 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiveBand: Live Accompaniment Generation in the Audio Domain
Jun 02, 2026We present LiveBand, a real-time system that generates high-fidelity music accompaniments to live audio input, respecting strict causal constraints. Our method trains a causal transformer generator in the continuous latent space of a pre-trained causal audio autoencoder, using adversarial sequence-level supervision from a discriminator. At each timestep, the generator receives only the causally available mix context and Gaussian noise, and predicts accompaniment latents without access to future mix frames or ground-truth target latents. Training is performed in a single parallel forward pass under causal masking, while streaming inference proceeds autoregressively with a rolling attention state. The model's training and inference computations are matched by design, eliminating teacher forcing and the associated exposure bias. On a multi-instrument music accompaniment benchmark, LiveBand improves over prior work on objective measures of audio quality, beat alignment, and mix adherence, while enabling real-time streaming generation without lookahead into the future on consumer hardware.
Perceptually Aligning Representations of Music via Noise-Augmented Autoencoders
Nov 10, 2025We argue that training autoencoders to reconstruct inputs from noised versions of their encodings, when combined with perceptual losses, yields encodings that are structured according to a perceptual hierarchy. We demonstrate the emergence of this hierarchical structure by showing that, after training an audio autoencoder in this manner, perceptually salient information is captured in coarser representation structures than with conventional training. Furthermore, we show that such perceptual hierarchies improve latent diffusion decoding in the context of estimating surprisal in music pitches and predicting EEG-brain responses to music listening. Pretrained weights are available on github.com/CPJKU/pa-audioic.
Estimating Musical Surprisal from Audio in Autoregressive Diffusion Model Noise Spaces
Aug 07, 2025Recently, the information content (IC) of predictions from a Generative Infinite-Vocabulary Transformer (GIVT) has been used to model musical expectancy and surprisal in audio. We investigate the effectiveness of such modelling using IC calculated with autoregressive diffusion models (ADMs). We empirically show that IC estimates of models based on two different diffusion ordinary differential equations (ODEs) describe diverse data better, in terms of negative log-likelihood, than a GIVT. We evaluate diffusion model IC's effectiveness in capturing surprisal aspects by examining two tasks: (1) capturing monophonic pitch surprisal, and (2) detecting segment boundaries in multi-track audio. In both tasks, the diffusion models match or exceed the performance of a GIVT. We hypothesize that the surprisal estimated at different diffusion process noise levels corresponds to the surprisal of music and audio features present at different audio granularities. Testing our hypothesis, we find that, for appropriate noise levels, the studied musical surprisal tasks' results improve. Code is provided on github.com/SonyCSLParis/audioic.
Estimating Musical Surprisal in Audio
Jan 13, 2025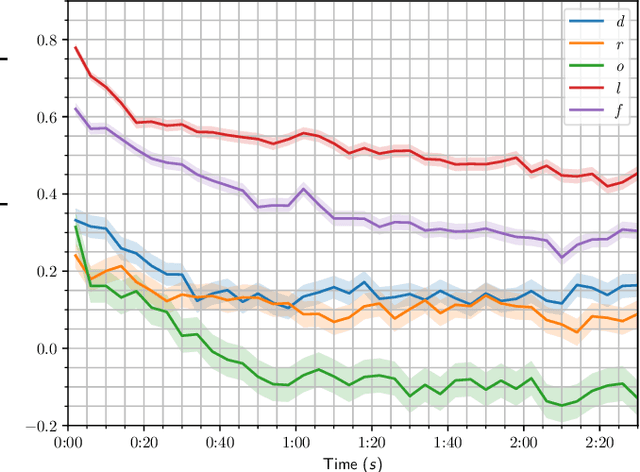
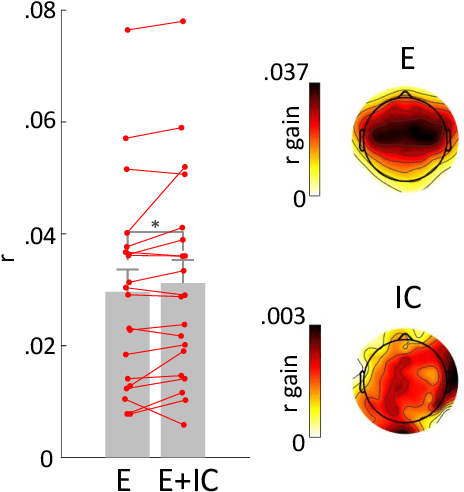
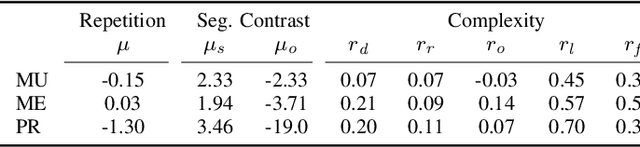
In modeling musical surprisal expectancy with computational methods, it has been proposed to use the information content (IC) of one-step predictions from an autoregressive model as a proxy for surprisal in symbolic music. With an appropriately chosen model, the IC of musical events has been shown to correlate with human perception of surprise and complexity aspects, including tonal and rhythmic complexity. This work investigates whether an analogous methodology can be applied to music audio. We train an autoregressive Transformer model to predict compressed latent audio representations of a pretrained autoencoder network. We verify learning effects by estimating the decrease in IC with repetitions. We investigate the mean IC of musical segment types (e.g., A or B) and find that segment types appearing later in a piece have a higher IC than earlier ones on average. We investigate the IC's relation to audio and musical features and find it correlated with timbral variations and loudness and, to a lesser extent, dissonance, rhythmic complexity, and onset density related to audio and musical features. Finally, we investigate if the IC can predict EEG responses to songs and thus model humans' surprisal in music. We provide code for our method on github.com/sonycslparis/audioic.
