 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-Based Join Ordering
Nov 18, 2025Join ordering is the NP-hard problem of selecting the most efficient sequence in which to evaluate joins (conjunctive, binary operators) in a database query. As the performance of query execution critically depends on this choice, join ordering lies at the core of query optimization. Traditional approaches cast this problem as a discrete combinatorial search over binary trees guided by a cost model, but they often suffer from high computational complexity and limited scalability. We show that, when the cost model is differentiable, the query plans can be continuously relaxed into a soft adjacency matrix representing a superposition of plans. This continuous relaxation, together with a Gumbel-Softmax parameterization of the adjacency matrix and differentiable constraints enforcing plan validity, enables gradient-based search for plans within this relaxed space. Using a learned Graph Neural Network as the cost model, we demonstrate that this gradient-based approach can find comparable and even lower-cost plans compared to traditional discrete local search methods on two different graph datasets. Furthermore, we empirically show that the runtime of this approach scales linearly with query size, in contrast to quadratic or exponential runtimes of classical approaches. We believe this first step towards gradient-based join ordering can lead to more effective and efficient query optimizers in the future.
Q-NL Verifier: Leveraging Synthetic Data for Robust Knowledge Graph Question Answering
Mar 03, 2025Question answering (QA) requires accurately aligning user questions with structured queries, a process often limited by the scarcity of high-quality query-natural language (Q-NL) pairs. To overcome this, we present Q-NL Verifier, an approach to generating high-quality synthetic pairs of queries and NL translations. Our approach relies on large language models (LLMs) to generate semantically precise natural language paraphrases of structured queries. Building on these synthetic Q-NL pairs, we introduce a learned verifier component that automatically determines whether a generated paraphrase is semantically equivalent to the original query. Our experiments with the well-known LC-QuAD 2.0 benchmark show that Q-NL Verifier generalizes well to paraphrases from other models and even human-authored translations. Our approach strongly aligns with human judgments across varying query complexities and outperforms existing NLP metrics in assessing semantic correctness. We also integrate the verifier into QA pipelines, showing that verifier-filtered synthetic data has significantly higher quality in terms of translation correctness and enhances NL to Q translation accuracy. Lastly, we release an updated version of the LC-QuAD 2.0 benchmark containing our synthetic Q-NL pairs and verifier scores, offering a new resource for robust and scalable QA.
Markov Process-Based Graph Convolutional Networks for Entity Classification in Knowledge Graphs
Dec 23, 2024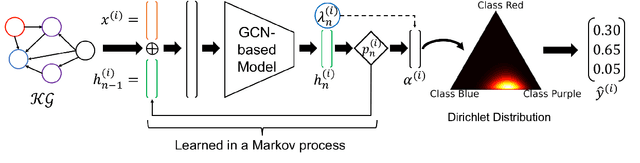


Despite the vast amount of information encoded in Knowledge Graphs (KGs), information about the class affiliation of entities remains often incomplete. Graph Convolutional Networks (GCNs) have been shown to be effective predictors of complete information about the class affiliation of entities in KGs. However, these models do not learn the class affiliation of entities in KGs incorporating the complexity of the task, which negatively affects the models prediction capabilities. To address this problem, we introduce a Markov process-based architecture into well-known GCN architectures. This end-to-end network learns the prediction of class affiliation of entities in KGs within a Markov process. The number of computational steps is learned during training using a geometric distribution. At the same time, the loss function combines insights from the field of evidential learning. The experiments show a performance improvement over existing models in several studied architectures and datasets. Based on the chosen hyperparameters for the geometric distribution, the expected number of computation steps can be adjusted to improve efficiency and accuracy during training.
