 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private and Adversarially Robust Machine Learning: An Empirical Evaluation
Jan 18, 2024


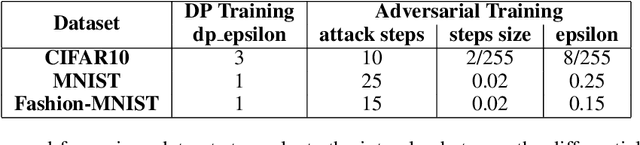
Malicious adversaries can attack machine learning models to infer sensitive information or damage the system by launching a series of evasion attacks. Although various work addresses privacy and security concerns, they focus on individual defenses, but in practice, models may undergo simultaneous attacks. This study explores the combination of adversarial training and differentially private training to defend against simultaneous attacks. While differentially-private adversarial training, as presented in DP-Adv, outperforms the other state-of-the-art methods in performance, it lacks formal privacy guarantees and empirical validation. Thus, in this work, we benchmark the performance of this technique using a membership inference attack and empirically show that the resulting approach is as private as non-robust private models. This work also highlights the need to explore privacy guarantees in dynamic training paradigms.
Elevating Defenses: Bridging Adversarial Training and Watermarking for Model Resilience
Jan 07, 2024Machine learning models are being used in an increasing number of critical applications; thus, securing their integrity and ownership is critical. Recent studies observed that adversarial training and watermarking have a conflicting interaction. This work introduces a novel framework to integrate adversarial training with watermarking techniques to fortify against evasion attacks and provide confident model verification in case of intellectual property theft. We use adversarial training together with adversarial watermarks to train a robust watermarked model. The key intuition is to use a higher perturbation budget to generate adversarial watermarks compared to the budget used for adversarial training, thus avoiding conflict. We use the MNIST and Fashion-MNIST datasets to evaluate our proposed technique on various model stealing attacks. The results obtained consistently outperform the existing baseline in terms of robustness performance and further prove the resilience of this defense against pruning and fine-tuning removal attacks.
FedSpectral+: Spectral Clustering using Federated Learning
Feb 04, 2023Clustering in graphs has been a well-known research problem, particularly because most Internet and social network data is in the form of graphs. Organizations widely use spectral clustering algorithms to find clustering in graph datasets. However, applying spectral clustering to a large dataset is challenging due to computational overhead. While the distributed spectral clustering algorithm exists, they face the problem of data privacy and increased communication costs between the clients. Thus, in this paper, we propose a spectral clustering algorithm using federated learning (FL) to overcome these issues. FL is a privacy-protecting algorithm that accumulates model parameters from each local learner rather than collecting users' raw data, thus providing both scalability and data privacy. We developed two approaches: FedSpectral and FedSpectral+. FedSpectral is a baseline approach that uses local spectral clustering labels to aggregate the global spectral clustering by creating a similarity graph. FedSpectral+, a state-of-the-art approach, uses the power iteration method to learn the global spectral embedding by incorporating the entire graph data without access to the raw information distributed among the clients. We further designed our own similarity metric to check the clustering quality of the distributed approach to that of the original/non-FL clustering. The proposed approach FedSpectral+ obtained a similarity of 98.85% and 99.8%, comparable to that of global clustering on the ego-Facebook and email-Eu-core dataset.
k-Means SubClustering: A Differentially Private Algorithm with Improved Clustering Quality
Jan 07, 2023In today's data-driven world, the sensitivity of information has been a significant concern. With this data and additional information on the person's background, one can easily infer an individual's private data. Many differentially private iterative algorithms have been proposed in interactive settings to protect an individual's privacy from these inference attacks. The existing approaches adapt the method to compute differentially private(DP) centroids by iterative Llyod's algorithm and perturbing the centroid with various DP mechanisms. These DP mechanisms do not guarantee convergence of differentially private iterative algorithms and degrade the quality of the cluster. Thus, in this work, we further extend the previous work on 'Differentially Private k-Means Clustering With Convergence Guarantee' by taking it as our baseline. The novelty of our approach is to sub-cluster the clusters and then select the centroid which has a higher probability of moving in the direction of the future centroid. At every Lloyd's step, the centroids are injected with the noise using the exponential DP mechanism. The results of the experiments indicate that our approach outperforms the current state-of-the-art method, i.e., the baseline algorithm, in terms of clustering quality while maintaining the same differential privacy requirements. The clustering quality significantly improved by 4.13 and 2.83 times than baseline for the Wine and Breast_Cancer dataset, respectively.
