 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMASC: Metal-Aware Sampling and Correction via Reinforcement Learning for Accelerated MRI
Jan 30, 2026Metal implants in MRI cause severe artifacts that degrade image quality and hinder clinical diagnosis. Traditional approaches address metal artifact reduction (MAR) and accelerated MRI acquisition as separate problems. We propose MASC, a unified reinforcement learning framework that jointly optimizes metal-aware k-space sampling and artifact correction for accelerated MRI. To enable supervised training, we construct a paired MRI dataset using physics-based simulation, generating k-space data and reconstructions for phantoms with and without metal implants. This paired dataset provides simulated 3D MRI scans with and without metal implants, where each metal-corrupted sample has an exactly matched clean reference, enabling direct supervision for both artifact reduction and acquisition policy learning. We formulate active MRI acquisition as a sequential decision-making problem, where an artifact-aware Proximal Policy Optimization (PPO) agent learns to select k-space phase-encoding lines under a limited acquisition budget. The agent operates on undersampled reconstructions processed through a U-Net-based MAR network, learning patterns that maximize reconstruction quality. We further propose an end-to-end training scheme where the acquisition policy learns to select k-space lines that best support artifact removal while the MAR network simultaneously adapts to the resulting undersampling patterns. Experiments demonstrate that MASC's learned policies outperform conventional sampling strategies, and end-to-end training improves performance compared to using a frozen pre-trained MAR network, validating the benefit of joint optimization. Cross-dataset experiments on FastMRI with physics-based artifact simulation further confirm generalization to realistic clinical MRI data. The code and models of MASC have been made publicly available: https://github.com/hrlblab/masc
SCR2-ST: Combine Single Cell with Spatial Transcriptomics for Efficient Active Sampling via Reinforcement Learning
Dec 15, 2025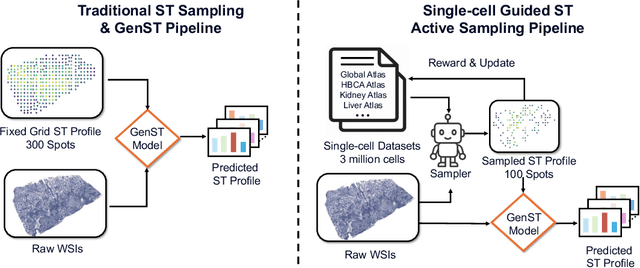
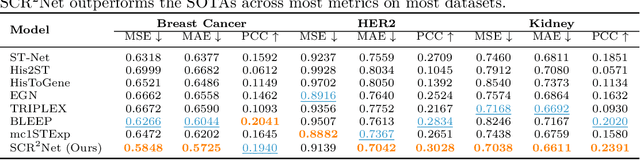
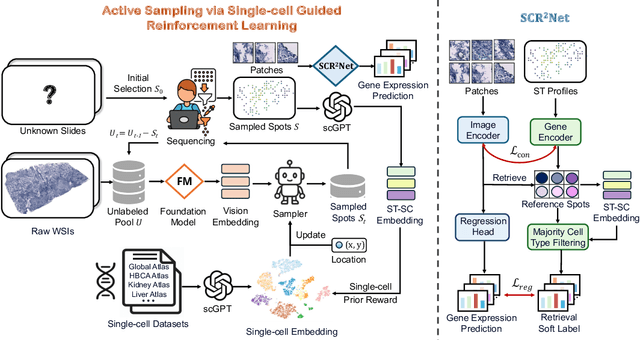
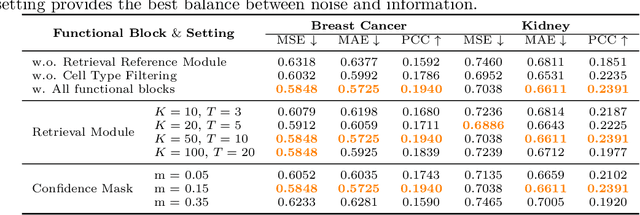