Neuro-Symbolic Query Optimization in Knowledge Graphs
Nov 21, 2024This chapter delves into the emerging field of neuro-symbolic query optimization for knowledge graphs (KGs), presenting a comprehensive exploration of how neural and symbolic techniques can be integrated to enhance query processing. Traditional query optimizers in knowledge graphs rely heavily on symbolic methods, utilizing dataset summaries, statistics, and cost models to select efficient execution plans. However, these approaches often suffer from misestimations and inaccuracies, particularly when dealing with complex queries or large-scale datasets. Recent advancements have introduced neural models, which capture non-linear aspects of query optimization, offering promising alternatives to purely symbolic methods. In this chapter, we introduce neuro-symbolic query optimizers, a novel approach that combines the strengths of symbolic reasoning with the adaptability of neural computation. We discuss the architecture of these hybrid systems, highlighting the interplay between neural and symbolic components to improve the optimizer's ability to navigate the search space and produce efficient execution plans. Additionally, the chapter reviews existing neural components tailored for optimizing queries over knowledge graphs and examines the limitations and challenges in deploying neuro-symbolic query optimizers in real-world environments.
Towards Semantically Enriched Embeddings for Knowledge Graph Completion
Aug 02, 2023Embedding based Knowledge Graph (KG) Completion has gained much attention over the past few years. Most of the current algorithms consider a KG as a multidirectional labeled graph and lack the ability to capture the semantics underlying the schematic information. In a separate development, a vast amount of information has been captured within the Large Language Models (LLMs) which has revolutionized the field of Artificial Intelligence. KGs could benefit from these LLMs and vice versa. This vision paper discusses the existing algorithms for KG completion based on the variations for generating KG embeddings. It starts with discussing various KG completion algorithms such as transductive and inductive link prediction and entity type prediction algorithms. It then moves on to the algorithms utilizing type information within the KGs, LLMs, and finally to algorithms capturing the semantics represented in different description logic axioms. We conclude the paper with a critical reflection on the current state of work in the community and give recommendations for future directions.
Cardinality Estimation over Knowledge Graphs with Embeddings and Graph Neural Networks
Mar 02, 2023Cardinality Estimation over Knowledge Graphs (KG) is crucial for query optimization, yet remains a challenging task due to the semi-structured nature and complex correlations of typical Knowledge Graphs. In this work, we propose GNCE, a novel approach that leverages knowledge graph embeddings and Graph Neural Networks (GNN) to accurately predict the cardinality of conjunctive queries. GNCE first creates semantically meaningful embeddings for all entities in the KG, which are then integrated into the given query, which is processed by a GNN to estimate the cardinality of the query. We evaluate GNCE on several KGs in terms of q-Error and demonstrate that it outperforms state-of-the-art approaches based on sampling, summaries, and (machine) learning in terms of estimation accuracy while also having lower execution time and less parameters. Additionally, we show that GNCE can inductively generalise to unseen entities, making it suitable for use in dynamic query processing scenarios. Our proposed approach has the potential to significantly improve query optimization and related applications that rely on accurate cardinality estimates of conjunctive queries.
On the Applicability of Synthetic Data for Re-Identification
Dec 20, 2022



This contribution demonstrates the feasibility of applying Generative Adversarial Networks (GANs) on images of EPAL pallet blocks for dataset enhancement in the context of re-identification. For many industrial applications of re-identification methods, datasets of sufficient volume would otherwise be unattainable in non-laboratory settings. Using a state-of-the-art GAN architecture, namely CycleGAN, images of pallet blocks rotated to their left-hand side were generated from images of visually centered pallet blocks, based on images of rotated pallet blocks that were recorded as part of a previously recorded and published dataset. In this process, the unique chipwood pattern of the pallet block surface structure was retained, only changing the orientation of the pallet block itself. By doing so, synthetic data for re-identification testing and training purposes was generated, in a manner that is distinct from ordinary data augmentation. In total, 1,004 new images of pallet blocks were generated. The quality of the generated images was gauged using a perspective classifier that was trained on the original images and then applied to the synthetic ones, comparing the accuracy between the two sets of images. The classification accuracy was 98% for the original images and 92% for the synthetic images. In addition, the generated images were also used in a re-identification task, in order to re-identify original images based on synthetic ones. The accuracy in this scenario was up to 88% for synthetic images, compared to 96% for original images. Through this evaluation, it is established, whether or not a generated pallet block image closely resembles its original counterpart.
