 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSquint: Fast Visual Reinforcement Learning for Sim-to-Real Robotics
Feb 24, 2026Visual reinforcement learning is appealing for robotics but expensive -- off-policy methods are sample-efficient yet slow; on-policy methods parallelize well but waste samples. Recent work has shown that off-policy methods can train faster than on-policy methods in wall-clock time for state-based control. Extending this to vision remains challenging, where high-dimensional input images complicate training dynamics and introduce substantial storage and encoding overhead. To address these challenges, we introduce Squint, a visual Soft Actor Critic method that achieves faster wall-clock training than prior visual off-policy and on-policy methods. Squint achieves this via parallel simulation, a distributional critic, resolution squinting, layer normalization, a tuned update-to-data ratio, and an optimized implementation. We evaluate on the SO-101 Task Set, a new suite of eight manipulation tasks in ManiSkill3 with heavy domain randomization, and demonstrate sim-to-real transfer to a real SO-101 robot. We train policies for 15 minutes on a single RTX 3090 GPU, with most tasks converging in under 6 minutes.
Merging and Disentangling Views in Visual Reinforcement Learning for Robotic Manipulation
May 07, 2025Vision is well-known for its use in manipulation, especially using visual servoing. To make it robust, multiple cameras are needed to expand the field of view. That is computationally challenging. Merging multiple views and using Q-learning allows the design of more effective representations and optimization of sample efficiency. Such a solution might be expensive to deploy. To mitigate this, we introduce a Merge And Disentanglement (MAD) algorithm that efficiently merges views to increase sample efficiency while augmenting with single-view features to allow lightweight deployment and ensure robust policies. We demonstrate the efficiency and robustness of our approach using Meta-World and ManiSkill3. For project website and code, see https://aalmuzairee.github.io/mad
A Recipe for Unbounded Data Augmentation in Visual Reinforcement Learning
May 27, 2024



$Q$-learning algorithms are appealing for real-world applications due to their data-efficiency, but they are very prone to overfitting and training instabilities when trained from visual observations. Prior work, namely SVEA, finds that selective application of data augmentation can improve the visual generalization of RL agents without destabilizing training. We revisit its recipe for data augmentation, and find an assumption that limits its effectiveness to augmentations of a photometric nature. Addressing these limitations, we propose a generalized recipe, SADA, that works with wider varieties of augmentations. We benchmark its effectiveness on DMC-GB2 -- our proposed extension of the popular DMControl Generalization Benchmark -- as well as tasks from Meta-World and the Distracting Control Suite, and find that our method, SADA, greatly improves training stability and generalization of RL agents across a diverse set of augmentations. Visualizations, code, and benchmark: see https://aalmuzairee.github.io/SADA/
X-Align++: cross-modal cross-view alignment for Bird's-eye-view segmentation
Jun 06, 2023Bird's-eye-view (BEV) grid is a typical representation of the perception of road components, e.g., drivable area, in autonomous driving. Most existing approaches rely on cameras only to perform segmentation in BEV space, which is fundamentally constrained by the absence of reliable depth information. The latest works leverage both camera and LiDAR modalities but suboptimally fuse their features using simple, concatenation-based mechanisms. In this paper, we address these problems by enhancing the alignment of the unimodal features in order to aid feature fusion, as well as enhancing the alignment between the cameras' perspective view (PV) and BEV representations. We propose X-Align, a novel end-to-end cross-modal and cross-view learning framework for BEV segmentation consisting of the following components: (i) a novel Cross-Modal Feature Alignment (X-FA) loss, (ii) an attention-based Cross-Modal Feature Fusion (X-FF) module to align multi-modal BEV features implicitly, and (iii) an auxiliary PV segmentation branch with Cross-View Segmentation Alignment (X-SA) losses to improve the PV-to-BEV transformation. We evaluate our proposed method across two commonly used benchmark datasets, i.e., nuScenes and KITTI-360. Notably, X-Align significantly outperforms the state-of-the-art by 3 absolute mIoU points on nuScenes. We also provide extensive ablation studies to demonstrate the effectiveness of the individual components.
