 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Quantization-aware Training of Low-Precision Network via Block Replacement on Full-Precision Counterpart
Dec 20, 2024Quantization-aware training (QAT) is a common paradigm for network quantization, in which the training phase incorporates the simulation of the low-precision computation to optimize the quantization parameters in alignment with the task goals. However, direct training of low-precision networks generally faces two obstacles: 1. The low-precision model exhibits limited representation capabilities and cannot directly replicate full-precision calculations, which constitutes a deficiency compared to full-precision alternatives; 2. Non-ideal deviations during gradient propagation are a common consequence of employing pseudo-gradients as approximations in derived quantized functions. In this paper, we propose a general QAT framework for alleviating the aforementioned concerns by permitting the forward and backward processes of the low-precision network to be guided by the full-precision partner during training. In conjunction with the direct training of the quantization model, intermediate mixed-precision models are generated through the block-by-block replacement on the full-precision model and working simultaneously with the low-precision backbone, which enables the integration of quantized low-precision blocks into full-precision networks throughout the training phase. Consequently, each quantized block is capable of: 1. simulating full-precision representation during forward passes; 2. obtaining gradients with improved estimation during backward passes. We demonstrate that the proposed method achieves state-of-the-art results for 4-, 3-, and 2-bit quantization on ImageNet and CIFAR-10. The proposed framework provides a compatible extension for most QAT methods and only requires a concise wrapper for existing codes.
Decoupling Dark Knowledge via Block-wise Logit Distillation for Feature-level Alignment
Nov 03, 2024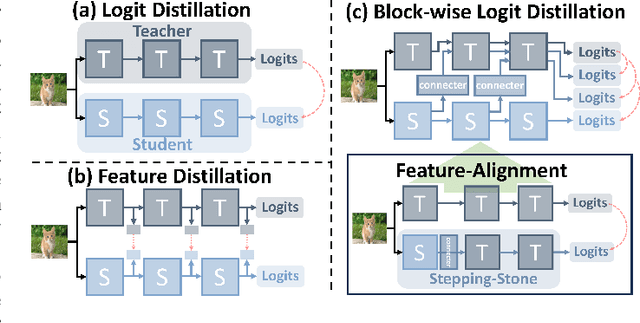
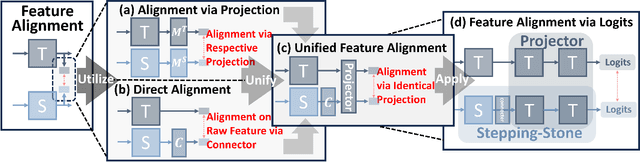
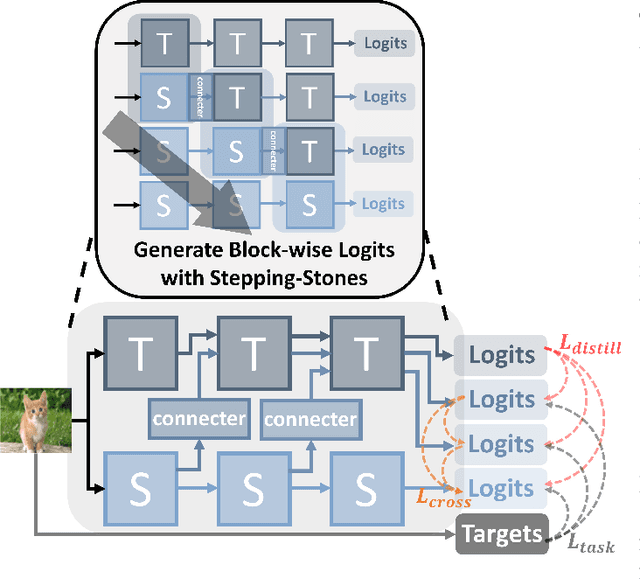
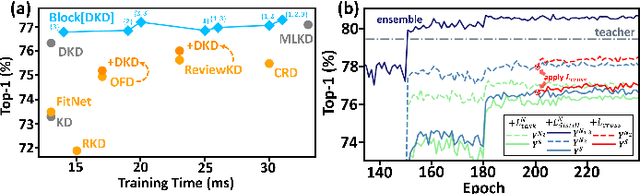
Knowledge Distillation (KD), a learning manner with a larger teacher network guiding a smaller student network, transfers dark knowledge from the teacher to the student via logits or intermediate features, with the aim of producing a well-performed lightweight model. Notably, many subsequent feature-based KD methods outperformed the earliest logit-based KD method and iteratively generated numerous state-of-the-art distillation methods. Nevertheless, recent work has uncovered the potential of the logit-based method, bringing the simple KD form based on logits back into the limelight. Features or logits? They partially implement the KD with entirely distinct perspectives; therefore, choosing between logits and features is not straightforward. This paper provides a unified perspective of feature alignment in order to obtain a better comprehension of their fundamental distinction. Inheriting the design philosophy and insights of feature-based and logit-based methods, we introduce a block-wise logit distillation framework to apply implicit logit-based feature alignment by gradually replacing teacher's blocks as intermediate stepping-stone models to bridge the gap between the student and the teacher. Our method obtains comparable or superior results to state-of-the-art distillation methods. This paper demonstrates the great potential of combining logit and features, and we hope it will inspire future research to revisit KD from a higher vantage point.
Go beyond End-to-End Training: Boosting Greedy Local Learning with Context Supply
Dec 12, 2023



Traditional end-to-end (E2E) training of deep networks necessitates storing intermediate activations for back-propagation, resulting in a large memory footprint on GPUs and restricted model parallelization. As an alternative, greedy local learning partitions the network into gradient-isolated modules and trains supervisely based on local preliminary losses, thereby providing asynchronous and parallel training methods that substantially reduce memory cost. However, empirical experiments reveal that as the number of segmentations of the gradient-isolated module increases, the performance of the local learning scheme degrades substantially, severely limiting its expansibility. To avoid this issue, we theoretically analyze the greedy local learning from the standpoint of information theory and propose a ContSup scheme, which incorporates context supply between isolated modules to compensate for information loss. Experiments on benchmark datasets (i.e. CIFAR, SVHN, STL-10) achieve SOTA results and indicate that our proposed method can significantly improve the performance of greedy local learning with minimal memory and computational overhead, allowing for the boost of the number of isolated modules. Our codes are available at https://github.com/Tab-ct/ContSup.