 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Recent Deep Learning-driven Singing Voice Synthesis Systems
Oct 06, 2021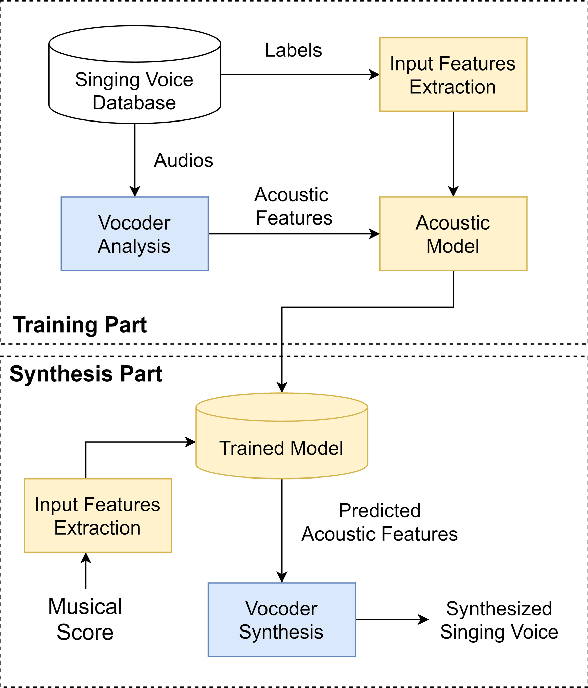
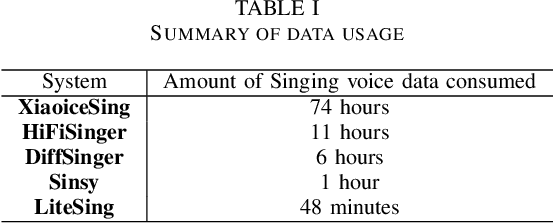
Singing voice synthesis (SVS) is a task that aims to generate audio signals according to musical scores and lyrics. With its multifaceted nature concerning music and language, producing singing voices indistinguishable from that of human singers has always remained an unfulfilled pursuit. Nonetheless, the advancements of deep learning techniques have brought about a substantial leap in the quality and naturalness of synthesized singing voice. This paper aims to review some of the state-of-the-art deep learning-driven SVS systems. We intend to summarize their deployed model architectures and identify the strengths and limitations for each of the introduced systems. Thereby, we picture the recent advancement trajectory of this field and conclude the challenges left to be resolved both in commercial applications and academic research.