 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of GPT-4 for chest X-ray impression generation: A reader study on performance and perception
Paper and Code
Nov 12, 2023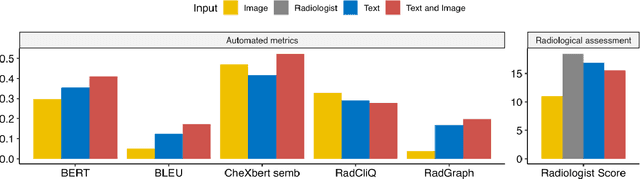
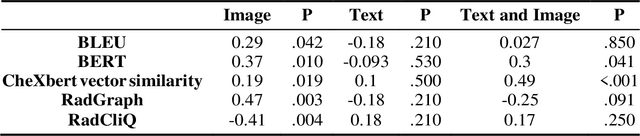
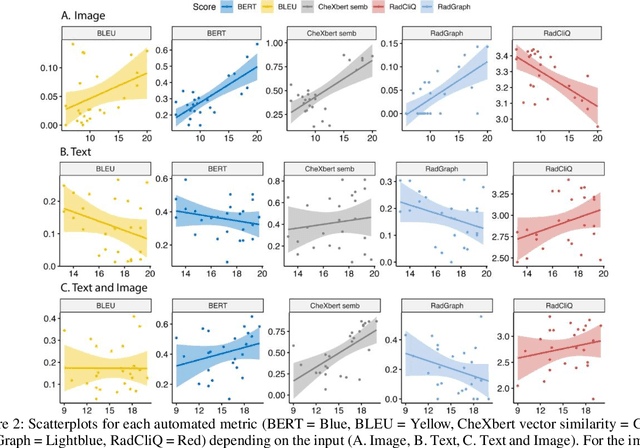
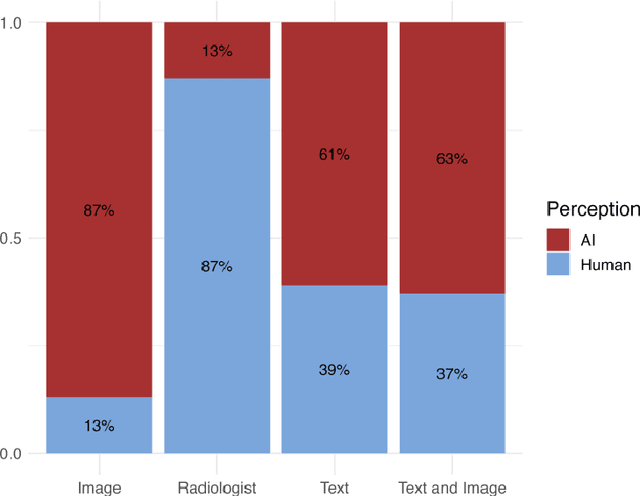
The remarkable generative capabilities of multimodal foundation models are currently being explored for a variety of applications. Generating radiological impressions is a challenging task that could significantly reduce the workload of radiologists. In our study we explored and analyzed the generative abilities of GPT-4 for Chest X-ray impression generation. To generate and evaluate impressions of chest X-rays based on different input modalities (image, text, text and image), a blinded radiological report was written for 25-cases of the publicly available NIH-dataset. GPT-4 was given image, finding section or both sequentially to generate an input dependent impression. In a blind randomized reading, 4-radiologists rated the impressions and were asked to classify the impression origin (Human, AI), providing justification for their decision. Lastly text model evaluation metrics and their correlation with the radiological score (summation of the 4 dimensions) was assessed. According to the radiological score, the human-written impression was rated highest, although not significantly different to text-based impressions. The automated evaluation metrics showed moderate to substantial correlations to the radiological score for the image impressions, however individual scores were highly divergent among inputs, indicating insufficient representation of radiological quality. Detection of AI-generated impressions varied by input and was 61% for text-based impressions. Impressions classified as AI-generated had significantly worse radiological scores even when written by a radiologist, indicating potential bias. Our study revealed significant discrepancies between a radiological assessment and common automatic evaluation metrics depending on the model input. The detection of AI-generated findings is subject to bias that highly rated impressions are perceived as human-written.