 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Design Choices in Joint-Embedding Predictive Architectures for General Audio Representation Learning
Paper and Code



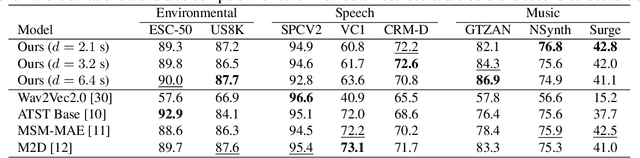
This paper addresses the problem of self-supervised general-purpose audio representation learning. We explore the use of Joint-Embedding Predictive Architectures (JEPA) for this task, which consists of splitting an input mel-spectrogram into two parts (context and target), computing neural representations for each, and training the neural network to predict the target representations from the context representations. We investigate several design choices within this framework and study their influence through extensive experiments by evaluating our models on various audio classification benchmarks, including environmental sounds, speech and music downstream tasks. We focus notably on which part of the input data is used as context or target and show experimentally that it significantly impacts the model's quality. In particular, we notice that some effective design choices in the image domain lead to poor performance on audio, thus highlighting major differences between these two modalities.