TokTrack: A Complete Token Provenance and Change Tracking Dataset for the English Wikipedia
Mar 23, 2017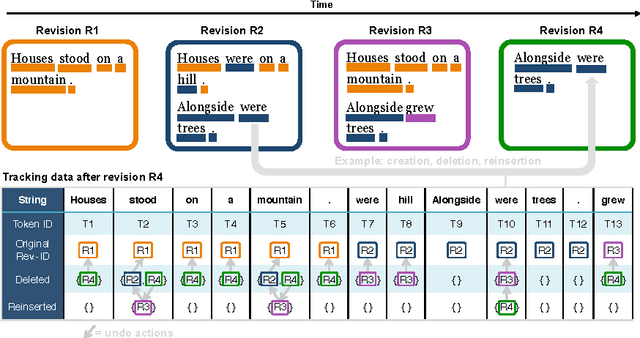
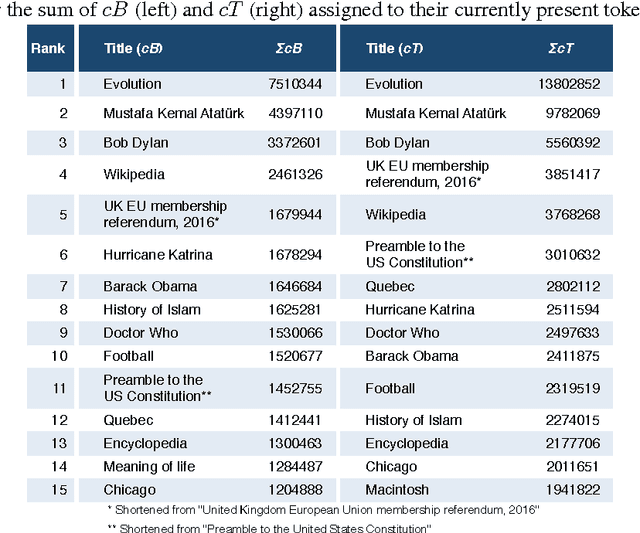
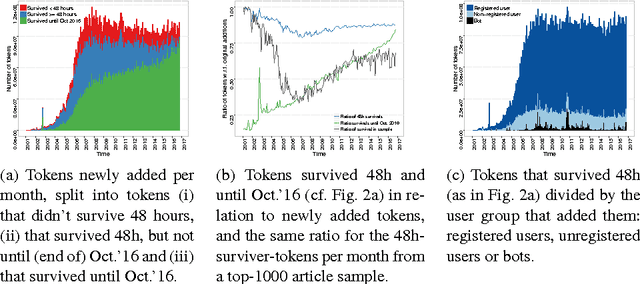
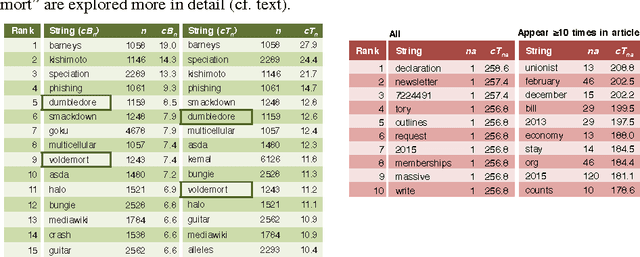
We present a dataset that contains every instance of all tokens (~ words) ever written in undeleted, non-redirect English Wikipedia articles until October 2016, in total 13,545,349,787 instances. Each token is annotated with (i) the article revision it was originally created in, and (ii) lists with all the revisions in which the token was ever deleted and (potentially) re-added and re-deleted from its article, enabling a complete and straightforward tracking of its history. This data would be exceedingly hard to create by an average potential user as it is (i) very expensive to compute and as (ii) accurately tracking the history of each token in revisioned documents is a non-trivial task. Adapting a state-of-the-art algorithm, we have produced a dataset that allows for a range of analyses and metrics, already popular in research and going beyond, to be generated on complete-Wikipedia scale; ensuring quality and allowing researchers to forego expensive text-comparison computation, which so far has hindered scalable usage. We show how this data enables, on token-level, computation of provenance, measuring survival of content over time, very detailed conflict metrics, and fine-grained interactions of editors like partial reverts, re-additions and other metrics, in the process gaining several novel insights.