 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Construction of Theme-specific Knowledge Graphs
Paper and Code
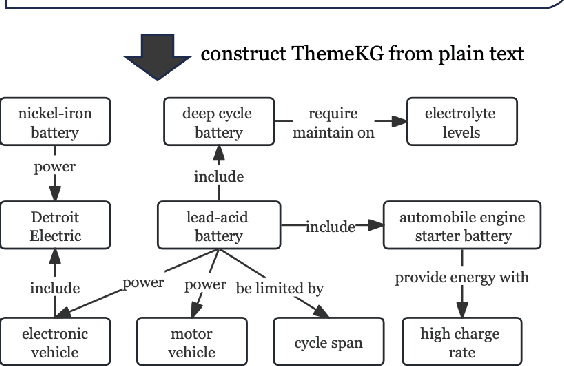
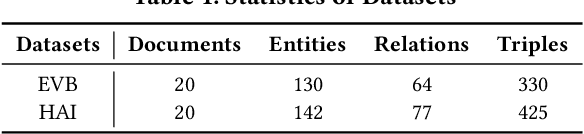
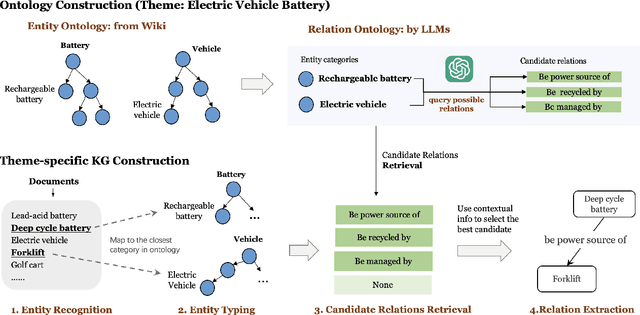
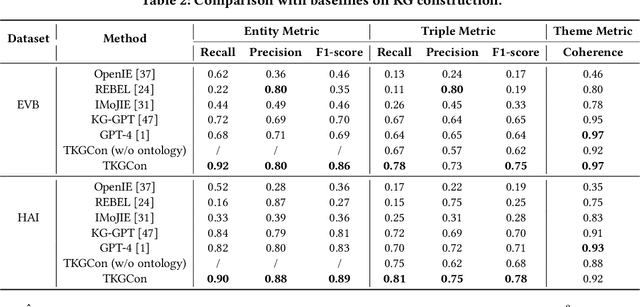
Despite widespread applications of knowledge graphs (KGs) in various tasks such as question answering and intelligent conversational systems, existing KGs face two major challenges: information granularity and deficiency in timeliness. These hinder considerably the retrieval and analysis of in-context, fine-grained, and up-to-date knowledge from KGs, particularly in highly specialized themes (e.g., specialized scientific research) and rapidly evolving contexts (e.g., breaking news or disaster tracking). To tackle such challenges, we propose a theme-specific knowledge graph (i.e., ThemeKG), a KG constructed from a theme-specific corpus, and design an unsupervised framework for ThemeKG construction (named TKGCon). The framework takes raw theme-specific corpus and generates a high-quality KG that includes salient entities and relations under the theme. Specifically, we start with an entity ontology of the theme from Wikipedia, based on which we then generate candidate relations by Large Language Models (LLMs) to construct a relation ontology. To parse the documents from the theme corpus, we first map the extracted entity pairs to the ontology and retrieve the candidate relations. Finally, we incorporate the context and ontology to consolidate the relations for entity pairs. We observe that directly prompting GPT-4 for theme-specific KG leads to inaccurate entities (such as "two main types" as one entity in the query result) and unclear (such as "is", "has") or wrong relations (such as "have due to", "to start"). In contrast, by constructing the theme-specific KG step by step, our model outperforms GPT-4 and could consistently identify accurate entities and relations. Experimental results also show that our framework excels in evaluations compared with various KG construction baselines.