 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Better IncomLDL: We Are Unaware of Hidden Labels in Advance
Nov 16, 2025Label distribution learning (LDL) is a novel paradigm that describe the samples by label distribution of a sample. However, acquiring LDL dataset is costly and time-consuming, which leads to the birth of incomplete label distribution learning (IncomLDL). All the previous IncomLDL methods set the description degrees of "missing" labels in an instance to 0, but remains those of other labels unchanged. This setting is unrealistic because when certain labels are missing, the degrees of the remaining labels will increase accordingly. We fix this unrealistic setting in IncomLDL and raise a new problem: LDL with hidden labels (HidLDL), which aims to recover a complete label distribution from a real-world incomplete label distribution where certain labels in an instance are omitted during annotation. To solve this challenging problem, we discover the significance of proportional information of the observed labels and capture it by an innovative constraint to utilize it during the optimization process. We simultaneously use local feature similarity and the global low-rank structure to reveal the mysterious veil of hidden labels. Moreover, we theoretically give the recovery bound of our method, proving the feasibility of our method in learning from hidden labels. Extensive recovery and predictive experiments on various datasets prove the superiority of our method to state-of-the-art LDL and IncomLDL methods.
Concentration Distribution Learning from Label Distributions
May 27, 2025Label distribution learning (LDL) is an effective method to predict the relative label description degree (a.k.a. label distribution) of a sample. However, the label distribution is not a complete representation of an instance because it overlooks the absolute intensity of each label. Specifically, it's impossible to obtain the total description degree of hidden labels that not in the label space, which leads to the loss of information and confusion in instances. To solve the above problem, we come up with a new concept named background concentration to serve as the absolute description degree term of the label distribution and introduce it into the LDL process, forming the improved paradigm of concentration distribution learning. Moreover, we propose a novel model by probabilistic methods and neural networks to learn label distributions and background concentrations from existing LDL datasets. Extensive experiments prove that the proposed approach is able to extract background concentrations from label distributions while producing more accurate prediction results than the state-of-the-art LDL methods. The code is available in https://github.com/seutjw/CDL-LD.
Lie-algebra Adaptive Tracking Control for Rigid Body Dynamics
Feb 08, 2025
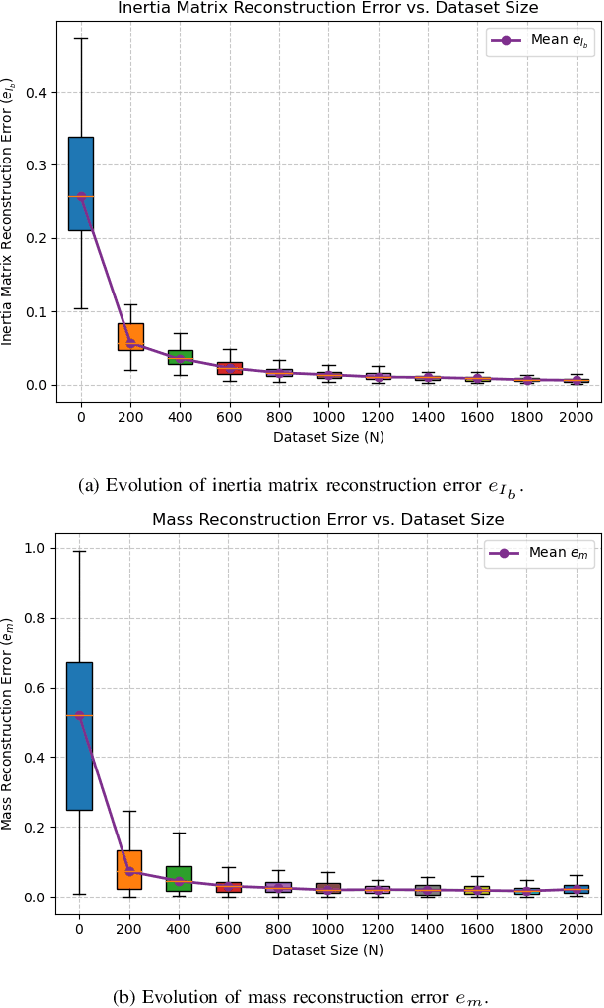