Spatial transcriptomics (ST) is an emerging technology that enables researchers to investigate the molecular relationships underlying tissue morphology. However, acquiring ST data remains prohibitively expensive, and traditional fixed-grid sampling strategies lead to redundant measurements of morphologically similar or biologically uninformative regions, thus resulting in scarce data that constrain current methods. The well-established single-cell sequencing field, however, could provide rich biological data as an effective auxiliary source to mitigate this limitation. To bridge these gaps, we introduce SCR2-ST, a unified framework that leverages single-cell prior knowledge to guide efficient data acquisition and accurate expression prediction. SCR2-ST integrates a single-cell guided reinforcement learning-based (SCRL) active sampling and a hybrid regression-retrieval prediction network SCR2Net. SCRL combines single-cell foundation model embeddings with spatial density information to construct biologically grounded reward signals, enabling selective acquisition of informative tissue regions under constrained sequencing budgets. SCR2Net then leverages the actively sampled data through a hybrid architecture combining regression-based modeling with retrieval-augmented inference, where a majority cell-type filtering mechanism suppresses noisy matches and retrieved expression profiles serve as soft labels for auxiliary supervision. We evaluated SCR2-ST on three public ST datasets, demonstrating SOTA performance in both sampling efficiency and prediction accuracy, particularly under low-budget scenarios. Code is publicly available at: https://github.com/hrlblab/SCR2ST
IRS: Incremental Relationship-guided Segmentation for Digital Pathology
May 28, 2025Continual learning is rapidly emerging as a key focus in computer vision, aiming to develop AI systems capable of continuous improvement, thereby enhancing their value and practicality in diverse real-world applications. In healthcare, continual learning holds great promise for continuously acquired digital pathology data, which is collected in hospitals on a daily basis. However, panoramic segmentation on digital whole slide images (WSIs) presents significant challenges, as it is often infeasible to obtain comprehensive annotations for all potential objects, spanning from coarse structures (e.g., regions and unit objects) to fine structures (e.g., cells). This results in temporally and partially annotated data, posing a major challenge in developing a holistic segmentation framework. Moreover, an ideal segmentation model should incorporate new phenotypes, unseen diseases, and diverse populations, making this task even more complex. In this paper, we introduce a novel and unified Incremental Relationship-guided Segmentation (IRS) learning scheme to address temporally acquired, partially annotated data while maintaining out-of-distribution (OOD) continual learning capacity in digital pathology. The key innovation of IRS lies in its ability to realize a new spatial-temporal OOD continual