 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Computational Costs in Sentiment Analysis: Tensorized Recurrent Networks vs. Recurrent Networks
Jun 16, 2023Anticipating audience reaction towards a certain text is integral to several facets of society ranging from politics, research, and commercial industries. Sentiment analysis (SA) is a useful natural language processing (NLP) technique that utilizes lexical/statistical and deep learning methods to determine whether different-sized texts exhibit positive, negative, or neutral emotions. Recurrent networks are widely used in machine-learning communities for problems with sequential data. However, a drawback of models based on Long-Short Term Memory networks and Gated Recurrent Units is the significantly high number of parameters, and thus, such models are computationally expensive. This drawback is even more significant when the available data are limited. Also, such models require significant over-parameterization and regularization to achieve optimal performance. Tensorized models represent a potential solution. In this paper, we classify the sentiment of some social media posts. We compare traditional recurrent models with their tensorized version, and we show that with the tensorized models, we reach comparable performances with respect to the traditional models while using fewer resources for the training.
Emotion Analysis using Multi-Layered Networks for Graphical Representation of Tweets
Jul 02, 2022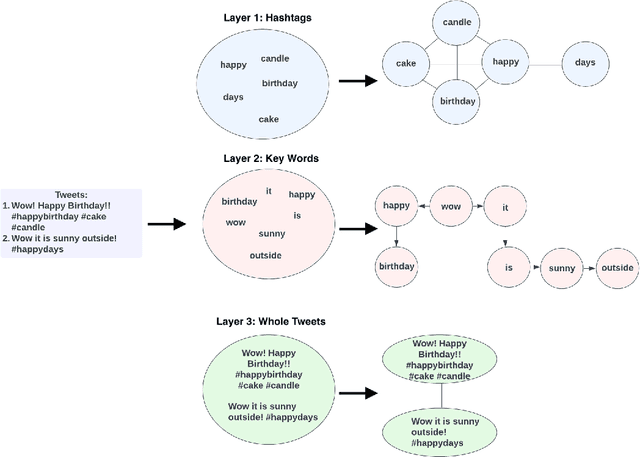
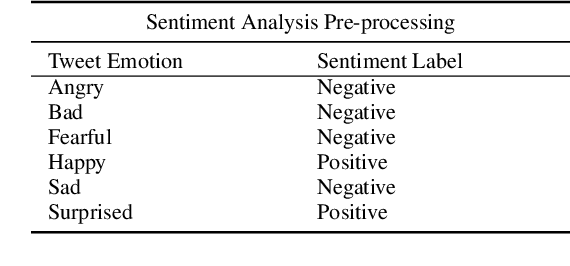
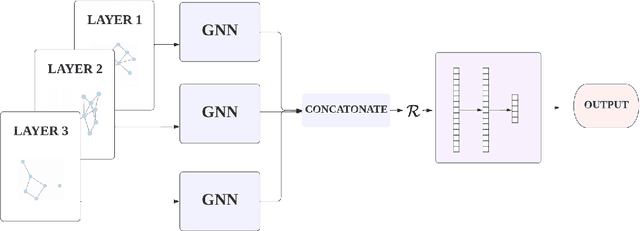

Anticipating audience reaction towards a certain piece of text is integral to several facets of society ranging from politics, research, and commercial industries. Sentiment analysis (SA) is a useful natural language processing (NLP) technique that utilizes both lexical/statistical and deep learning methods to determine whether different sized texts exhibit a positive, negative, or neutral emotion. However, there is currently a lack of tools that can be used to analyse groups of independent texts and extract the primary emotion from the whole set. Therefore, the current paper proposes a novel algorithm referred to as the Multi-Layered Tweet Analyzer (MLTA) that graphically models social media text using multi-layered networks (MLNs) in order to better encode relationships across independent sets of tweets. Graph structures are capable of capturing meaningful relationships in complex ecosystems compared to other representation methods. State of the art Graph Neural Networks (GNNs) are used to extract information from the Tweet-MLN and make predictions based on the extracted graph features. Results show that not only does the MLTA predict from a larger set of possible emotions, delivering a more accurate sentiment compared to the standard positive, negative or neutral, it also allows for accurate group-level predictions of Twitter data.
