 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Determine the Most Powerful Pre-trained Language Model without Brute Force Fine-tuning? An Empirical Survey
Paper and Code
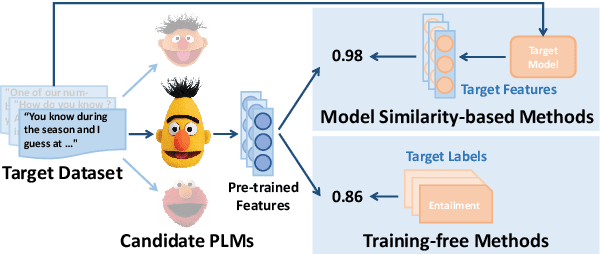
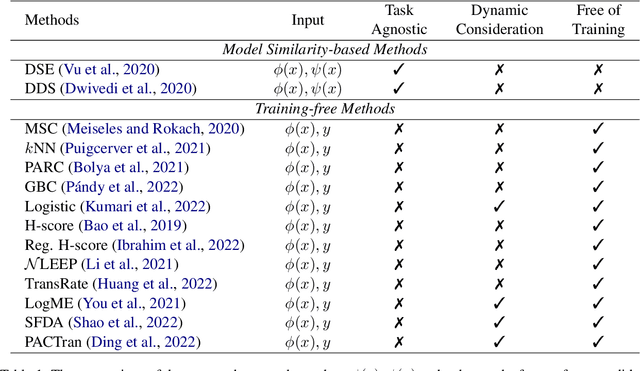
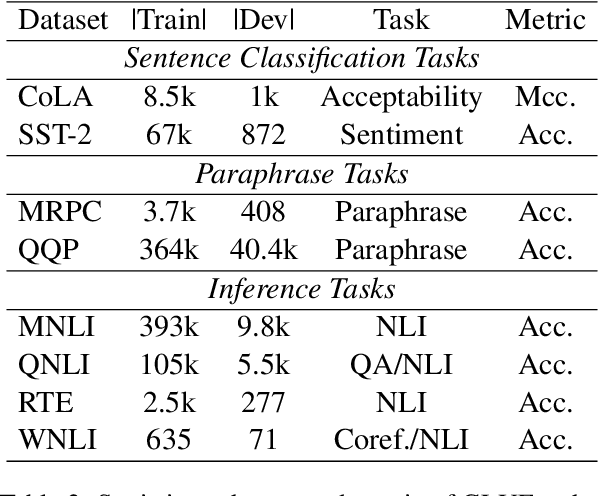
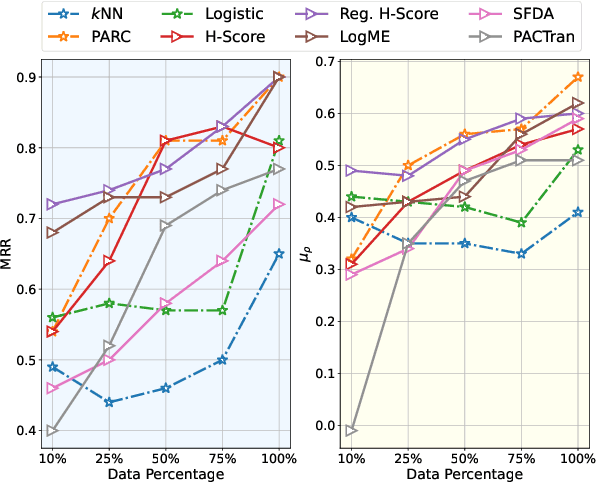
Transferability estimation has been attached to great attention in the computer vision fields. Researchers try to estimate with low computational cost the performance of a model when transferred from a source task to a given target task. Considering the effectiveness of such estimations, the communities of natural language processing also began to study similar problems for the selection of pre-trained language models. However, there is a lack of a comprehensive comparison between these estimation methods yet. Also, the differences between vision and language scenarios make it doubtful whether previous conclusions can be established across fields. In this paper, we first conduct a thorough survey of existing transferability estimation methods being able to find the most suitable model, then we conduct a detailed empirical study for the surveyed methods based on the GLUE benchmark. From qualitative and quantitative analyses, we demonstrate the strengths and weaknesses of existing methods and show that H-Score generally performs well with superiorities in effectiveness and efficiency. We also outline the difficulties of consideration of training details, applicability to text generation, and consistency to certain metrics which shed light on future directions.