learning paradigm by mathematically modeling anatomical relationships between existing and newly introduced classes through a simple incremental universal proposition matrix. Experimental results demonstrate that the IRS method effectively handles the multi-scale nature of pathological segmentation, enabling precise kidney segmentation across various structures (regions, units, and cells) as well as OOD disease lesions at multiple magnifications. This capability significantly enhances domain generalization, making IRS a robust approach for real-world digital pathology applications.
How Good Are We? Evaluating Cell AI Foundation Models in Kidney Pathology with Human-in-the-Loop Enrichment
Oct 31, 2024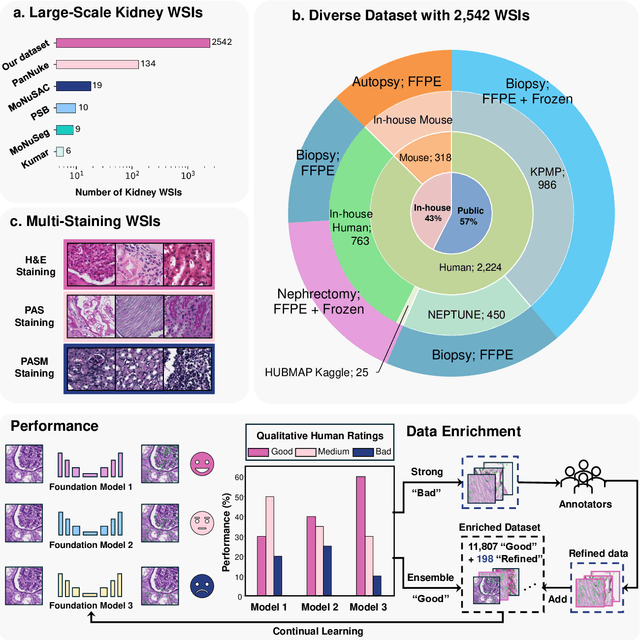

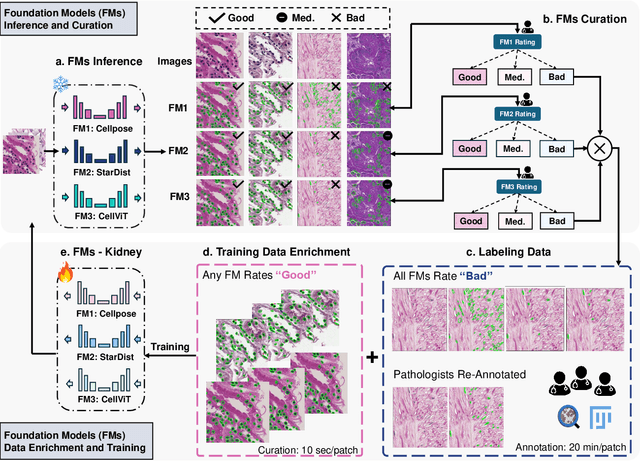
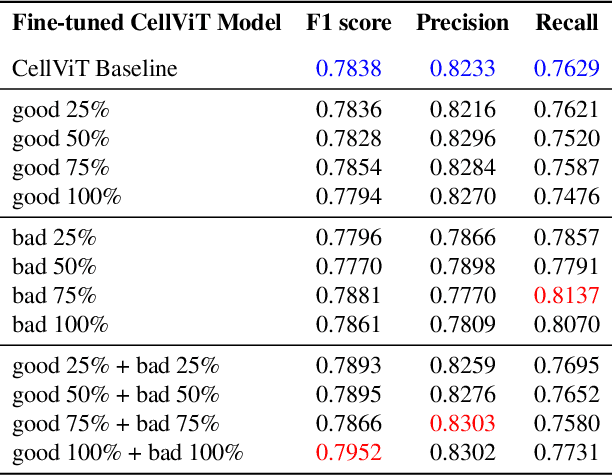
Training AI foundation models has emerged as a promising large-scale learning approach for addressing real-world healthcare challenges, including digital pathology. While many of these models have been developed for tasks like disease diagnosis and tissue quantification using extensive and diverse training datasets, their readiness for deployment on some arguably simplest tasks, such as nuclei segmentation within a single organ (e.g., the kidney), remains uncertain. This paper seeks to answer this key question, "How good are we?", by thoroughly evaluating the performance of recent cell foundation models on a curated multi-center, multi-disease, and multi-species external testing dataset. Additionally, we tackle a more challenging question, "How can we improve?", by developing and assessing human-in-the-loop data enrichment strategies aimed at enhancing model performance while minimizing the reliance on pixel-level human annotation. To address the first question, we curated a multicenter, multidisease, and multispecies dataset consisting of 2,542 kidney whole slide images (WSIs). Three state-of-the-art (SOTA) cell foundation models-Cellpose, StarDist, and CellViT-were selected for evaluation. To tackle the second question, we explored data enrichment algorithms by distilling predictions from the different foundation models with a human-in-the-loop framework, aiming to further enhance foundation model performance with minimal human efforts. Our experimental results showed that all three foundation models improved over their baselines with model fine-tuning with enriched data. Interestingly, the baseline model with the highest F1 score does not yield the best segmentation outcomes after fine-tuning. This study establishes a benchmark for the development and deployment of cell vision foundation models tailored for real-world data applications.
