 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Augmented Generative Adversarial Transformers
Feb 29, 2024

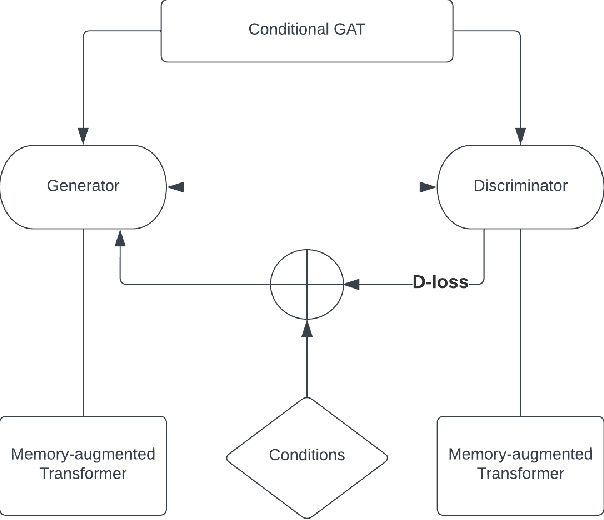

Conversational AI systems that rely on Large Language Models, like Transformers, have difficulty interweaving external data (like facts) with the language they generate. Vanilla Transformer architectures are not designed for answering factual questions with high accuracy. This paper investigates a possible route for addressing this problem. We propose to extend the standard Transformer architecture with an additional memory bank holding extra information (such as facts drawn from a knowledge base), and an extra attention layer for addressing this memory. We add this augmented memory to a Generative Adversarial Network-inspired Transformer architecture. This setup allows for implementing arbitrary felicity conditions on the generated language of the Transformer. We first demonstrate how this machinery can be deployed for handling factual questions in goal-oriented dialogues. Secondly, we demonstrate that our approach can be useful for applications like {\it style adaptation} as well: the adaptation of utterances according to certain stylistic (external) constraints, like social properties of human interlocutors in dialogues.
Gender prediction using limited Twitter Data
Sep 29, 2020
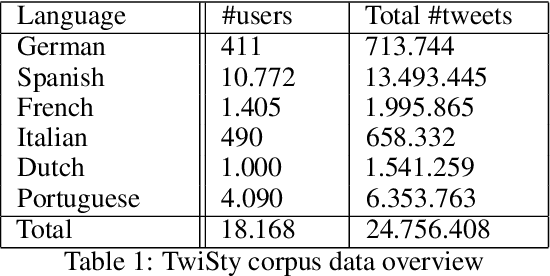
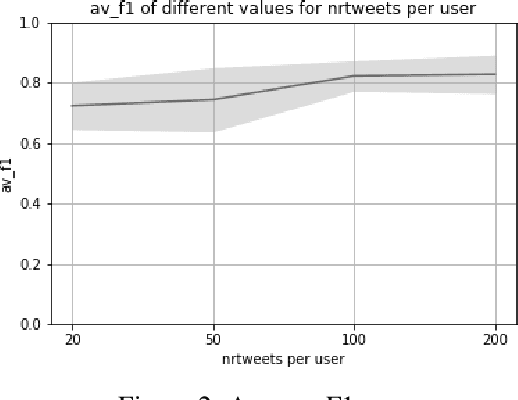
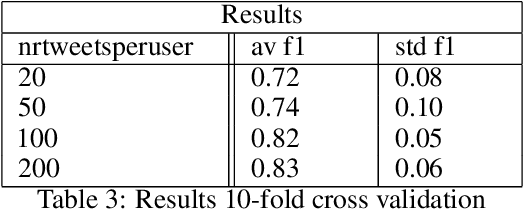
Transformer models have shown impressive performance on a variety of NLP tasks. Off-the-shelf, pre-trained models can be fine-tuned for specific NLP classification tasks, reducing the need for large amounts of additional training data. However, little research has addressed how much data is required to accurately fine-tune such pre-trained transformer models, and how much data is needed for accurate prediction. This paper explores the usability of BERT (a Transformer model for word embedding) for gender prediction on social media. Forensic applications include detecting gender obfuscation, e.g. males posing as females in chat rooms. A Dutch BERT model is fine-tuned on different samples of a Dutch Twitter dataset labeled for gender, varying in the number of tweets used per person. The results show that finetuning BERT contributes to good gender classification performance (80% F1) when finetuned on only 200 tweets per person. But when using just 20 tweets per person, the performance of our classifier deteriorates non-steeply (to 70% F1). These results show that even with relatively small amounts of data, BERT can be fine-tuned to accurately help predict the gender of Twitter users, and, consequently, that it is possible to determine gender on the basis of just a low volume of tweets. This opens up an operational perspective on the swift detection of gender.
Adversarial Patch Camouflage against Aerial Detection
Aug 31, 2020
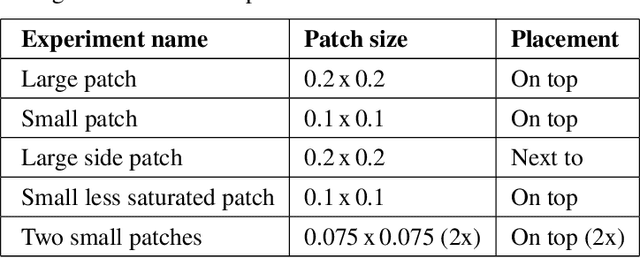

