 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Gap: Conformative Decoding to Improve Output Diversity of Instruction-Tuned Large Language Models
Jul 28, 2025Instruction-tuning large language models (LLMs) reduces the diversity of their outputs, which has implications for many tasks, particularly for creative tasks. This paper investigates the ``diversity gap'' for a writing prompt narrative generation task. This gap emerges as measured by current diversity metrics for various open-weight and open-source LLMs. The results show significant decreases in diversity due to instruction-tuning. We explore the diversity loss at each fine-tuning stage for the OLMo and OLMo 2 models to further understand how output diversity is affected. The results indicate that DPO has the most substantial impact on diversity. Motivated by these findings, we present a new decoding strategy, conformative decoding, which guides an instruct model using its more diverse base model to reintroduce output diversity. We show that conformative decoding typically increases diversity and even maintains or improves quality.
Probing Vision-Language Understanding through the Visual Entailment Task: promises and pitfalls
Jul 23, 2025This study investigates the extent to which the Visual Entailment (VE) task serves as a reliable probe of vision-language understanding in multimodal language models, using the LLaMA 3.2 11B Vision model as a test case. Beyond reporting performance metrics, we aim to interpret what these results reveal about the underlying possibilities and limitations of the VE task. We conduct a series of experiments across zero-shot, few-shot, and fine-tuning settings, exploring how factors such as prompt design, the number and order of in-context examples and access to visual information might affect VE performance. To further probe the reasoning processes of the model, we used explanation-based evaluations. Results indicate that three-shot inference outperforms the zero-shot baselines. However, additional examples introduce more noise than they provide benefits. Additionally, the order of the labels in the prompt is a critical factor that influences the predictions. In the absence of visual information, the model has a strong tendency to hallucinate and imagine content, raising questions about the model's over-reliance on linguistic priors. Fine-tuning yields strong results, achieving an accuracy of 83.3% on the e-SNLI-VE dataset and outperforming the state-of-the-art OFA-X model. Additionally, the explanation evaluation demonstrates that the fine-tuned model provides semantically meaningful explanations similar to those of humans, with a BERTScore F1-score of 89.2%. We do, however, find comparable BERTScore results in experiments with limited vision, questioning the visual grounding of this task. Overall, our results highlight both the utility and limitations of VE as a diagnostic task for vision-language understanding and point to directions for refining multimodal evaluation methods.
Shaping Shared Languages: Human and Large Language Models' Inductive Biases in Emergent Communication
Mar 06, 2025



Languages are shaped by the inductive biases of their users. Using a classical referential game, we investigate how artificial languages evolve when optimised for inductive biases in humans and large language models (LLMs) via Human-Human, LLM-LLM and Human-LLM experiments. We show that referentially grounded vocabularies emerge that enable reliable communication in all conditions, even when humans and LLMs collaborate. Comparisons between conditions reveal that languages optimised for LLMs subtly differ from those optimised for humans. Interestingly, interactions between humans and LLMs alleviate these differences and result in vocabularies which are more human-like than LLM-like. These findings advance our understanding of how inductive biases in LLMs play a role in the dynamic nature of human language and contribute to maintaining alignment in human and machine communication. In particular, our work underscores the need to think of new methods that include human interaction in the training processes of LLMs, and shows that using communicative success as a reward signal can be a fruitful, novel direction.
Searching for Structure: Investigating Emergent Communication with Large Language Models
Dec 10, 2024



Human languages have evolved to be structured through repeated language learning and use. These processes introduce biases that operate during language acquisition and shape linguistic systems toward communicative efficiency. In this paper, we investigate whether the same happens if artificial languages are optimised for implicit biases of Large Language Models (LLMs). To this end, we simulate a classical referential game in which LLMs learn and use artificial languages. Our results show that initially unstructured holistic languages are indeed shaped to have some structural properties that allow two LLM agents to communicate successfully. Similar to observations in human experiments, generational transmission increases the learnability of languages, but can at the same time result in non-humanlike degenerate vocabularies. Taken together, this work extends experimental findings, shows that LLMs can be used as tools in simulations of language evolution, and opens possibilities for future human-machine experiments in this field.
What does Kiki look like? Cross-modal associations between speech sounds and visual shapes in vision-and-language models
Jul 25, 2024



