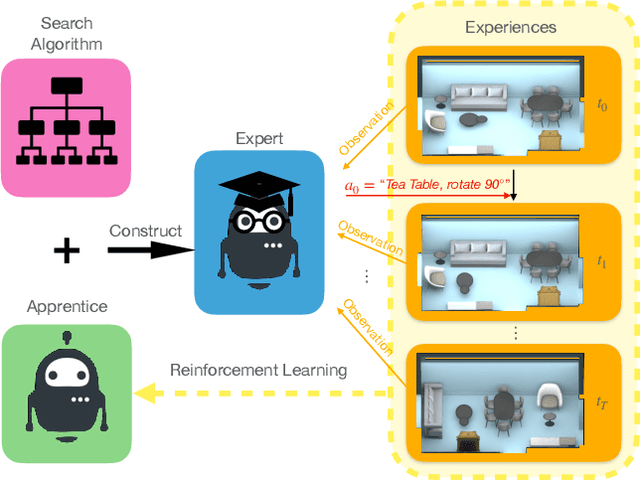

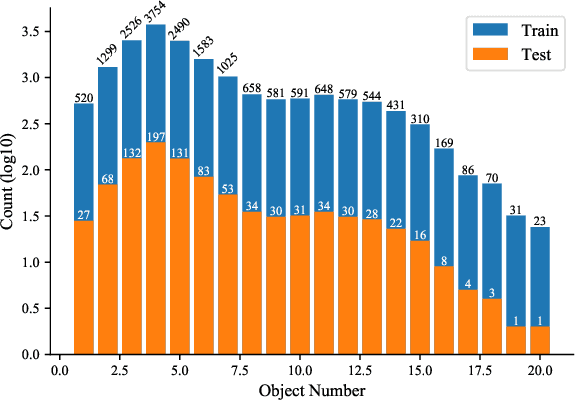
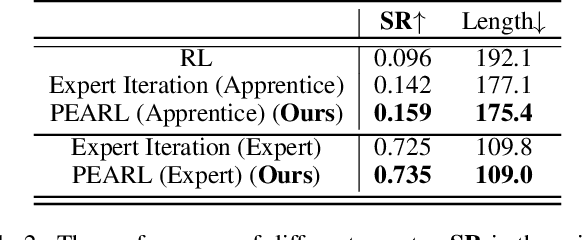
Scene Rearrangement Planning (SRP) is an interior task proposed recently. The previous work defines the action space of this task with handcrafted coarse-grained actions that are inflexible to be used for transforming scene arrangement and intractable to be deployed in practice. Additionally, this new task lacks realistic indoor scene rearrangement data to feed popular data-hungry learning approaches and meet the needs of quantitative evaluation. To address these problems, we propose a fine-grained action definition for SRP and introduce a large-scale scene rearrangement dataset. We also propose a novel learning paradigm to efficiently train an agent through self-playing, without any prior knowledge. The agent trained via our paradigm achieves superior performance on the introduced dataset compared to the baseline agents. We provide a detailed analysis of the design of our approach in our experiments.
Designing Human-Robot Coexistence Space
Nov 14, 2020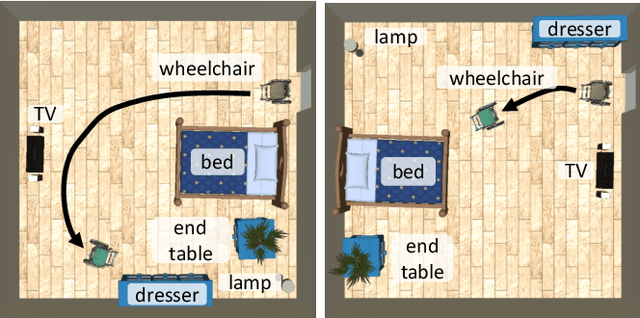
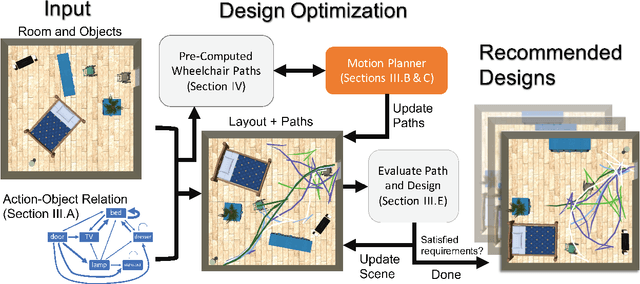

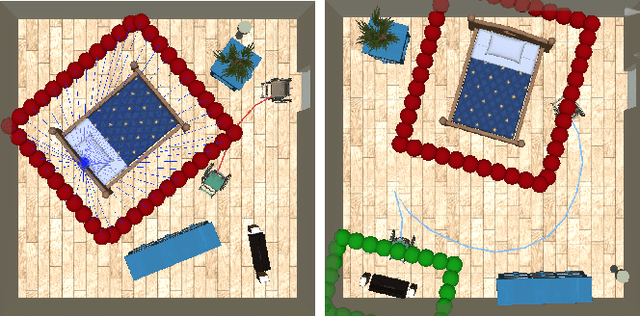
When the human-robot interactions become ubiquitous, the environment surrounding these interactions will have significant impact on the safety and comfort of the human and the effectiveness and efficiency of the robot. Although most robots are designed to work in the spaces created for humans, many environments, such as living rooms and offices, can be and should be redesigned to enhance and improve human-robot collaboration and interactions. This work uses autonomous wheelchair as an example and investigates the computational design in the human-robot coexistence spaces. Given the room size and the objects $O$ in the room, the proposed framework computes the optimal layouts of $O$ that satisfy both human preferences and navigation constraints of the wheelchair. The key enabling technique is a motion planner that can efficiently evaluate hundreds of similar motion planning problems. Our implementation shows that the proposed framework can produce a design around three to five minutes on average comparing to 10 to 20 minutes without the proposed motion planner. Our results also show that the proposed method produces reasonable designs even for tight spaces and for users with different preferences.
