 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZipEnhancer: Dual-Path Down-Up Sampling-based Zipformer for Monaural Speech Enhancement
Paper and Code


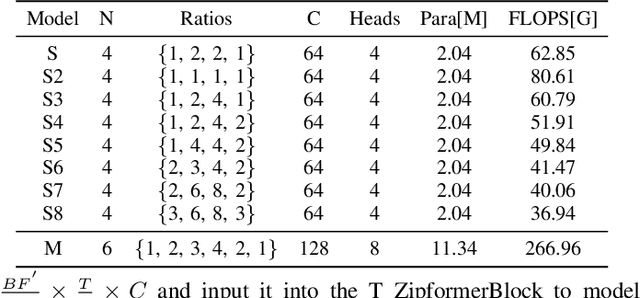
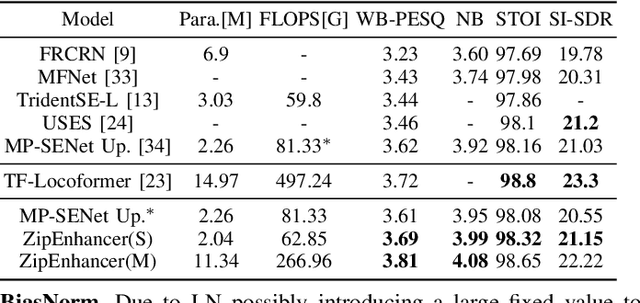
In contrast to other sequence tasks modeling hidden layer features with three axes, Dual-Path time and time-frequency domain speech enhancement models are effective and have low parameters but are computationally demanding due to their hidden layer features with four axes. We propose ZipEnhancer, which is Dual-Path Down-Up Sampling-based Zipformer for Monaural Speech Enhancement, incorporating time and frequency domain Down-Up sampling to reduce computational costs. We introduce the ZipformerBlock as the core block and propose the design of the Dual-Path DownSampleStacks that symmetrically scale down and scale up. Also, we introduce the ScaleAdam optimizer and Eden learning rate scheduler to improve the performance further. Our model achieves new state-of-the-art results on the DNS 2020 Challenge and Voicebank+DEMAND datasets, with a perceptual evaluation of speech quality (PESQ) of 3.69 and 3.63, using 2.04M parameters and 62.41G FLOPS, outperforming other methods with similar complexity levels.