 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Neural Ranking Models Online from Implicit User Feedback
Paper and Code
Jan 17, 2022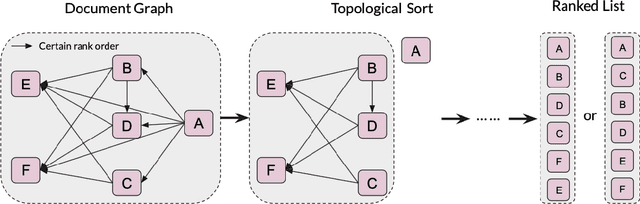
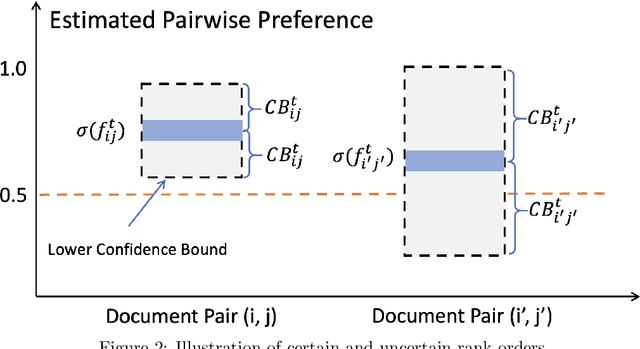

Existing online learning to rank (OL2R) solutions are limited to linear models, which are incompetent to capture possible non-linear relations between queries and documents. In this work, to unleash the power of representation learning in OL2R, we propose to directly learn a neural ranking model from users' implicit feedback (e.g., clicks) collected on the fly. We focus on RankNet and LambdaRank, due to their great empirical success and wide adoption in offline settings, and control the notorious explore-exploit trade-off based on the convergence analysis of neural networks using neural tangent kernel. Specifically, in each round of result serving, exploration is only performed on document pairs where the predicted rank order between the two documents is uncertain; otherwise, the ranker's predicted order will be followed in result ranking. We prove that under standard assumptions our OL2R solution achieves a gap-dependent upper regret bound of $O(\log^2(T))$, in which the regret is defined on the total number of mis-ordered pairs over $T$ rounds. Comparisons against an extensive set of state-of-the-art OL2R baselines on two public learning to rank benchmark datasets demonstrate the effectiveness of the proposed solution.