Assessment of Cell Nuclei AI Foundation Models in Kidney Pathology
Aug 09, 2024Cell nuclei instance segmentation is a crucial task in digital kidney pathology. Traditional automatic segmentation methods often lack generalizability when applied to unseen datasets. Recently, the success of foundation models (FMs) has provided a more generalizable solution, potentially enabling the segmentation of any cell type. In this study, we perform a large-scale evaluation of three widely used state-of-the-art (SOTA) cell nuclei foundation models (Cellpose, StarDist, and CellViT). Specifically, we created a highly diverse evaluation dataset consisting of 2,542 kidney whole slide images (WSIs) collected from both human and rodent sources, encompassing various tissue types, sizes, and staining methods. To our knowledge, this is the largest-scale evaluation of its kind to date. Our quantitative analysis of the prediction distribution reveals a persistent performance gap in kidney pathology. Among the evaluated models, CellViT demonstrated superior performance in segmenting nuclei in kidney pathology. However, none of the foundation models are perfect; a performance gap remains in general nuclei segmentation for kidney pathology.
Dataset Distillation in Medical Imaging: A Feasibility Study
Jul 19, 2024
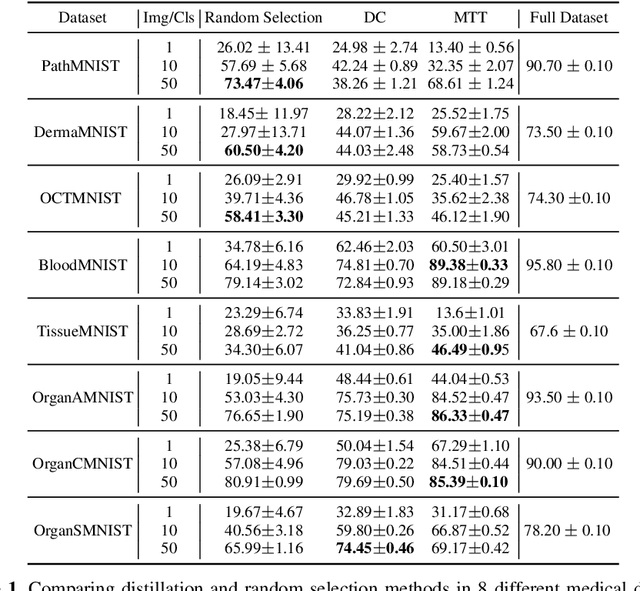
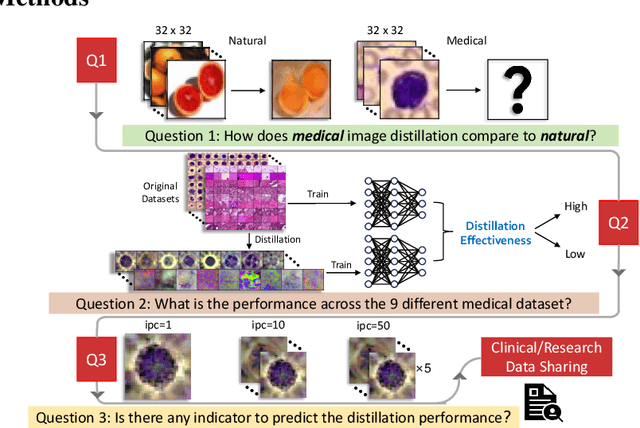

Data sharing in the medical image analysis field has potential yet remains underappreciated. The aim is often to share datasets efficiently with other sites to train models effectively. One possible solution is to avoid transferring the entire dataset while still achieving similar model performance. Recent progress in data distillation within computer science offers promising prospects for sharing medical data efficiently without significantly compromising model effectiveness. However, it remains uncertain whether these methods would be applicable to medical imaging, since medical and natural images are distinct fields. Moreover, it is intriguing to consider what level of performance could be achieved with these methods. To answer these questions, we conduct investigations on a variety of leading data distillation methods, in different contexts of medical imaging. We evaluate the feasibility of these methods with extensive experiments in two aspects: 1) Assess the impact of data distillation across multiple datasets characterized by minor or great variations. 2) Explore the indicator to predict the distillation performance. Our extensive experiments across multiple medical datasets reveal that data distillation can significantly reduce dataset size while maintaining comparable model performance to that achieved with the full dataset, suggesting that a small, representative sample of images can serve as a reliable indicator of distillation success. This study demonstrates that data distillation is a viable method for efficient and secure medical data sharing, with the potential to facilitate enhanced collaborative research and clinical applications.