Explaining Convolutional Neural Networks by Tagging Filters
Sep 20, 2021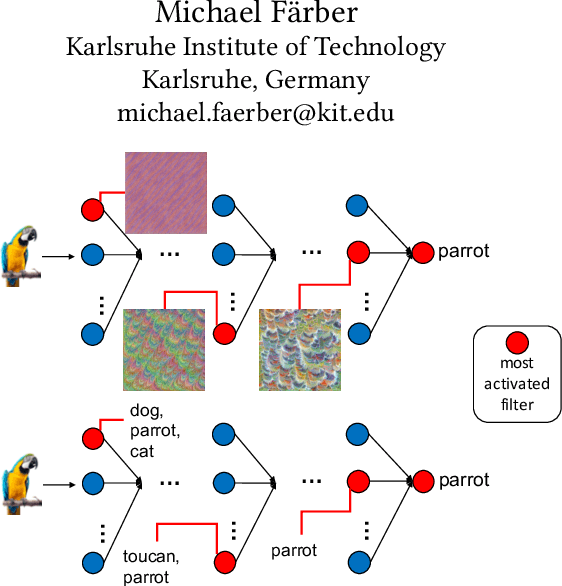
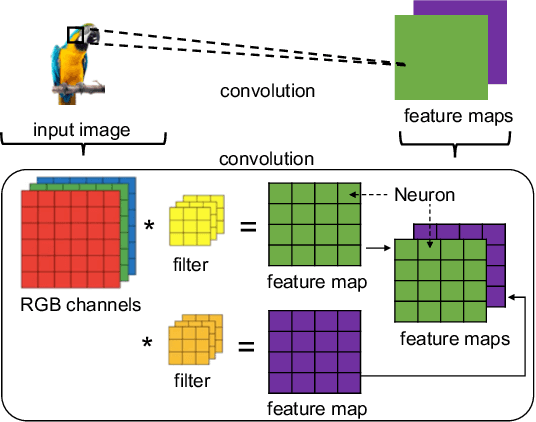

Convolutional neural networks (CNNs) have achieved astonishing performance on various image classification tasks, but it is difficult for humans to understand how a classification comes about. Recent literature proposes methods to explain the classification process to humans. These focus mostly on visualizing feature maps and filter weights, which are not very intuitive for non-experts in analyzing a CNN classification. In this paper, we propose FilTag, an approach to effectively explain CNNs even to non-experts. The idea is that when images of a class frequently activate a convolutional filter, then that filter is tagged with that class. These tags provide an explanation to a reference of a class-specific feature detected by the filter. Based on the tagging, individual image classifications can then be intuitively explained in terms of the tags of the filters that the input image activates. Finally, we show that the tags are helpful in analyzing classification errors caused by noisy input images and that the tags can be further processed by machines.
Knowledge Graphs Evolution and Preservation -- A Technical Report from ISWS 2019
Dec 22, 2020
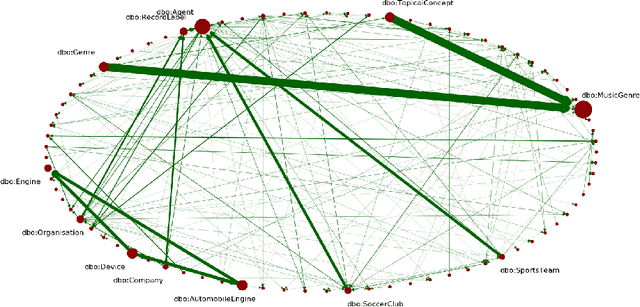

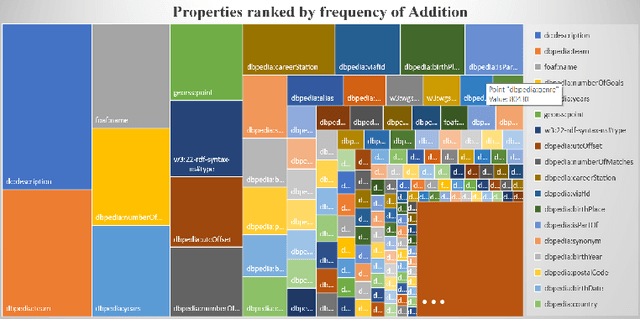
One of the grand challenges discussed during the Dagstuhl Seminar "Knowledge Graphs: New Directions for Knowledge Representation on the Semantic Web" and described in its report is that of a: "Public FAIR Knowledge Graph of Everything: We increasingly see the creation of knowledge graphs that capture information about the entirety of a class of entities. [...] This grand challenge extends this further by asking if we can create a knowledge graph of "everything" ranging from common sense concepts to location based entities. This knowledge graph should be "open to the public" in a FAIR manner democratizing this mass amount of knowledge." Although linked open data (LOD) is one knowledge graph, it is the closest realisation (and probably the only one) to a public FAIR Knowledge Graph (KG) of everything. Surely, LOD provides a unique testbed for experimenting and evaluating