 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Distillation in Medical Imaging: A Feasibility Study
Paper and Code
Jul 19, 2024
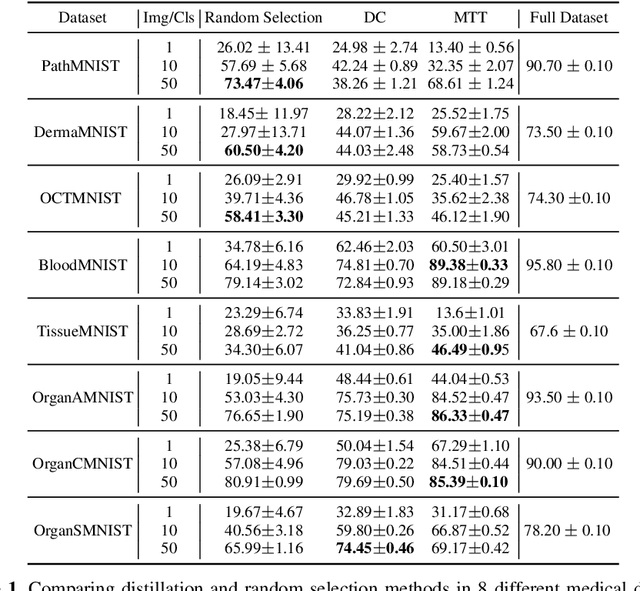
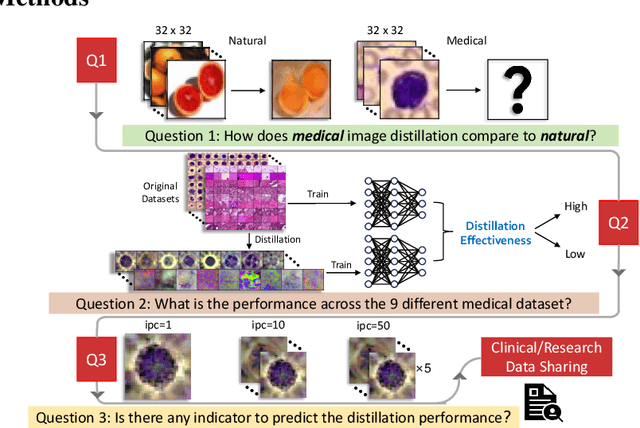

Data sharing in the medical image analysis field has potential yet remains underappreciated. The aim is often to share datasets efficiently with other sites to train models effectively. One possible solution is to avoid transferring the entire dataset while still achieving similar model performance. Recent progress in data distillation within computer science offers promising prospects for sharing medical data efficiently without significantly compromising model effectiveness. However, it remains uncertain whether these methods would be applicable to medical imaging, since medical and natural images are distinct fields. Moreover, it is intriguing to consider what level of performance could be achieved with these methods. To answer these questions, we conduct investigations on a variety of leading data distillation methods, in different contexts of medical imaging. We evaluate the feasibility of these methods with extensive experiments in two aspects: 1) Assess the impact of data distillation across multiple datasets characterized by minor or great variations. 2) Explore the indicator to predict the distillation performance. Our extensive experiments across multiple medical datasets reveal that data distillation can significantly reduce dataset size while maintaining comparable model performance to that achieved with the full dataset, suggesting that a small, representative sample of images can serve as a reliable indicator of distillation success. This study demonstrates that data distillation is a viable method for efficient and secure medical data sharing, with the potential to facilitate enhanced collaborative research and clinical applications.