 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generalizability to Tone and Content Variations in the Transcription of Amplifier Rendered Electric Guitar Audio
Apr 10, 2025Transcribing electric guitar recordings is challenging due to the scarcity of diverse datasets and the complex tone-related variations introduced by amplifiers, cabinets, and effect pedals. To address these issues, we introduce EGDB-PG, a novel dataset designed to capture a wide range of tone-related characteristics across various amplifier-cabinet configurations. In addition, we propose the Tone-informed Transformer (TIT), a Transformer-based transcription model enhanced with a tone embedding mechanism that leverages learned representations to improve the model's adaptability to tone-related nuances. Experiments demonstrate that TIT, trained on EGDB-PG, outperforms existing baselines across diverse amplifier types, with transcription accuracy improvements driven by the dataset's diversity and the tone embedding technique. Through detailed benchmarking and ablation studies, we evaluate the impact of tone augmentation, content augmentation, audio normalization, and tone embedding on transcription performance. This work advances electric guitar transcription by overcoming limitations in dataset diversity and tone modeling, providing a robust foundation for future research.
Demo of Zero-Shot Guitar Amplifier Modelling: Enhancing Modeling with Hyper Neural Networks
Oct 07, 2024
Electric guitar tone modeling typically focuses on the non-linear transformation from clean to amplifier-rendered audio. Traditional methods rely on one-to-one mappings, incorporating device parameters into neural models to replicate specific amplifiers. However, these methods are limited by the need for specific training data. In this paper, we adapt a model based on the previous work, which leverages a tone embedding encoder and a feature wise linear modulation (FiLM) condition method. In this work, we altered conditioning method using a hypernetwork-based gated convolutional network (GCN) to generate audio that blends clean input with the tone characteristics of reference audio. By extending the training data to cover a wider variety of amplifier tones, our model is able to capture a broader range of tones. Additionally, we developed a real-time plugin to demonstrate the system's practical application, allowing users to experience its performance interactively. Our results indicate that the proposed system achieves superior tone modeling versatility compared to traditional methods.
DDSP Guitar Amp: Interpretable Guitar Amplifier Modeling
Aug 21, 2024


Neural network models for guitar amplifier emulation, while being effective, often demand high computational cost and lack interpretability. Drawing ideas from physical amplifier design, this paper aims to address these issues with a new differentiable digital signal processing (DDSP)-based model, called ``DDSP guitar amp,'' that models the four components of a guitar amp (i.e., preamp, tone stack, power amp, and output transformer) using specific DSP-inspired designs. With a set of time- and frequency-domain metrics, we demonstrate that DDSP guitar amp achieves performance comparable with that of black-box baselines while requiring less than 10\% of the computational operations per audio sample, thereby holding greater potential for usages in real-time applications.
Distortion Recovery: A Two-Stage Method for Guitar Effect Removal
Jul 23, 2024

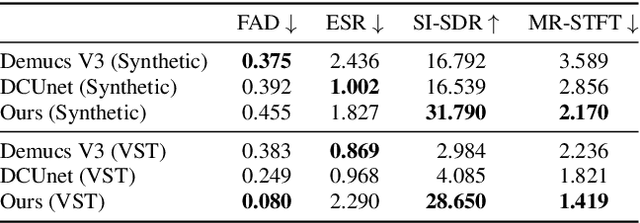

Removing audio effects from electric guitar recordings makes it easier for post-production and sound editing. An audio distortion recovery model not only improves the clarity of the guitar sounds but also opens up new opportunities for creative adjustments in mixing and mastering. While progress have been made in creating such models, previous efforts have largely focused on synthetic distortions that may be too simplistic to accurately capture the complexities seen in real-world recordings. In this paper, we tackle the task by using a dataset of guitar recordings rendered with commercial-grade audio effect VST plugins. Moreover, we introduce a novel two-stage methodology for audio distortion recovery. The idea is to firstly process the audio signal in the Mel-spectrogram domain in the first stage, and then use a neural vocoder to generate the pristine original guitar sound from the processed Mel-spectrogram in the second stage. We report a set of experiments demonstrating the effectiveness of our approach over existing methods, through both subjective and objective evaluation metrics.
Towards zero-shot amplifier modeling: One-to-many amplifier modeling via tone embedding control
Jul 15, 2024



Replicating analog device circuits through neural audio effect modeling has garnered increasing interest in recent years. Existing work has predominantly focused on a one-to-one emulation strategy, modeling specific devices individually. In this paper, we tackle the less-explored scenario of one-to-many emulation, utilizing conditioning mechanisms to emulate multiple guitar amplifiers through a single neural model. For condition representation, we use contrastive learning to build a tone embedding encoder that extracts style-related features of various amplifiers, leveraging a dataset of comprehensive amplifier settings. Targeting zero-shot application scenarios, we also examine various strategies for tone embedding representation, evaluating referenced tone embedding against two retrieval-based embedding methods for amplifiers unseen in the training time. Our findings showcase the efficacy and potential of the proposed methods in achieving versatile one-to-many amplifier modeling, contributing a foundational step towards zero-shot audio modeling applications.
A Study on Synthesizing Expressive Violin Performances: Approaches and Comparisons
Jun 26, 2024



Expressive music synthesis (EMS) for violin performance is a challenging task due to the disagreement among music performers in the interpretation of expressive musical terms (EMTs), scarcity of labeled recordings, and limited generalization ability of the synthesis model. These challenges create trade-offs between model effectiveness, diversity of generated results, and controllability of the synthesis system, making it essential to conduct a comparative study on EMS model design. This paper explores two violin EMS approaches. The end-to-end approach is a modification of a state-of-the-art text-to-speech generator. The parameter-controlled approach is based on a simple parameter sampling process that can render note lengths and other parameters compatible with MIDI-DDSP. We study these two approaches (in total, three model variants) through objective and subjective experiments and discuss several key issues of EMS based on the results.