 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarkov Process-Based Graph Convolutional Networks for Entity Classification in Knowledge Graphs
Dec 23, 2024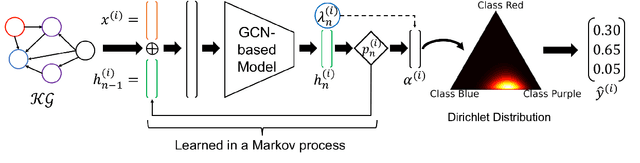


Despite the vast amount of information encoded in Knowledge Graphs (KGs), information about the class affiliation of entities remains often incomplete. Graph Convolutional Networks (GCNs) have been shown to be effective predictors of complete information about the class affiliation of entities in KGs. However, these models do not learn the class affiliation of entities in KGs incorporating the complexity of the task, which negatively affects the models prediction capabilities. To address this problem, we introduce a Markov process-based architecture into well-known GCN architectures. This end-to-end network learns the prediction of class affiliation of entities in KGs within a Markov process. The number of computational steps is learned during training using a geometric distribution. At the same time, the loss function combines insights from the field of evidential learning. The experiments show a performance improvement over existing models in several studied architectures and datasets. Based on the chosen hyperparameters for the geometric distribution, the expected number of computation steps can be adjusted to improve efficiency and accuracy during training.
On a Generalized Framework for Time-Aware Knowledge Graphs
Jul 20, 2022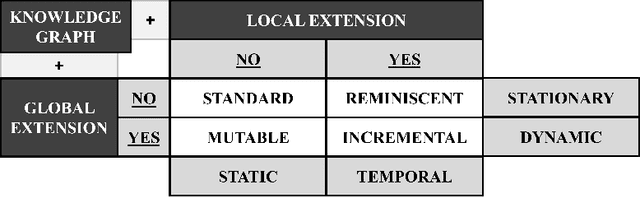

Knowledge graphs have emerged as an effective tool for managing and standardizing semistructured domain knowledge in a human- and machine-interpretable way. In terms of graph-based domain applications, such as embeddings and graph neural networks, current research is increasingly taking into account the time-related evolution of the information encoded within a graph. Algorithms and models for stationary and static knowledge graphs are extended to make them accessible for time-aware domains, where time-awareness can be interpreted in different ways. In particular, a distinction needs to be made between the validity period and the traceability of facts as objectives of time-related knowledge graph extensions. In this context, terms and definitions such as dynamic and temporal are often used inconsistently or interchangeably in the literature. Therefore, with this paper we aim to provide a short but well-defined overview of time-aware knowledge graph extensions and thus faciliate future research in this field as well.
Explaining Convolutional Neural Networks by Tagging Filters
Sep 20, 2021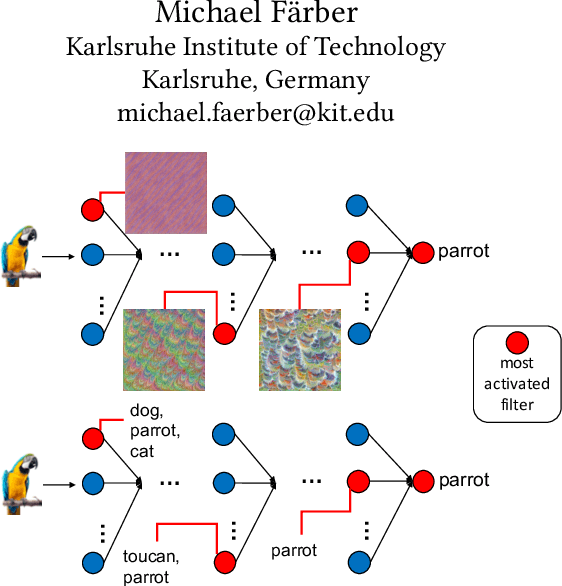
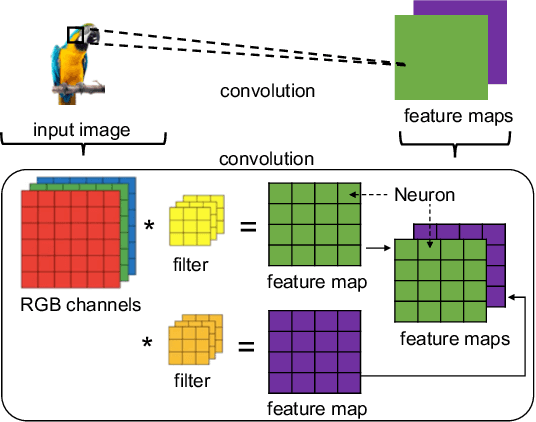

