 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQVC+: One-Shot Voice Conversion by Vector Quantization and U-Net architecture
Paper and Code
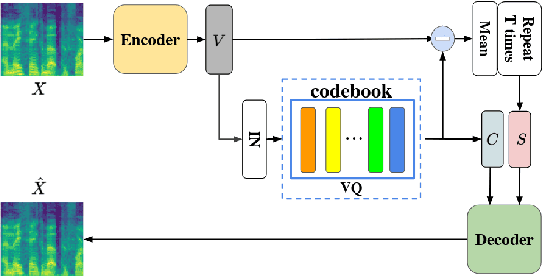
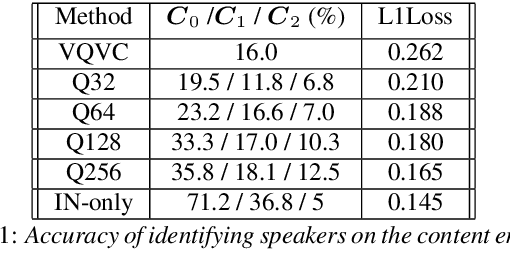
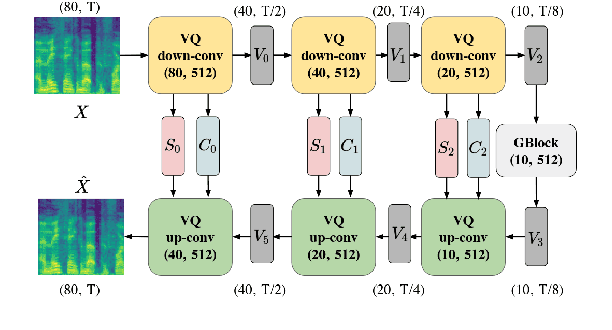
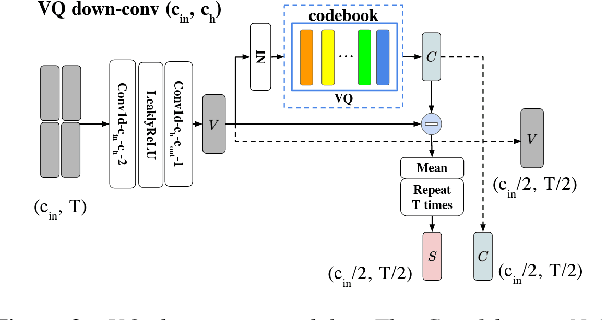
Voice conversion (VC) is a task that transforms the source speaker's timbre, accent, and tones in audio into another one's while preserving the linguistic content. It is still a challenging work, especially in a one-shot setting. Auto-encoder-based VC methods disentangle the speaker and the content in input speech without given the speaker's identity, so these methods can further generalize to unseen speakers. The disentangle capability is achieved by vector quantization (VQ), adversarial training, or instance normalization (IN). However, the imperfect disentanglement may harm the quality of output speech. In this work, to further improve audio quality, we use the U-Net architecture within an auto-encoder-based VC system. We find that to leverage the U-Net architecture, a strong information bottleneck is necessary. The VQ-based method, which quantizes the latent vectors, can serve the purpose. The objective and the subjective evaluations show that the proposed method performs well in both audio naturalness and speaker similarity.