Merged-GHCIDR: Geometrical Approach to Reduce Image Data
Sep 06, 2022
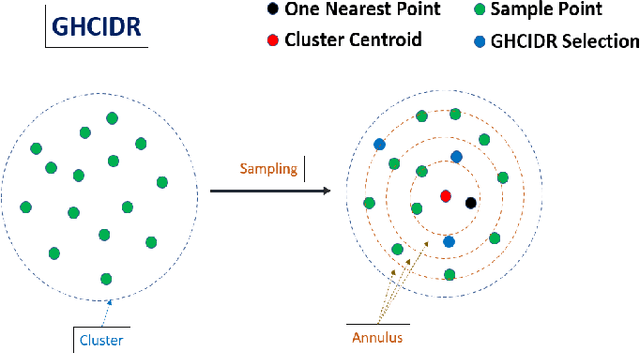
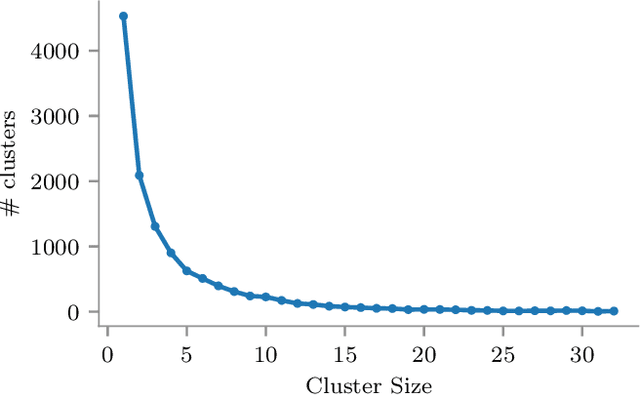
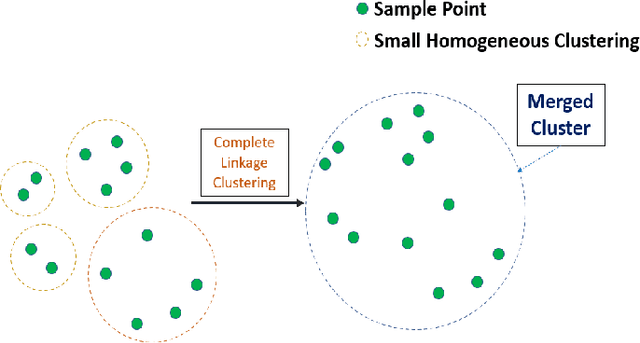
The computational resources required to train a model have been increasing since the inception of deep networks. Training neural networks on massive datasets have become a challenging and time-consuming task. So, there arises a need to reduce the dataset without compromising the accuracy. In this paper, we present novel variations of an earlier approach called reduction through homogeneous clustering for reducing dataset size. The proposed methods are based on the idea of partitioning the dataset into homogeneous clusters and selecting images that contribute significantly to the accuracy. We propose two variations: Geometrical Homogeneous Clustering for Image Data Reduction (GHCIDR) and Merged-GHCIDR upon the baseline algorithm - Reduction through Homogeneous Clustering (RHC) to achieve better accuracy and training time. The intuition behind GHCIDR involves selecting data points by cluster weights and geometrical distribution of the training set. Merged-GHCIDR involves merging clusters having the same labels using complete linkage clustering. We used three deep learning models- Fully Connected Networks (FCN), VGG1, and VGG16. We experimented with the two variants on four datasets- MNIST, CIFAR10, Fashion-MNIST, and Tiny-Imagenet. Merged-GHCIDR with the same percentage reduction as RHC showed an increase of 2.8%, 8.9%, 7.6% and 3.5% accuracy on MNIST, Fashion-MNIST, CIFAR10, and Tiny-Imagenet, respectively.
Geometrical Homogeneous Clustering for Image Data Reduction
Aug 27, 2022
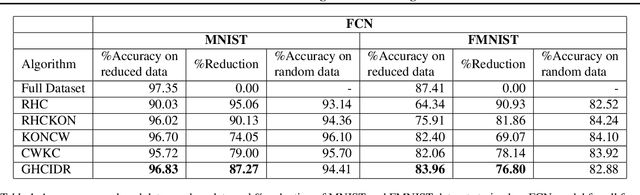
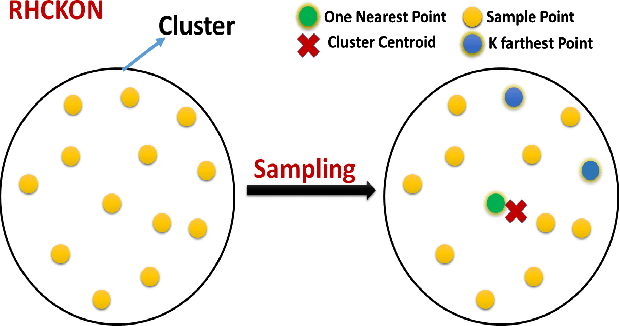
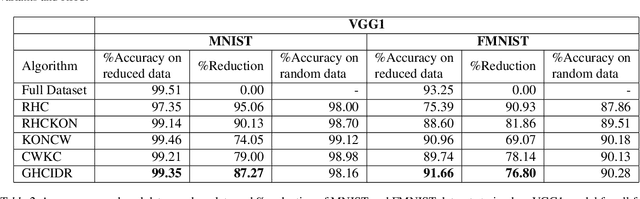
In this paper, we present novel variations of an earlier approach called homogeneous clustering algorithm for reducing dataset size. The intuition behind the approaches proposed in this paper is to partition the dataset into homogeneous clusters and select some images which contribute significantly to the accuracy. Selected images are the proper subset of the training data and thus are human-readable. We propose four variations upon the baseline algorithm-RHC. The intuition behind the first approach, RHCKON, is that the boundary points contribute significantly towards the representation of clusters. It involves selecting k farthest and one nearest neighbour of the centroid of the clusters. In the following two approaches (KONCW and CWKC), we introduce the concept of cluster weights. They are based on the fact that larger clusters contribute more than smaller sized clusters. The final variation is GHCIDR which selects points based on the geometrical aspect of data distribution. We performed the experiments on two deep learning models- Fully Connected Networks (FCN) and VGG1. We experimented with the four variants on three datasets- MNIST, CIFAR10, and Fashion-MNIST. We found that GHCIDR gave the best accuracy of 99.35%, 81.10%, and 91.66% and a training data reduction of 87.27%, 32.34%, and 76.80% on MNIST, CIFAR10, and Fashion-MNIST respectively.