 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Wake Word Detection with Synthesized Speech Data on Confusion Words
Paper and Code
Nov 03, 2020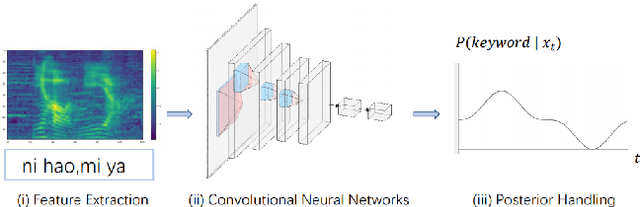
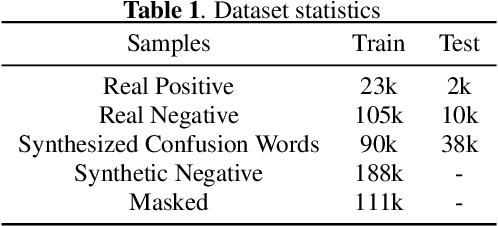
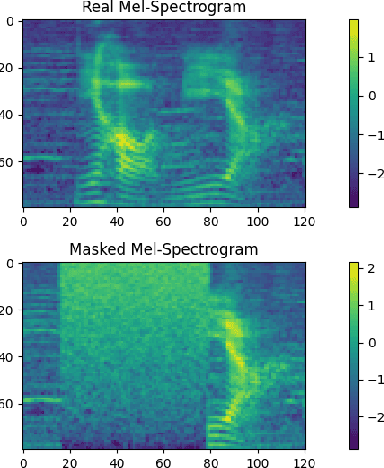
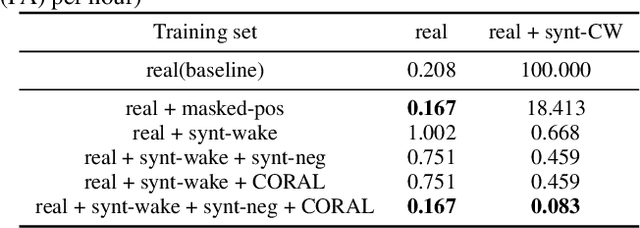
Confusing-words are commonly encountered in real-life keyword spotting applications, which causes severe degradation of performance due to complex spoken terms and various kinds of words that sound similar to the predefined keywords. To enhance the wake word detection system's robustness on such scenarios, we investigate two data augmentation setups for training end-to-end KWS systems. One is involving the synthesized data from a multi-speaker speech synthesis system, and the other augmentation is performed by adding random noise to the acoustic feature. Experimental results show that augmentations help improve the system's robustness. Moreover, by augmenting the training set with the synthetic data generated by the multi-speaker text-to-speech system, we achieve a significant improvement regarding confusing words scenario.