 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFASST: Fast LLM-based Simultaneous Speech Translation
Paper and Code
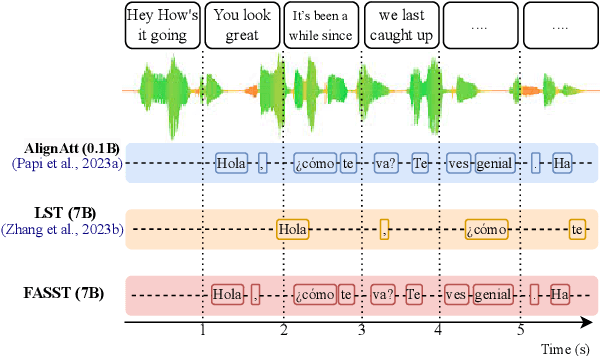

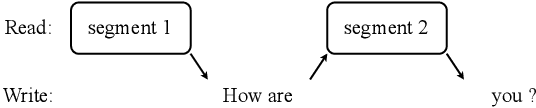

Simultaneous speech translation (SST) takes streaming speech input and generates text translation on the fly. Existing methods either have high latency due to recomputation of input representations, or fall behind of offline ST in translation quality. In this paper, we propose FASST, a fast large language model based method for streaming speech translation. We propose blockwise-causal speech encoding and consistency mask, so that streaming speech input can be encoded incrementally without recomputation. Furthermore, we develop a two-stage training strategy to optimize FASST for simultaneous inference. We evaluate FASST and multiple strong prior models on MuST-C dataset. Experiment results show that FASST achieves the best quality-latency trade-off. It outperforms the previous best model by an average of 1.5 BLEU under the same latency for English to Spanish translation.