 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey on Data-Efficient GANs in Image Generation
Paper and Code
Apr 18, 2022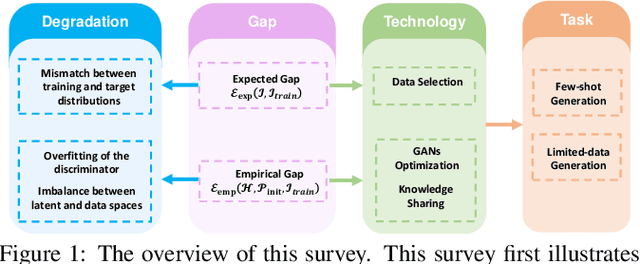
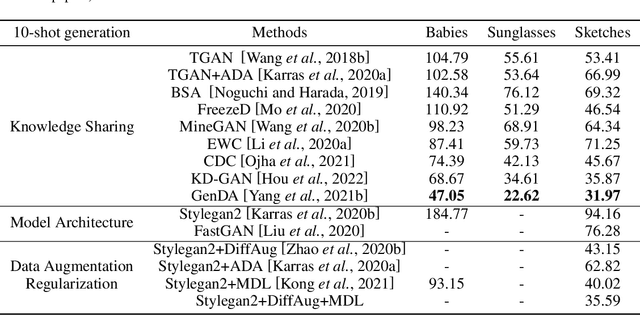
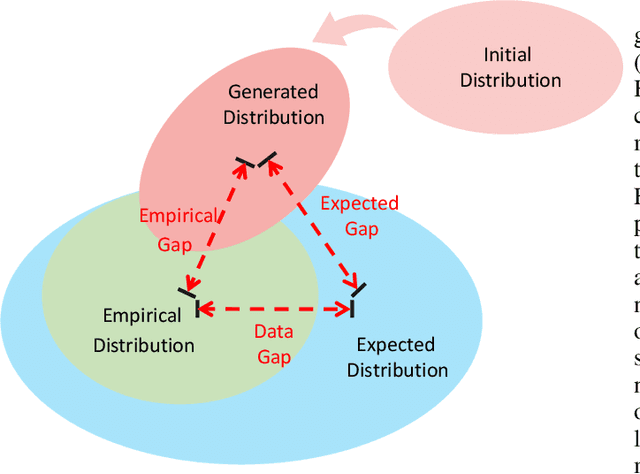
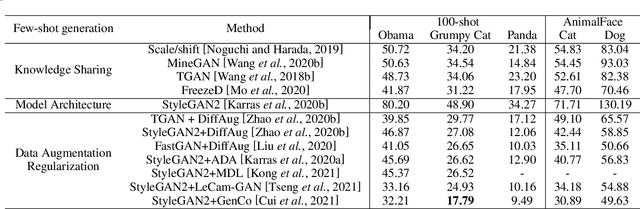
Generative Adversarial Networks (GANs) have achieved remarkable achievements in image synthesis. These successes of GANs rely on large scale datasets, requiring too much cost. With limited training data, how to stable the training process of GANs and generate realistic images have attracted more attention. The challenges of Data-Efficient GANs (DE-GANs) mainly arise from three aspects: (i) Mismatch Between Training and Target Distributions, (ii) Overfitting of the Discriminator, and (iii) Imbalance Between Latent and Data Spaces. Although many augmentation and pre-training strategies have been proposed to alleviate these issues, there lacks a systematic survey to summarize the properties, challenges, and solutions of DE-GANs. In this paper, we revisit and define DE-GANs from the perspective of distribution optimization. We conclude and analyze the challenges of DE-GANs. Meanwhile, we propose a taxonomy, which classifies the existing methods into three categories: Data Selection, GANs Optimization, and Knowledge Sharing. Last but not the least, we attempt to highlight the current problems and the future directions.