Adaptive tracking control for rigid body dynamics is of critical importance in control and robotics, particularly for addressing uncertainties or variations in system model parameters. However, most existing adaptive control methods are designed for systems with states in vector spaces, often neglecting the manifold constraints inherent to robotic systems. In this work, we propose a novel Lie-algebra-based adaptive control method that leverages the intrinsic relationship between the special Euclidean group and its associated Lie algebra. By transforming the state space from the group manifold to a vector space, we derive a linear error dynamics model that decouples model parameters from the system state. This formulation enables the development of an adaptive optimal control method that is both geometrically consistent and computationally efficient. Extensive simulations demonstrate the effectiveness and efficiency of the proposed method. We have made our source code publicly available to the community to support further research and collaboration.
Bias-VarianceTrade-off in Kalman Filter-Based Disturbance Observers
Oct 07, 2024The performance of disturbance observers is strongly influenced by the level of prior knowledge about the disturbance model. The simultaneous input and state estimation (SISE) algorithm is widely recognized for providing unbiased minimum-variance estimates under arbitrary disturbance models. In contrast, the Kalman filter-based disturbance observer (KF-DOB) achieves minimum mean-square error estimation when the disturbance model is fully specified. However, practical scenarios often fall between these extremes, where only partial knowledge of the disturbance model is available. This paper investigates the inherent bias-variance trade-off in KF-DOB when the disturbance model is incomplete. We further show that SISE can be interpreted as a special case of KF-DOB, where the disturbance noise covariance tends to infinity. To address this trade-off, we propose two novel estimators: the multi-kernel correntropy Kalman filter-based disturbance observer (MKCKF-DOB) and the interacting multiple models Kalman filter-based disturbance observer (IMMKF-DOB). Simulations verify the effectiveness of the proposed methods.
Leveraging Inter-Chunk Interactions for Enhanced Retrieval in Large Language Model-Based Question Answering
Aug 06, 2024



Retrieving external knowledge and prompting large language models with relevant information is an effective paradigm to enhance the performance of question-answering tasks. Previous research typically handles paragraphs from external documents in isolation, resulting in a lack of context and ambiguous references, particularly in multi-document and complex tasks. To overcome these challenges, we propose a new retrieval framework IIER, that leverages Inter-chunk Interactions to Enhance Retrieval. This framework captures the internal connections between document chunks by considering three types of interactions: structural, keyword, and semantic. We then construct a unified Chunk-Interaction Graph to represent all external documents comprehensively. Additionally, we design a graph-based evidence chain retriever that utilizes previous paths and chunk interactions to guide the retrieval process. It identifies multiple seed nodes based on the target question and iteratively searches for relevant chunks to gather supporting evidence. This retrieval process refines the context and reasoning chain, aiding the large language model in reasoning and answer generation. Extensive experiments demonstrate that IIER outperforms strong baselines across four datasets, highlighting its effectiveness in improving retrieval and reasoning capabilities.
MINER-RRT*: A Hierarchical and Fast Trajectory Planning Framework in 3D Cluttered Environments
Jun 02, 2024



Trajectory planning for quadrotors in cluttered environments has been challenging in recent years. While many trajectory planning frameworks have been successful, there still exists potential for improvements, particularly in enhancing the speed of generating efficient trajectories. In this paper, we present a novel hierarchical trajectory planning framework to reduce computational time and memory usage called MINER-RRT*, which consists of two main components. First, we propose a sampling-based path planning method boosted by neural networks, where the predicted heuristic region accelerates the convergence of rapidly-exploring random trees. Second, we utilize the optimal conditions derived from the quadrotor's differential flatness properties to construct polynomial trajectories that minimize control effort in multiple stages. Extensive simulation and real-world experimental results demonstrate that, compared to several state-of-the-art (SOTA) approaches, our method can generate high-quality trajectories with better performance in 3D cluttered environments.
BioBERT-based Deep Learning and Merged ChemProt-DrugProt for Enhanced Biomedical Relation Extraction
May 28, 2024



This paper presents a methodology for enhancing relation extraction from biomedical texts, focusing specifically on chemical-gene interactions. Leveraging the BioBERT model and a multi-layer fully connected network architecture, our approach integrates the ChemProt and DrugProt datasets using a novel merging strategy. Through extensive experimentation, we demonstrate significant performance improvements, particularly in CPR groups shared between the datasets. The findings underscore the importance of dataset merging in augmenting sample counts and improving model accuracy. Moreover, the study highlights the potential of automated information extraction in biomedical research and clinical practice.
KnowledgeNavigator: Leveraging Large Language Models for Enhanced Reasoning over Knowledge Graph
Dec 26, 2023Large language model (LLM) has achieved outstanding performance on various downstream tasks with its powerful natural language understanding and zero-shot capability, but LLM still suffers from knowledge limitation. Especially in scenarios that require long logical chains or complex reasoning, the hallucination and knowledge limitation of LLM limit its performance in question answering (QA). In this paper, we propose a novel framework KnowledgeNavigator to address these challenges by efficiently and accurately retrieving external knowledge from knowledge graph and using it as a key factor to enhance LLM reasoning. Specifically, KnowledgeNavigator first mines and enhances the potential constraints of the given question to guide the reasoning. Then it retrieves and filters external knowledge that supports answering through iterative reasoning on knowledge graph with the guidance of LLM and the question. Finally, KnowledgeNavigator constructs the structured knowledge into effective prompts that are friendly to LLM to help its reasoning. We evaluate KnowledgeNavigator on multiple public KGQA benchmarks, the experiments show the framework has great effectiveness and generalization, outperforming previous knowledge graph enhanced LLM methods and is comparable to the fully supervised models.
Label Distribution Learning from Logical Label
Mar 13, 2023