Configurable 3D Scene Synthesis and 2D Image Rendering with Per-Pixel Ground Truth using Stochastic Grammars
Jun 20, 2018
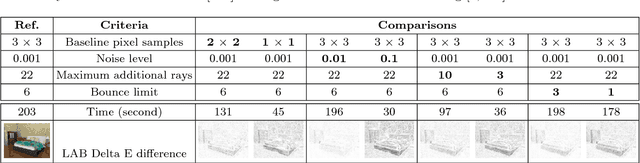
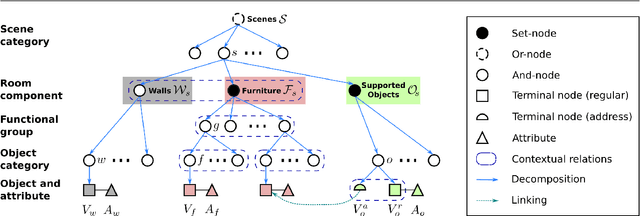
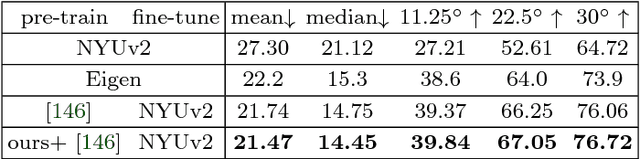
We propose a systematic learning-based approach to the generation of massive quantities of synthetic 3D scenes and arbitrary numbers of photorealistic 2D images thereof, with associated ground truth information, for the purposes of training, benchmarking, and diagnosing learning-based computer vision and robotics algorithms. In particular, we devise a learning-based pipeline of algorithms capable of automatically generating and rendering a potentially infinite variety of indoor scenes by using a stochastic grammar, represented as an attributed Spatial And-Or Graph, in conjunction with state-of-the-art physics-based rendering. Our pipeline is capable of synthesizing scene layouts with high diversity, and it is configurable inasmuch as it enables the precise customization and control of important attributes of the generated scenes. It renders photorealistic RGB images of the generated scenes while automatically synthesizing detailed, per-pixel ground truth data, including visible surface depth and normal, object identity, and material information (detailed to object parts), as well as environments (e.g., illuminations and camera viewpoints). We demonstrate the value of our synthesized dataset, by improving performance in certain machine-learning-based scene understanding tasks--depth and surface normal prediction, semantic segmentation, reconstruction, etc.--and by providing benchmarks for and diagnostics of trained models by modifying object attributes and scene properties in a controllable manner.
A Robust 3D-2D Interactive Tool for Scene Segmentation and Annotation
Oct 19, 2016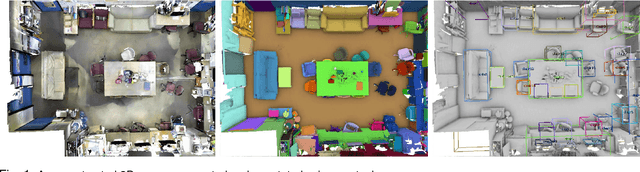
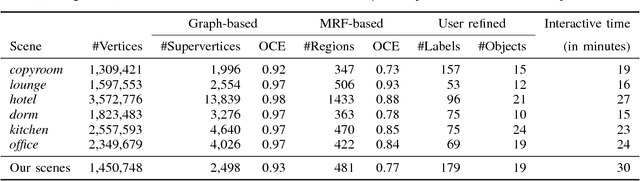
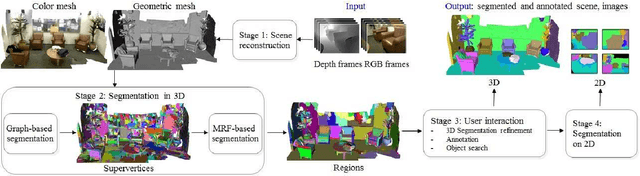
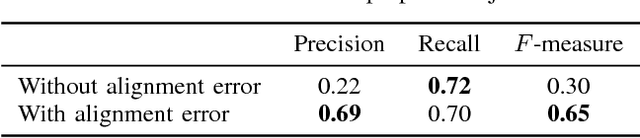
Recent advances of 3D acquisition devices have enabled large-scale acquisition of 3D scene data. Such data, if completely and well annotated, can serve as useful ingredients for a wide spectrum of computer vision and graphics works such as data-driven modeling and scene understanding, object detection and recognition. However, annotating a vast amount of 3D scene data remains challenging due to the lack of an effective tool and/or the complexity of 3D scenes (e.g. clutter, varying illumination conditions). This paper aims to build a robust annotation tool that effectively and conveniently enables the segmentation and annotation of massive 3D data. Our tool works by coupling 2D and 3D information via an interactive framework, through which users can provide high-level semantic annotation for objects. We have experimented our tool and found that a typical indoor scene could be well segmented and annotated in less than 30 minutes by using the tool, as opposed to a few hours if done manually. Along with the tool, we created a dataset of over a hundred 3D scenes associated with complete annotations using our tool. The tool and dataset are available at www.scenenn.net.