 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan segmentation models be trained with fully synthetically generated data?
Sep 17, 2022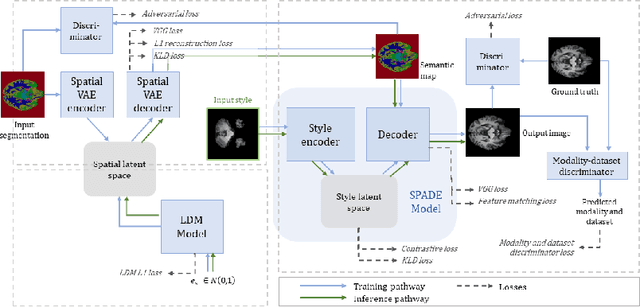

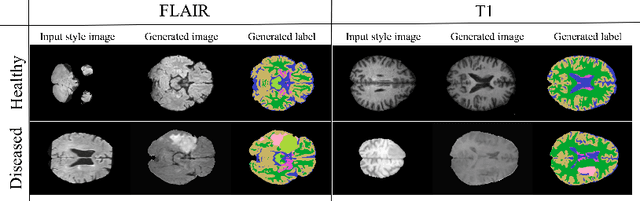
In order to achieve good performance and generalisability, medical image segmentation models should be trained on sizeable datasets with sufficient variability. Due to ethics and governance restrictions, and the costs associated with labelling data, scientific development is often stifled, with models trained and tested on limited data. Data augmentation is often used to artificially increase the variability in the data distribution and improve model generalisability. Recent works have explored deep generative models for image synthesis, as such an approach would enable the generation of an effectively infinite amount of varied data, addressing the generalisability and data access problems. However, many proposed solutions limit the user's control over what is generated. In this work, we propose brainSPADE, a model which combines a synthetic diffusion-based label generator with a semantic image generator. Our model can produce fully synthetic brain labels on-demand, with or without pathology of interest, and then generate a corresponding MRI image of an arbitrary guided style. Experiments show that brainSPADE synthetic data can be used to train segmentation models with performance comparable to that of models trained on real data.
Transformer-based out-of-distribution detection for clinically safe segmentation
May 21, 2022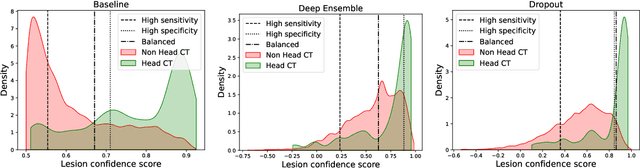
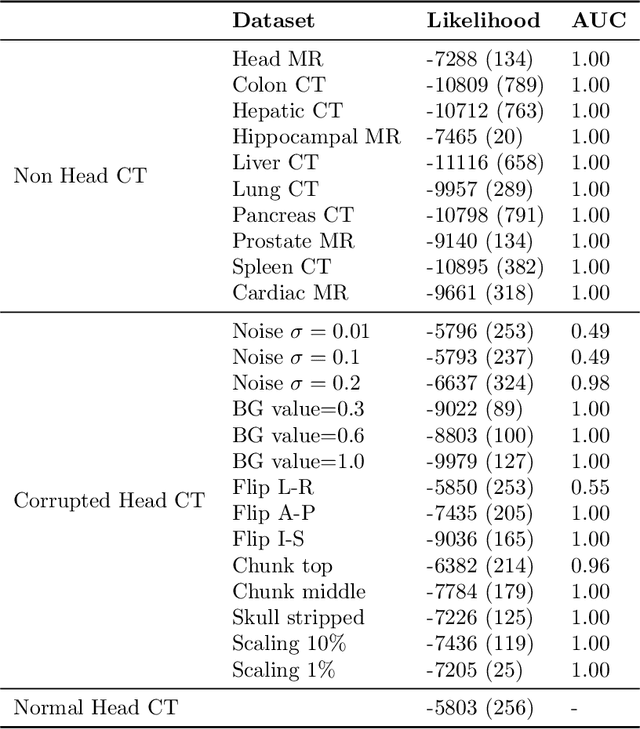
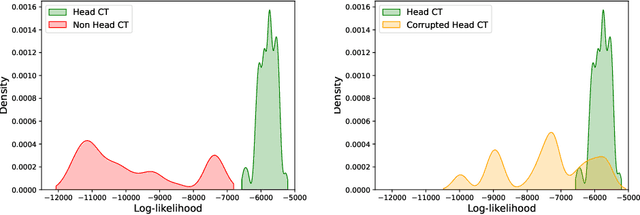
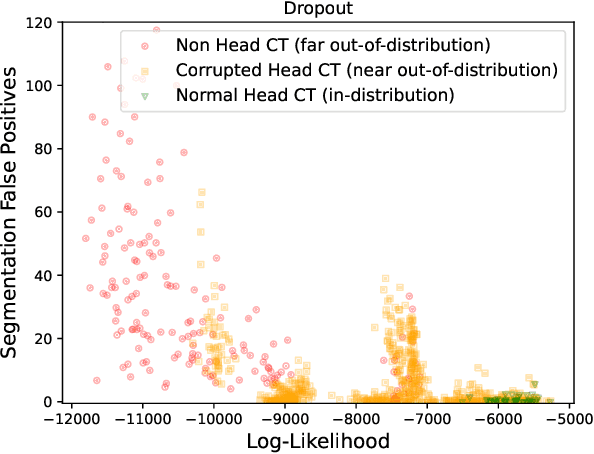
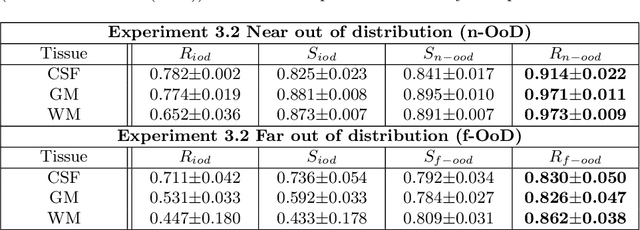
In a clinical setting it is essential that deployed image processing systems are robust to the full range of inputs they might encounter and, in particular, do not make confidently wrong predictions. The most popular approach to safe processing is to train networks that can provide a measure of their uncertainty, but these tend to fail for inputs that are far outside the training data distribution. Recently, generative modelling approaches have been proposed as an alternative; these can quantify the likelihood of a data sample explicitly, filtering out any out-of-distribution (OOD) samples before further processing is performed. In this work, we focus on image segmentation and evaluate several approaches to network uncertainty in the far-OOD and near-OOD cases for the task of segmenting haemorrhages in head CTs. We find all of these approaches are unsuitable for safe segmentation as they provide confidently wrong predictions when operating OOD. We propose performing full 3D OOD detection using a VQ-GAN to provide a compressed latent representation of the image and a transformer to estimate the data likelihood. Our approach successfully identifies images in both the far- and near-OOD cases. We find a strong relationship between image likelihood and the quality of a model's segmentation, making this approach viable for filtering images unsuitable for segmentation. To our knowledge, this is the first time transformers have been applied to perform OOD detection on 3D image data.