research hypotheses on open and FAIR KG. One of the most neglected FAIR issues about KGs is their ongoing evolution and long term preservation. We want to investigate this problem, that is to understand what preserving and supporting the evolution of KGs means and how these problems can be addressed. Clearly, the problem can be approached from different perspectives and may require the development of different approaches, including new theories, ontologies, metrics, strategies, procedures, etc. This document reports a collaborative effort performed by 9 teams of students, each guided by a senior researcher as their mentor, attending the International Semantic Web Research School (ISWS 2019). Each team provides a different perspective to the problem of knowledge graph evolution substantiated by a set of research questions as the main subject of their investigation. In addition, they provide their working definition for KG preservation and evolution.
Right for the Right Reason: Making Image Classification Robust
Jul 23, 2020
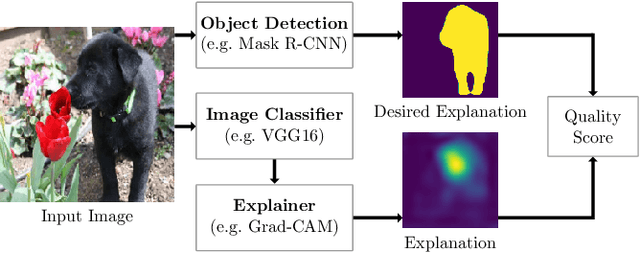
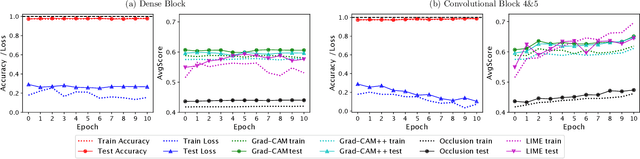

Convolutional neural networks (CNNs) have achieved astonishing performance on various image classification tasks. Although such models classify most images correctly, they do not provide any explanation for their decisions. Recently, there have been attempts to provide such an explanation by determining which parts of the input image the classifier focuses on most. It turns out that many models output the correct classification, but for the wrong reason (e.g., based on irrelevant parts of the image). In this paper, we propose a new score for automatically quantifying to which degree the model focuses on the right image parts. The score is calculated by considering the degree to which the most decisive image regions - given by applying an explainer to the CNN model - overlap with the silhouette of the object to be classified. In extensive experiments using VGG16, ResNet, and MobileNet as CNNs, Occlusion, LIME, and Grad-Cam/Grad-Cam++ as explanation methods, and Dogs vs. Cats and Caltech 101 as data sets, we can show that our metric can indeed be used for making CNN models for image classification more robust while keeping their accuracy.