X-Align: Cross-Modal Cross-View Alignment for Bird's-Eye-View Segmentation
Oct 13, 2022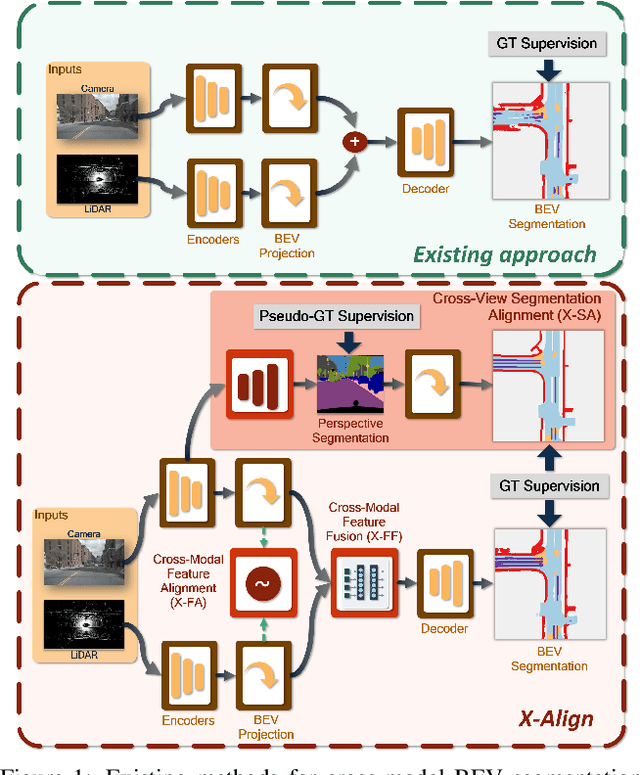
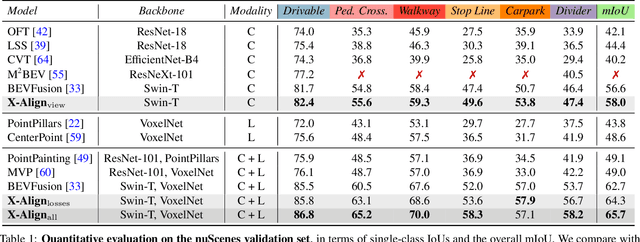
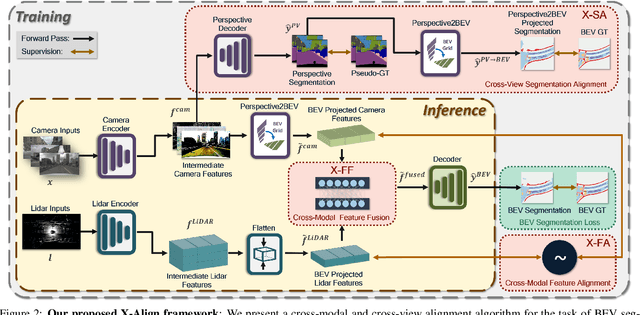

Bird's-eye-view (BEV) grid is a common representation for the perception of road components, e.g., drivable area, in autonomous driving. Most existing approaches rely on cameras only to perform segmentation in BEV space, which is fundamentally constrained by the absence of reliable depth information. Latest works leverage both camera and LiDAR modalities, but sub-optimally fuse their features using simple, concatenation-based mechanisms. In this paper, we address these problems by enhancing the alignment of the unimodal features in order to aid feature fusion, as well as enhancing the alignment between the cameras' perspective view (PV) and BEV representations. We propose X-Align, a novel end-to-end cross-modal and cross-view learning framework for BEV segmentation consisting of the following components: (i) a novel Cross-Modal Feature Alignment (X-FA) loss, (ii) an attention-based Cross-Modal Feature Fusion (X-FF) module to align multi-modal BEV features implicitly, and (iii) an auxiliary PV segmentation branch with Cross-View Segmentation Alignment (X-SA) losses to improve the PV-to-BEV transformation. We evaluate our proposed method across two commonly used benchmark datasets, i.e., nuScenes and KITTI-360. Notably, X-Align significantly outperforms the state-of-the-art by 3 absolute mIoU points on nuScenes. We also provide extensive ablation studies to demonstrate the effectiveness of the individual components.