 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrating Explore-Exploit Trade-off for Fair Online Learning to Rank
Paper and Code
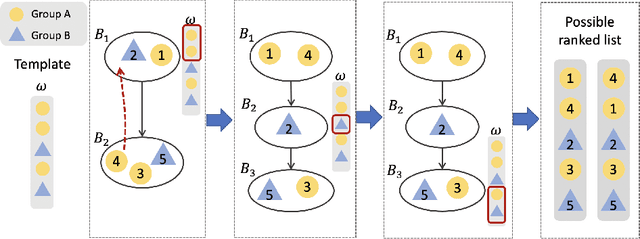
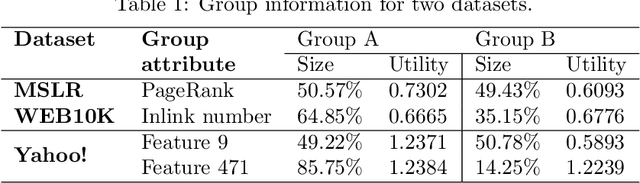


Online learning to rank (OL2R) has attracted great research interests in recent years, thanks to its advantages in avoiding expensive relevance labeling as required in offline supervised ranking model learning. Such a solution explores the unknowns (e.g., intentionally present selected results on top positions) to improve its relevance estimation. This however triggers concerns on its ranking fairness: different groups of items might receive differential treatments during the course of OL2R. But existing fair ranking solutions usually require the knowledge of result relevance or a performing ranker beforehand, which contradicts with the setting of OL2R and thus cannot be directly applied to guarantee fairness. In this work, we propose a general framework to achieve fairness defined by group exposure in OL2R. The key idea is to calibrate exploration and exploitation for fairness control, relevance learning and online ranking quality. In particular, when the model is exploring a set of results for relevance feedback, we confine the exploration within a subset of random permutations, where fairness across groups is maintained while the feedback is still unbiased. Theoretically we prove such a strategy introduces minimum distortion in OL2R's regret to obtain fairness. Extensive empirical analysis is performed on two public learning to rank benchmark datasets to demonstrate the effectiveness of the proposed solution compared to existing fair OL2R solutions.