 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Scholarly Ontology Generation: An Extensive Analysis in the Engineering Field
Dec 11, 2024



Ontologies of research topics are crucial for structuring scientific knowledge, enabling scientists to navigate vast amounts of research, and forming the backbone of intelligent systems such as search engines and recommendation systems. However, manual creation of these ontologies is expensive, slow, and often results in outdated and overly general representations. As a solution, researchers have been investigating ways to automate or semi-automate the process of generating these ontologies. This paper offers a comprehensive analysis of the ability of large language models (LLMs) to identify semantic relationships between different research topics, which is a critical step in the development of such ontologies. To this end, we developed a gold standard based on the IEEE Thesaurus to evaluate the task of identifying four types of relationships between pairs of topics: broader, narrower, same-as, and other. Our study evaluates the performance of seventeen LLMs, which differ in scale, accessibility (open vs. proprietary), and model type (full vs. quantised), while also assessing four zero-shot reasoning strategies. Several models have achieved outstanding results, including Mixtral-8x7B, Dolphin-Mistral-7B, and Claude 3 Sonnet, with F1-scores of 0.847, 0.920, and 0.967, respectively. Furthermore, our findings demonstrate that smaller, quantised models, when optimised through prompt engineering, can deliver performance comparable to much larger proprietary models, while requiring significantly fewer computational resources.
A Survey on Knowledge Organization Systems of Research Fields: Resources and Challenges
Sep 06, 2024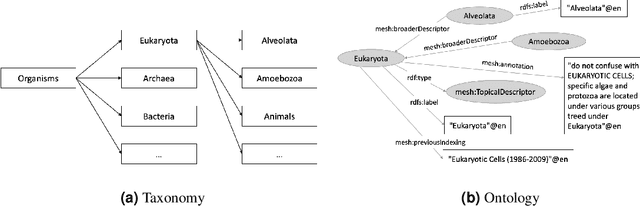
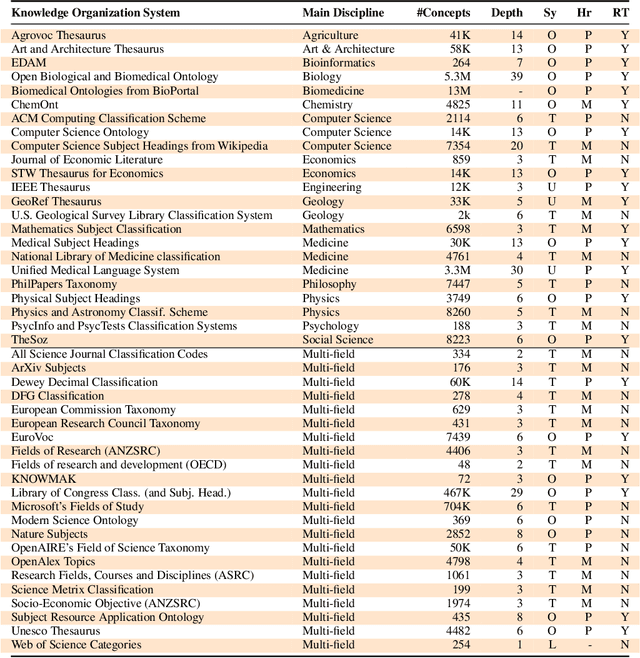
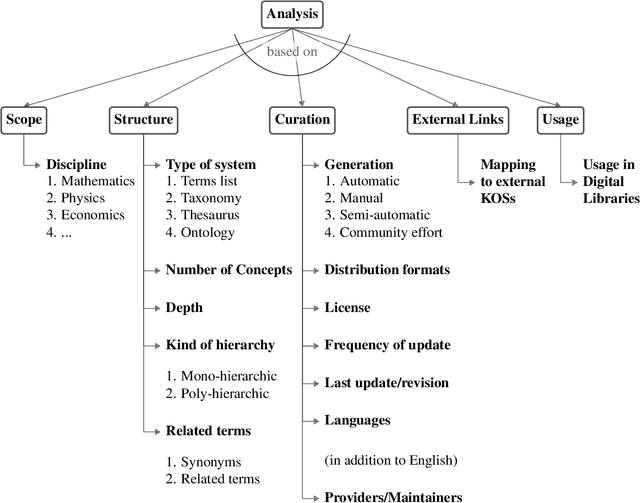
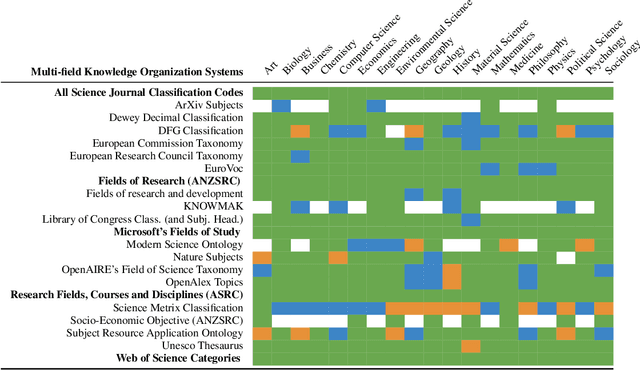
Knowledge Organization Systems (KOSs), such as term lists, thesauri, taxonomies, and ontologies, play a fundamental role in categorising, managing, and retrieving information. In the academic domain, KOSs are often adopted for representing research areas and their relationships, primarily aiming to classify research articles, academic courses, patents, books, scientific venues, domain experts, grants, software, experiment materials, and several other relevant products and agents. These structured representations of research areas, widely embraced by many academic fields, have proven effective in empowering AI-based systems to i) enhance retrievability of relevant documents, ii) enable advanced analytic solutions to quantify the impact of academic research, and iii) analyse and forecast research dynamics. This paper aims to present a comprehensive survey of the current KOS for academic disciplines. We analysed and compared 45 KOSs according to five main dimensions: scope, structure, curation, usage, and links to other KOSs. Our results reveal a very heterogeneous scenario in terms of scope, scale, quality, and usage, highlighting the need for more integrated solutions for representing research knowledge across academic fields. We conclude by discussing the main challenges and the most promising future directions.