 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Quantization-aware Training of Low-Precision Network via Block Replacement on Full-Precision Counterpart
Dec 20, 2024Quantization-aware training (QAT) is a common paradigm for network quantization, in which the training phase incorporates the simulation of the low-precision computation to optimize the quantization parameters in alignment with the task goals. However, direct training of low-precision networks generally faces two obstacles: 1. The low-precision model exhibits limited representation capabilities and cannot directly replicate full-precision calculations, which constitutes a deficiency compared to full-precision alternatives; 2. Non-ideal deviations during gradient propagation are a common consequence of employing pseudo-gradients as approximations in derived quantized functions. In this paper, we propose a general QAT framework for alleviating the aforementioned concerns by permitting the forward and backward processes of the low-precision network to be guided by the full-precision partner during training. In conjunction with the direct training of the quantization model, intermediate mixed-precision models are generated through the block-by-block replacement on the full-precision model and working simultaneously with the low-precision backbone, which enables the integration of quantized low-precision blocks into full-precision networks throughout the training phase. Consequently, each quantized block is capable of: 1. simulating full-precision representation during forward passes; 2. obtaining gradients with improved estimation during backward passes. We demonstrate that the proposed method achieves state-of-the-art results for 4-, 3-, and 2-bit quantization on ImageNet and CIFAR-10. The proposed framework provides a compatible extension for most QAT methods and only requires a concise wrapper for existing codes.
Decoupling Dark Knowledge via Block-wise Logit Distillation for Feature-level Alignment
Nov 03, 2024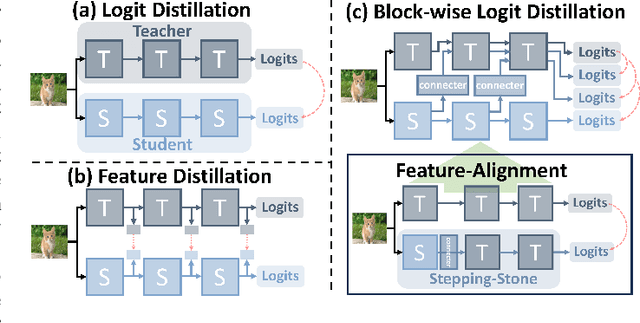
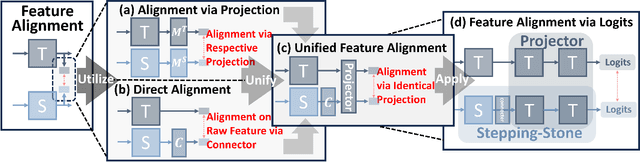
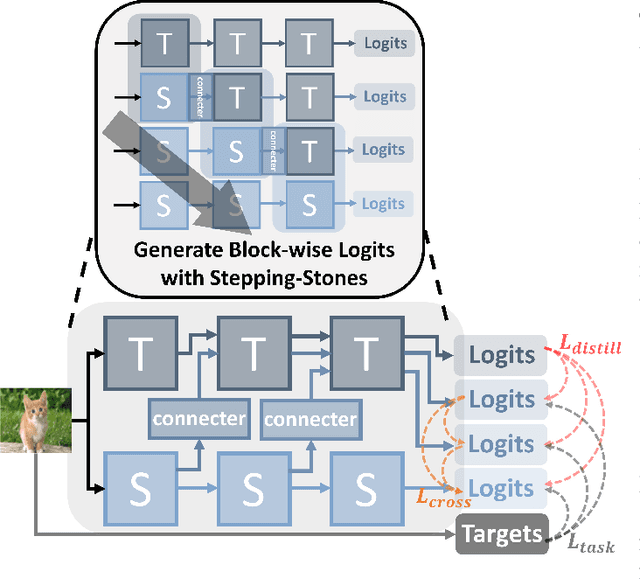
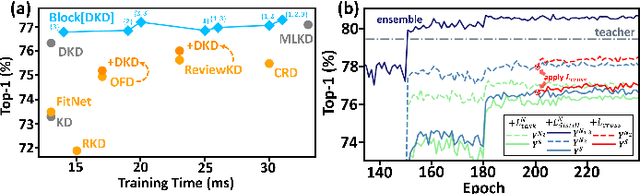
Knowledge Distillation (KD), a learning manner with a larger teacher network guiding a smaller student network, transfers dark knowledge from the teacher to the student via logits or intermediate features, with the aim of producing a well-performed lightweight model. Notably, many subsequent feature-based KD methods outperformed the earliest logit-based KD method and iteratively generated numerous state-of-the-art distillation methods. Nevertheless, recent work has uncovered the potential of the logit-based method, bringing the simple KD form based on logits back into the limelight. Features or logits? They partially implement the KD with entirely distinct perspectives; therefore, choosing between logits and features is not straightforward. This paper provides a unified perspective of feature alignment in order to obtain a better comprehension of their fundamental distinction. Inheriting the design philosophy and insights of feature-based and logit-based methods, we introduce a block-wise logit distillation framework to apply implicit logit-based feature alignment by gradually replacing teacher's blocks as intermediate stepping-stone models to bridge the gap between the student and the teacher. Our method obtains comparable or superior results to state-of-the-art distillation methods. This paper demonstrates the great potential of combining logit and features, and we hope it will inspire future research to revisit KD from a higher vantage point.