Convolutional neural networks (CNNs) have achieved astonishing performance on various image classification tasks, but it is difficult for humans to understand how a classification comes about. Recent literature proposes methods to explain the classification process to humans. These focus mostly on visualizing feature maps and filter weights, which are not very intuitive for non-experts in analyzing a CNN classification. In this paper, we propose FilTag, an approach to effectively explain CNNs even to non-experts. The idea is that when images of a class frequently activate a convolutional filter, then that filter is tagged with that class. These tags provide an explanation to a reference of a class-specific feature detected by the filter. Based on the tagging, individual image classifications can then be intuitively explained in terms of the tags of the filters that the input image activates. Finally, we show that the tags are helpful in analyzing classification errors caused by noisy input images and that the tags can be further processed by machines.
Making Neural Networks FAIR
Jul 26, 2019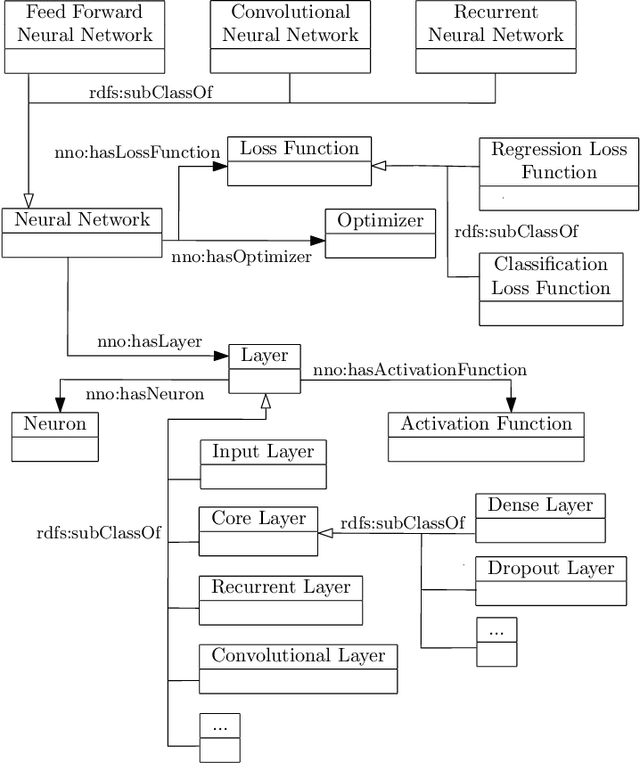
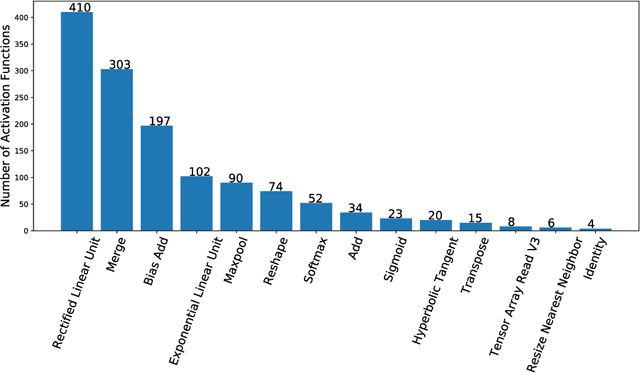
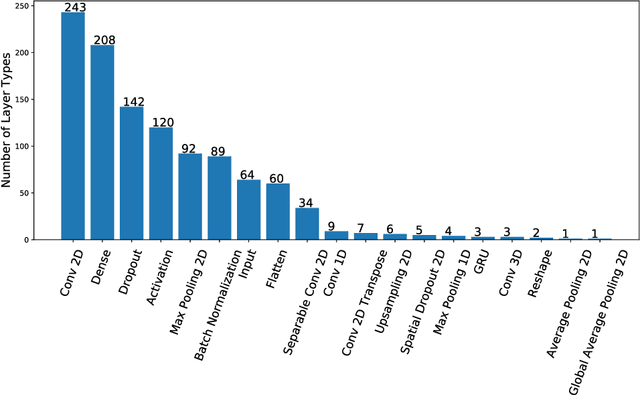
Research on neural networks has gained significant momentum over the past few years. A plethora of neural networks is currently being trained on available data in research as well as in industry. Because training is a resource-intensive process and training data cannot always be made available to everyone, there has been a recent trend to attempt to re-use already-trained neural networks. As such, neural networks themselves have become research data. In this paper, we present the Neural Network Ontology, an ontology to make neural networks findable, accessible, interoperable and reusable as suggested by the well-established FAIR guiding principles for scientific data management and stewardship. We created the new FAIRnets Dataset that comprises about 2,000 neural networks openly accessible on the internet and uses the Neural Network Ontology to semantically annotate and represent the neural networks. For each of the neural networks in the FAIRnets Dataset, the relevant properties according to the Neural Network Ontology such as the description and the architecture are stored. Ultimately, the FAIRnets Dataset can be queried with a set of desired properties and responds with a set of neural networks that have these properties. We provide the service FAIRnets Search which is implemented on top of a SPARQL endpoint and allows for querying, searching and finding trained neural networks annotated with the Neural Network Ontology. The service is demonstrated by a browser-based frontend to the SPARQL endpoint.