 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy Distillation: Reducing Re-identification Risk of Multimodal Diffusion Models
Jun 02, 2023



Knowledge distillation in neural networks refers to compressing a large model or dataset into a smaller version of itself. We introduce Privacy Distillation, a framework that allows a text-to-image generative model to teach another model without exposing it to identifiable data. Here, we are interested in the privacy issue faced by a data provider who wishes to share their data via a multimodal generative model. A question that immediately arises is ``How can a data provider ensure that the generative model is not leaking identifiable information about a patient?''. Our solution consists of (1) training a first diffusion model on real data (2) generating a synthetic dataset using this model and filtering it to exclude images with a re-identifiability risk (3) training a second diffusion model on the filtered synthetic data only. We showcase that datasets sampled from models trained with privacy distillation can effectively reduce re-identification risk whilst maintaining downstream performance.
Indication as Prior Knowledge for Multimodal Disease Classification in Chest Radiographs with Transformers
Feb 12, 2022

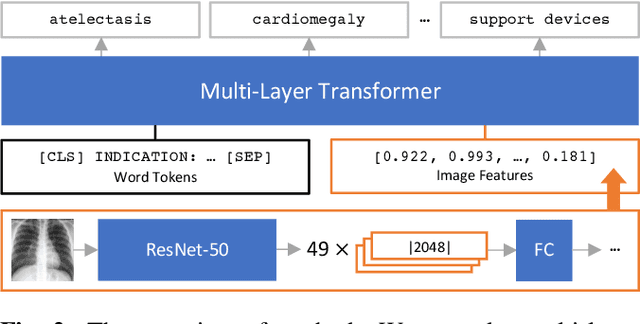

When a clinician refers a patient for an imaging exam, they include the reason (e.g. relevant patient history, suspected disease) in the scan request; this appears as the indication field in the radiology report. The interpretation and reporting of the image are substantially influenced by this request text, steering the radiologist to focus on particular aspects of the image. We use the indication field to drive better image classification, by taking a transformer network which is unimodally pre-trained on text (BERT) and fine-tuning it for multimodal classification of a dual image-text input. We evaluate the method on the MIMIC-CXR dataset, and present ablation studies to investigate the effect of the indication field on the classification performance. The experimental results show our approach achieves 87.8 average micro AUROC, outperforming the state-of-the-art methods for unimodal (84.4) and multimodal (86.0) classification. Our code is available at https://github.com/jacenkow/mmbt.
INSIDE: Steering Spatial Attention with Non-Imaging Information in CNNs
Aug 21, 2020We consider the problem of integrating non-imaging information into segmentation networks to improve performance. Conditioning layers such as FiLM provide the means to selectively amplify or suppress the contribution of different feature maps in a linear fashion. However, spatial dependency is difficult to learn within a convolutional paradigm. In this paper, we propose a mechanism to allow for spatial localisation conditioned on non-imaging information, using a feature-wise attention mechanism comprising a differentiable parametrised function (e.g. Gaussian), prior to applying the feature-wise modulation. We name our method INstance modulation with SpatIal DEpendency (INSIDE). The conditioning information might comprise any factors that relate to spatial or spatio-temporal information such as lesion location, size, and cardiac cycle phase. Our method can be trained end-to-end and does not require additional supervision. We evaluate the method on two datasets: a new CLEVR-Seg dataset where we segment objects based on location, and the ACDC dataset conditioned on cardiac phase and slice location within the volume. Code and the CLEVR-Seg dataset are available at https://github.com/jacenkow/inside.