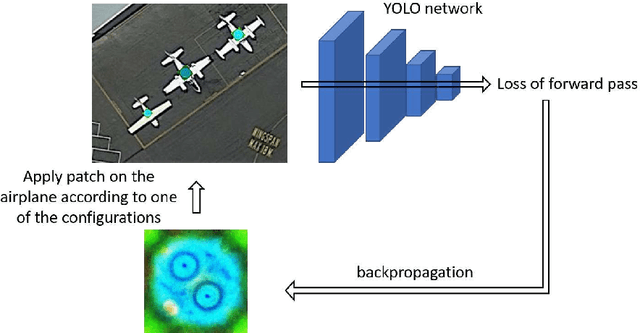
Detection of military assets on the ground can be performed by applying deep learning-based object detectors on drone surveillance footage. The traditional way of hiding military assets from sight is camouflage, for example by using camouflage nets. However, large assets like planes or vessels are difficult to conceal by means of traditional camouflage nets. An alternative type of camouflage is the direct misleading of automatic object detectors. Recently, it has been observed that small adversarial changes applied to images of the object can produce erroneous output by deep learning-based detectors. In particular, adversarial attacks have been successfully demonstrated to prohibit person detections in images, requiring a patch with a specific pattern held up in front of the person, thereby essentially camouflaging the person for the detector. Research into this type of patch attacks is still limited and several questions related to the optimal patch configuration remain open. This work makes two contributions. First, we apply patch-based adversarial attacks for the use case of unmanned aerial surveillance, where the patch is laid on top of large military assets, camouflaging them from automatic detectors running over the imagery. The patch can prevent automatic detection of the whole object while only covering a small part of it. Second, we perform several experiments with different patch configurations, varying their size, position, number and saliency. Our results show that adversarial patch attacks form a realistic alternative to traditional camouflage activities, and should therefore be considered in the automated analysis of aerial surveillance imagery.
Robustness Verification for Classifier Ensembles
May 12, 2020
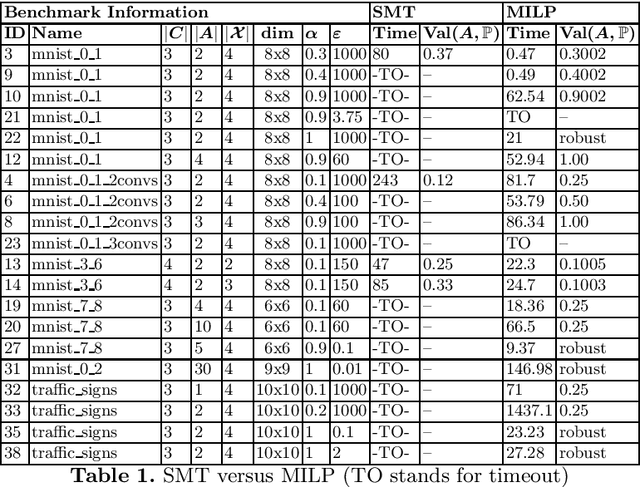

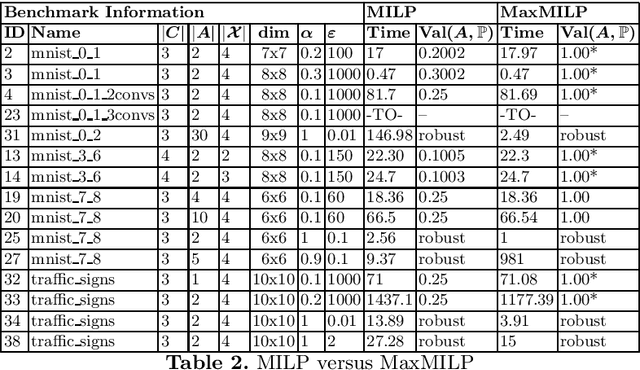
We give a formal verification procedure that decides whether a classifier ensemble is robust against arbitrary randomized attacks. Such attacks consist of a set of deterministic attacks and a distribution over this set. The robustness-checking problem consists of assessing, given a set of classifiers and a labelled data set, whether there exists a randomized attack that induces a certain expected loss against all classifiers. We show the NP-hardness of the problem and provide an upper bound on the number of attacks that is sufficient to form an optimal randomized attack. These results provide an effective way to reason about the robustness of a classifier ensemble. We provide SMT and MILP encodings to compute optimal randomized attacks or prove that there is no attack inducing a certain expected loss. In the latter case, the classifier ensemble is provably robust. Our prototype implementation verifies multiple neural-network ensembles trained for image-classification tasks. The experimental results using the MILP encoding are promising both in terms of scalability and the general applicability of our verification procedure.