Controlling Surprisal in Music Generation via Information Content Curve Matching
Aug 12, 2024In recent years, the quality and public interest in music generation systems have grown, encouraging research into various ways to control these systems. We propose a novel method for controlling surprisal in music generation using sequence models. To achieve this goal, we define a metric called Instantaneous Information Content (IIC). The IIC serves as a proxy function for the perceived musical surprisal (as estimated from a probabilistic model) and can be calculated at any point within a music piece. This enables the comparison of surprisal across different musical content even if the musical events occur in irregular time intervals. We use beam search to generate musical material whose IIC curve closely approximates a given target IIC. We experimentally show that the IIC correlates with harmonic and rhythmic complexity and note density. The correlation decreases with the length of the musical context used for estimating the IIC. Finally, we conduct a qualitative user study to test if human listeners can identify the IIC curves that have been used as targets when generating the respective musical material. We provide code for creating IIC interpolations and IIC visualizations on https://github.com/muthissar/iic.
Exploring Sampling Techniques for Generating Melodies with a Transformer Language Model
Aug 18, 2023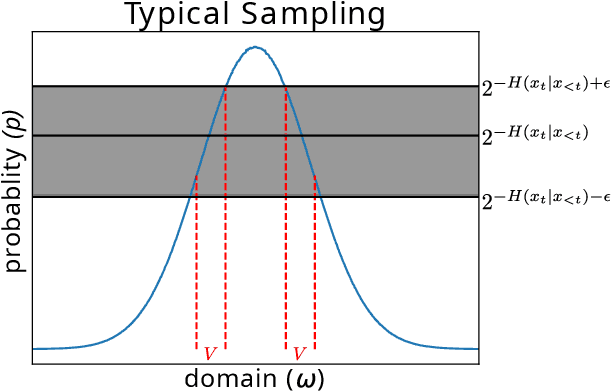
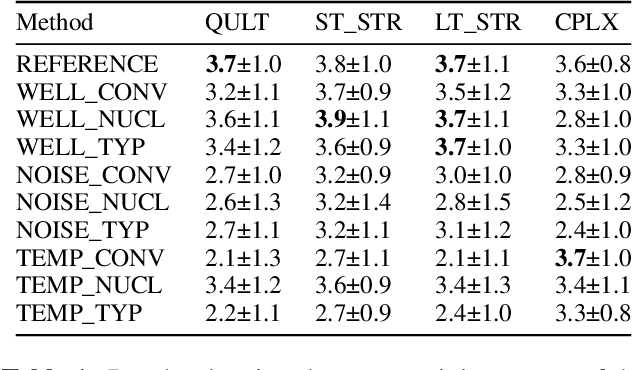
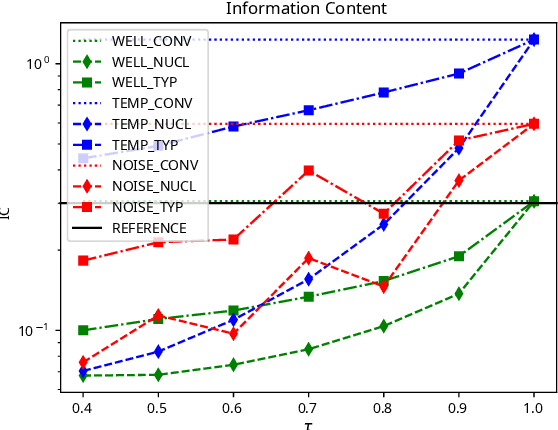
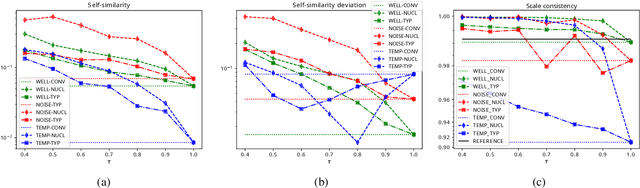
Research in natural language processing has demonstrated that the quality of generations from trained autoregressive language models is significantly influenced by the used sampling strategy. In this study, we investigate the impact of different sampling techniques on musical qualities such as diversity and structure. To accomplish this, we train a high-capacity transformer model on a vast collection of highly-structured Irish folk melodies and analyze the musical qualities of the samples generated using distribution truncation sampling techniques. Specifically, we use nucleus sampling, the recently proposed "typical sampling", and conventional ancestral sampling. We evaluate the effect of these sampling strategies in two scenarios: optimal circumstances with a well-calibrated model and suboptimal circumstances where we systematically degrade the model's performance. We assess the generated samples using objective and subjective evaluations. We discover that probability truncation techniques may restrict diversity and structural patterns in optimal circumstances, but may also produce more musical samples in suboptimal circumstances.
On the Typicality of Musical Sequences
Nov 23, 2022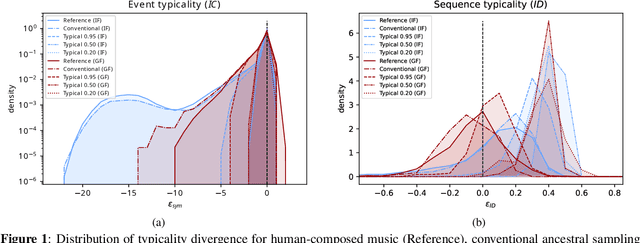
It has been shown in a recent publication that words in human-produced English language tend to have an information content close to the conditional entropy. In this paper, we show that the same is true for events in human-produced monophonic musical sequences. We also show how "typical sampling" influences the distribution of information around the entropy for single events and sequences.