Making Neural Networks FAIR
Jul 26, 2019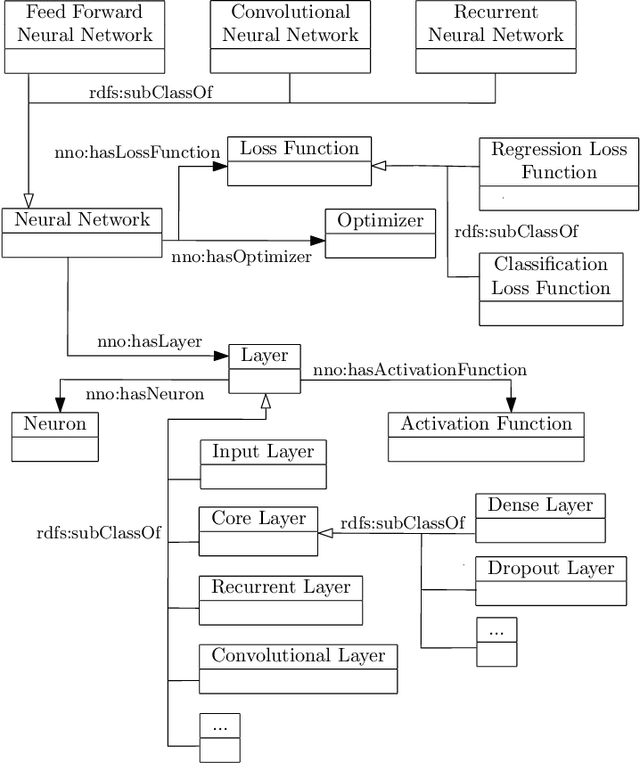
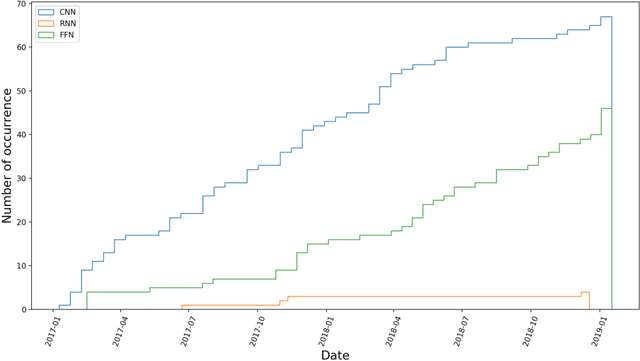
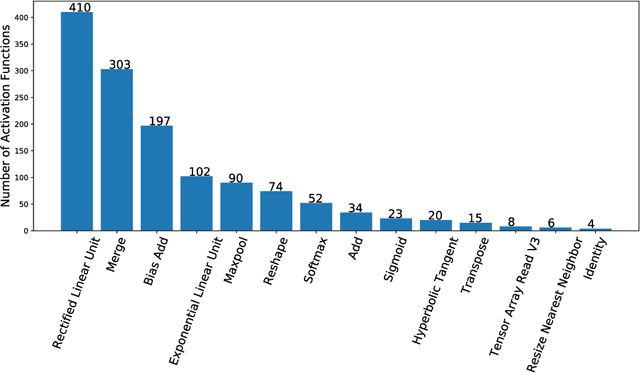
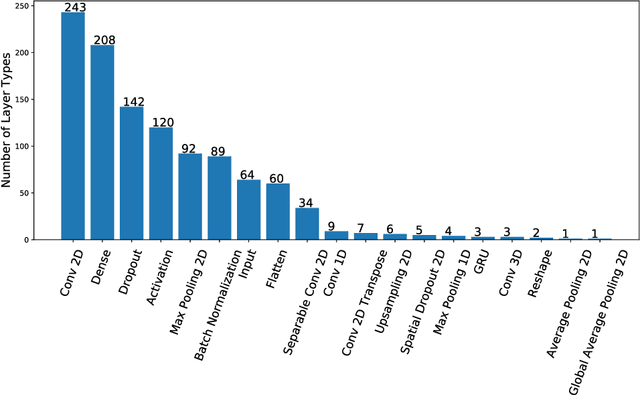
Research on neural networks has gained significant momentum over the past few years. A plethora of neural networks is currently being trained on available data in research as well as in industry. Because training is a resource-intensive process and training data cannot always be made available to everyone, there has been a recent trend to attempt to re-use already-trained neural networks. As such, neural networks themselves have become research data. In this paper, we present the Neural Network Ontology, an ontology to make neural networks findable, accessible, interoperable and reusable as suggested by the well-established FAIR guiding principles for scientific data management and stewardship. We created the new FAIRnets Dataset that comprises about 2,000 neural networks openly accessible on the internet and uses the Neural Network Ontology to semantically annotate and represent the neural networks. For each of the neural networks in the FAIRnets Dataset, the relevant properties according to the Neural Network Ontology such as the description and the architecture are stored. Ultimately, the FAIRnets Dataset can be queried with a set of desired properties and responds with a set of neural networks that have these properties. We provide the service FAIRnets Search which is implemented on top of a SPARQL endpoint and allows for querying, searching and finding trained neural networks annotated with the Neural Network Ontology. The service is demonstrated by a browser-based frontend to the SPARQL endpoint.