 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgenvBench: A Large-Scale Synthesized Dataset for Cross-Domain Natural Language to Visualization Task
Paper and Code
Dec 24, 2021
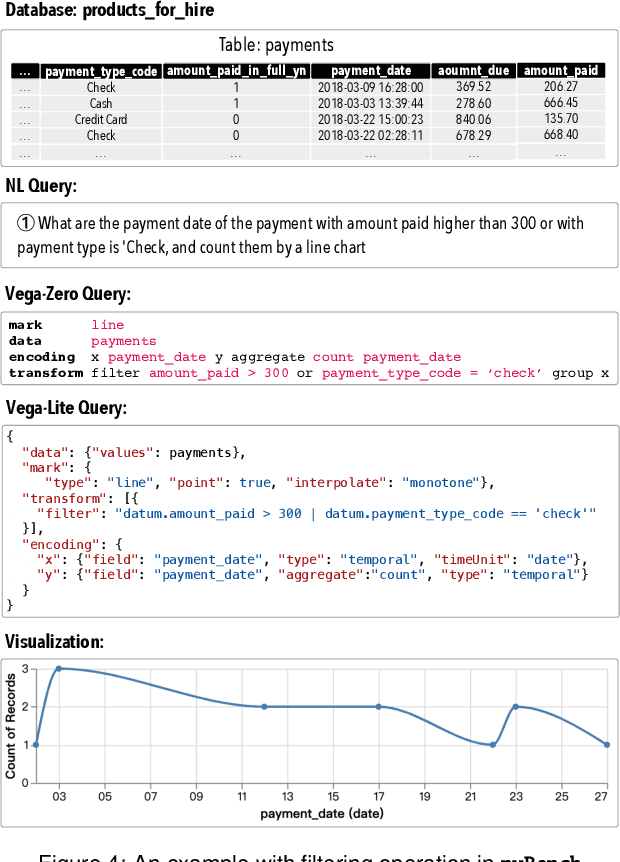

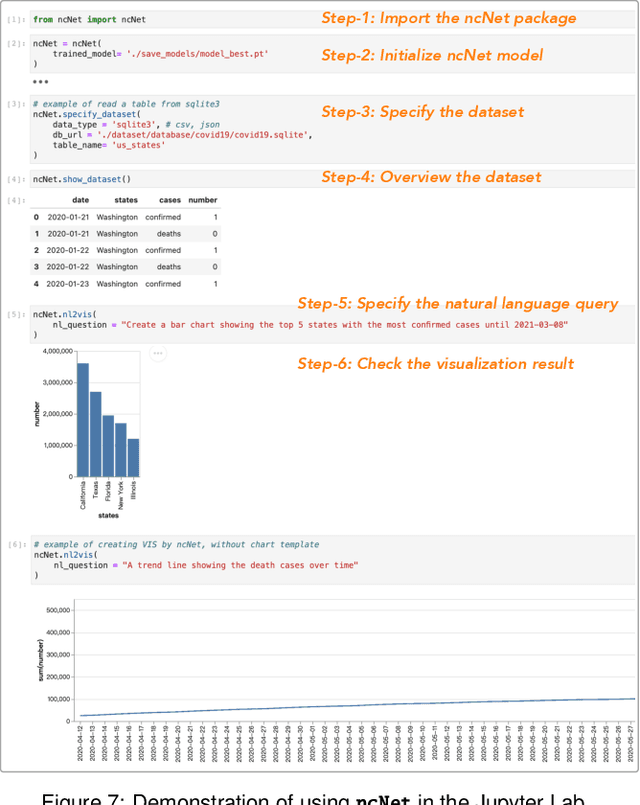
NL2VIS - which translates natural language (NL) queries to corresponding visualizations (VIS) - has attracted more and more attention both in commercial visualization vendors and academic researchers. In the last few years, the advanced deep learning-based models have achieved human-like abilities in many natural language processing (NLP) tasks, which clearly tells us that the deep learning-based technique is a good choice to push the field of NL2VIS. However, a big balk is the lack of benchmarks with lots of (NL, VIS) pairs. We present nvBench, the first large-scale NL2VIS benchmark, containing 25,750 (NL, VIS) pairs from 750 tables over 105 domains, synthesized from (NL, SQL) benchmarks to support cross-domain NL2VIS task. The quality of nvBench has been extensively validated by 23 experts and 300+ crowd workers. Deep learning-based models training using nvBench demonstrate that nvBench can push the field of NL2VIS.