Label distribution learning (LDL) is an effective method to predict the label description degree (a.k.a. label distribution) of a sample. However, annotating label distribution (LD) for training samples is extremely costly. So recent studies often first use label enhancement (LE) to generate the estimated label distribution from the logical label and then apply external LDL algorithms on the recovered label distribution to predict the label distribution for unseen samples. But this step-wise manner overlooks the possible connections between LE and LDL. Moreover, the existing LE approaches may assign some description degrees to invalid labels. To solve the above problems, we propose a novel method to learn an LDL model directly from the logical label, which unifies LE and LDL into a joint model, and avoids the drawbacks of the previous LE methods. Extensive experiments on various datasets prove that the proposed approach can construct a reliable LDL model directly from the logical label, and produce more accurate label distribution than the state-of-the-art LE methods.
nvBench: A Large-Scale Synthesized Dataset for Cross-Domain Natural Language to Visualization Task
Dec 24, 2021
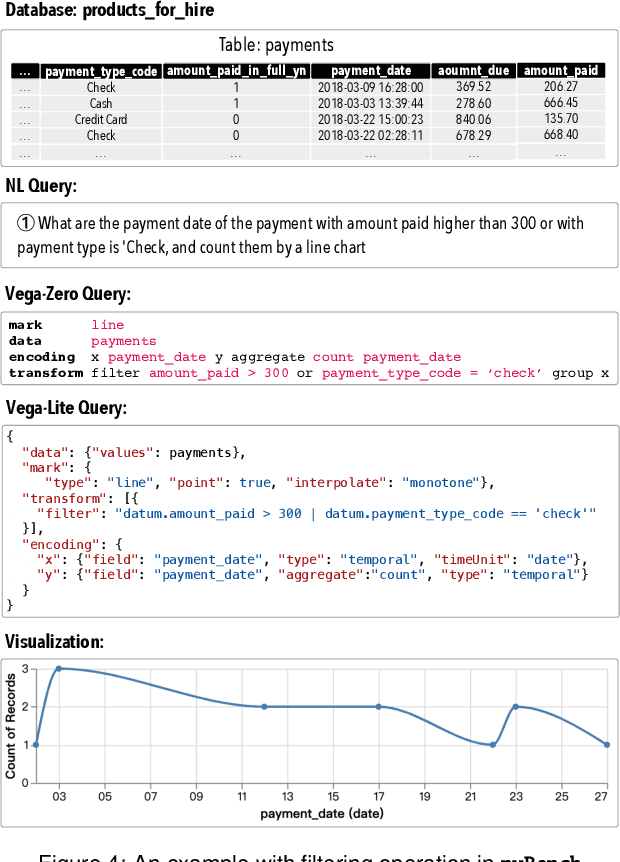

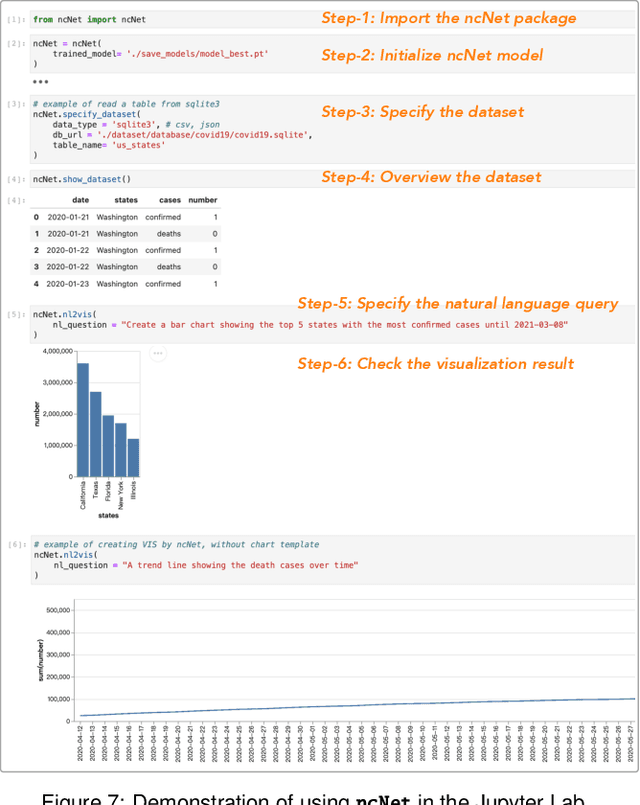
NL2VIS - which translates natural language (NL) queries to corresponding visualizations (VIS) - has attracted more and more attention both in commercial visualization vendors and academic researchers. In the last few years, the advanced deep learning-based models have achieved human-like abilities in many natural language processing (NLP) tasks, which clearly tells us that the deep learning-based technique is a good choice to push the field of NL2VIS. However, a big balk is the lack of benchmarks with lots of (NL, VIS) pairs. We present nvBench, the first large-scale NL2VIS benchmark, containing 25,750 (NL, VIS) pairs from 750 tables over 105 domains, synthesized from (NL, SQL) benchmarks to support cross-domain NL2VIS task. The quality of nvBench has been extensively validated by 23 experts and 300+ crowd workers. Deep learning-based models training using nvBench demonstrate that nvBench can push the field of NL2VIS.