Humans have clear cross-modal preferences when matching certain novel words to visual shapes. Evidence suggests that these preferences play a prominent role in our linguistic processing, language learning, and the origins of signal-meaning mappings. With the rise of multimodal models in AI, such as vision- and-language (VLM) models, it becomes increasingly important to uncover the kinds of visio-linguistic associations these models encode and whether they align with human representations. Informed by experiments with humans, we probe and compare four VLMs for a well-known human cross-modal preference, the bouba-kiki effect. We do not find conclusive evidence for this effect but suggest that results may depend on features of the models, such as architecture design, model size, and training details. Our findings inform discussions on the origins of the bouba-kiki effect in human cognition and future developments of VLMs that align well with human cross-modal associations.
The Curious Case of Representational Alignment: Unravelling Visio-Linguistic Tasks in Emergent Communication
Jul 25, 2024Natural language has the universal properties of being compositional and grounded in reality. The emergence of linguistic properties is often investigated through simulations of emergent communication in referential games. However, these experiments have yielded mixed results compared to similar experiments addressing linguistic properties of human language. Here we address representational alignment as a potential contributing factor to these results. Specifically, we assess the representational alignment between agent image representations and between agent representations and input images. Doing so, we confirm that the emergent language does not appear to encode human-like conceptual visual features, since agent image representations drift away from inputs whilst inter-agent alignment increases. We moreover identify a strong relationship between inter-agent alignment and topographic similarity, a common metric for compositionality, and address its consequences. To address these issues, we introduce an alignment penalty that prevents representational drift but interestingly does not improve performance on a compositional discrimination task. Together, our findings emphasise the key role representational alignment plays in simulations of language emergence.
Is Temperature the Creativity Parameter of Large Language Models?
May 01, 2024Large language models (LLMs) are applied to all sorts of creative tasks, and their outputs vary from beautiful, to peculiar, to pastiche, into plain plagiarism. The temperature parameter of an LLM regulates the amount of randomness, leading to more diverse outputs; therefore, it is often claimed to be the creativity parameter. Here, we investigate this claim using a narrative generation task with a predetermined fixed context, model and prompt. Specifically, we present an empirical analysis of the LLM output for different temperature values using four necessary conditions for creativity in narrative generation: novelty, typicality, cohesion, and coherence. We find that temperature is weakly correlated with novelty, and unsurprisingly, moderately correlated with incoherence, but there is no relationship with either cohesion or typicality. However, the influence of temperature on creativity is far more nuanced and weak than suggested by the "creativity parameter" claim; overall results suggest that the LLM generates slightly more novel outputs as temperatures get higher. Finally, we discuss ideas to allow more controlled LLM creativity, rather than relying on chance via changing the temperature parameter.
Memory-Augmented Generative Adversarial Transformers
Feb 29, 2024

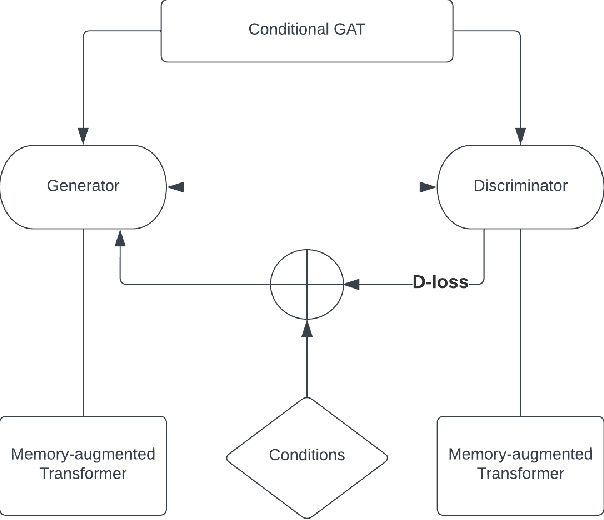

Conversational AI systems that rely on Large Language Models, like Transformers, have difficulty interweaving external data (like facts) with the language they generate. Vanilla Transformer architectures are not designed for answering factual questions with high accuracy. This paper investigates a possible route for addressing this problem. We propose to extend the standard Transformer architecture with an additional memory bank holding extra information (such as facts drawn from a knowledge base), and an extra attention layer for addressing this memory. We add this augmented memory to a Generative Adversarial Network-inspired Transformer architecture. This setup allows for implementing arbitrary felicity conditions on the generated language of the Transformer. We first demonstrate how this machinery can be deployed for handling factual questions in goal-oriented dialogues. Secondly, we demonstrate that our approach can be useful for applications like {\it style adaptation} as well: the adaptation of utterances according to certain stylistic (external) constraints, like social properties of human interlocutors in dialogues.
EduGym: An Environment Suite for Reinforcement Learning Education
Nov 17, 2023Due to the empirical success of reinforcement learning, an increasing number of students study the subject. However, from our practical teaching experience, we see students entering the field (bachelor, master and early PhD) often struggle. On the one hand, textbooks and (online) lectures provide the fundamentals, but students find it hard to translate between equations and code. On the other hand, public codebases do provide practical examples, but the implemented algorithms tend to be complex, and the underlying test environments contain multiple reinforcement learning challenges at once. Although this is realistic from a research perspective, it often hinders educational conceptual understanding. To solve this issue we introduce EduGym, a set of educational reinforcement learning environments and associated interactive notebooks tailored for education. Each EduGym environment is specifically designed to illustrate a certain aspect/challenge of reinforcement learning (e.g., exploration, partial observability, stochasticity, etc.), while the associated interactive notebook explains the challenge and its possible solution approaches, connecting equations and code in a single document. An evaluation among RL students and researchers shows 86% of them think EduGym is a useful tool for reinforcement learning education. All notebooks are available from https://sites.google.com/view/edu-gym/home, while the full software package can be installed from https://github.com/RLG-Leiden/edugym.
Large Language Models: The Need for Nuance in Current Debates and a Pragmatic Perspective on Understanding
Oct 31, 2023Current Large Language Models (LLMs) are unparalleled in their ability to generate grammatically correct, fluent text. LLMs are appearing rapidly, and debates on LLM capacities have taken off, but reflection is lagging behind. Thus, in this position paper, we first zoom in on the debate and critically assess three points recurring in critiques of LLM capacities: i) that LLMs only parrot statistical patterns in the training data; ii) that LLMs master formal but not functional language competence; and iii) that language learning in LLMs cannot inform human language learning. Drawing on empirical and theoretical arguments, we show that these points need more nuance. Second, we outline a pragmatic perspective on the issue of `real' understanding and intentionality in LLMs. Understanding and intentionality pertain to unobservable mental states we attribute to other humans because they have pragmatic value: they allow us to abstract away from complex underlying mechanics and predict behaviour effectively. We reflect on the circumstances under which it would make sense for humans to similarly attribute mental states to LLMs, thereby outlining a pragmatic philosophical context for LLMs as an increasingly prominent technology in society.