SDiT: Spiking Diffusion Model with Transformer
Feb 24, 2024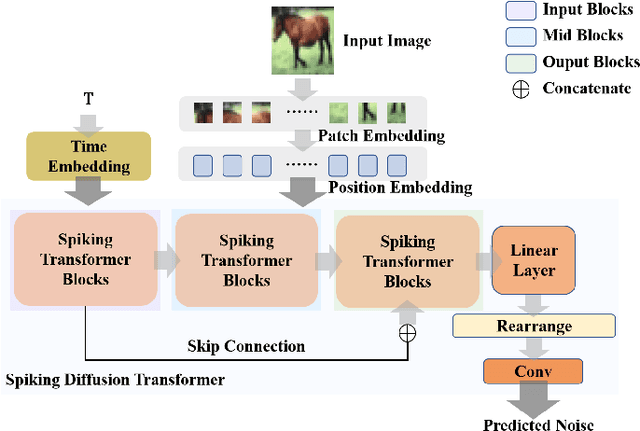



Spiking neural networks (SNNs) have low power consumption and bio-interpretable characteristics, and are considered to have tremendous potential for energy-efficient computing. However, the exploration of SNNs on image generation tasks remains very limited, and a unified and effective structure for SNN-based generative models has yet to be proposed. In this paper, we explore a novel diffusion model architecture within spiking neural networks. We utilize transformer to replace the commonly used U-net structure in mainstream diffusion models. It can generate higher quality images with relatively lower computational cost and shorter sampling time. It aims to provide an empirical baseline for research of generative models based on SNNs. Experiments on MNIST, Fashion-MNIST, and CIFAR-10 datasets demonstrate that our work is highly competitive compared to existing SNN generative models.
An Electromagnetic-Information-Theory Based Model for Efficient Characterization of MIMO Systems in Complex Space
Jan 13, 2023



It is the pursuit of a multiple-input-multiple-output (MIMO) system to approach and even break the limit of channel capacity. However, it is always a big challenge to efficiently characterize the MIMO systems in complex space and get better propagation performance than the conventional MIMO systems considering only free space, which is important for guiding the power and phase allocation of antenna units. In this manuscript, an Electromagnetic-Information-Theory (EMIT) based model is developed for efficient characterization of MIMO systems in complex space. The group-T-matrix-based multiple scattering fast algorithm, the mode-decomposition-based characterization method, and their joint theoretical framework in complex space are discussed. Firstly, key informatics parameters in free electromagnetic space based on a dyadic Green's function are derived. Next, a novel group-T-matrix-based multiple scattering fast algorithm is developed to describe a representative inhomogeneous electromagnetic space. All the analytical results are validated by simulations. In addition, the complete form of the EMIT-based model is proposed to derive the informatics parameters frequently used in electromagnetic propagation, through integrating the mode analysis method with the dyadic Green's function matrix. Finally, as a proof-or-concept, microwave anechoic chamber measurements of a cylindrical array is performed, demonstrating the effectiveness of the EMIT-based model. Meanwhile, a case of image transmission with limited power is presented to illustrate how to use this EMIT-based model to guide the power and phase allocation of antenna units for real MIMO applications.
* 13 pages, 14 figures