 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Triangulation-Based Graph Rewiring for Graph Neural Networks
Aug 28, 2025Graph Neural Networks (GNNs) have emerged as the leading paradigm for learning over graph-structured data. However, their performance is limited by issues inherent to graph topology, most notably oversquashing and oversmoothing. Recent advances in graph rewiring aim to mitigate these limitations by modifying the graph topology to promote more effective information propagation. In this work, we introduce TRIGON, a novel framework that constructs enriched, non-planar triangulations by learning to select relevant triangles from multiple graph views. By jointly optimizing triangle selection and downstream classification performance, our method produces a rewired graph with markedly improved structural properties such as reduced diameter, increased spectral gap, and lower effective resistance compared to existing rewiring methods. Empirical results demonstrate that TRIGON outperforms state-of-the-art approaches on node classification tasks across a range of homophilic and heterophilic benchmarks.
Can Artificial Intelligence Write Like Borges? An Evaluation Protocol for Spanish Microfiction
Jun 09, 2025Automated story writing has been a subject of study for over 60 years. Large language models can generate narratively consistent and linguistically coherent short fiction texts. Despite these advancements, rigorous assessment of such outputs for literary merit - especially concerning aesthetic qualities - has received scant attention. In this paper, we address the challenge of evaluating AI-generated microfictions and argue that this task requires consideration of literary criteria across various aspects of the text, such as thematic coherence, textual clarity, interpretive depth, and aesthetic quality. To facilitate this, we present GrAImes: an evaluation protocol grounded in literary theory, specifically drawing from a literary perspective, to offer an objective framework for assessing AI-generated microfiction. Furthermore, we report the results of our validation of the evaluation protocol, as answered by both literature experts and literary enthusiasts. This protocol will serve as a foundation for evaluating automatically generated microfictions and assessing their literary value.
Rewiring Techniques to Mitigate Oversquashing and Oversmoothing in GNNs: A Survey
Nov 26, 2024


Graph Neural Networks (GNNs) are powerful tools for learning from graph-structured data, but their effectiveness is often constrained by two critical challenges: oversquashing, where the excessive compression of information from distant nodes results in significant information loss, and oversmoothing, where repeated message-passing iterations homogenize node representations, obscuring meaningful distinctions. These issues, intrinsically linked to the underlying graph structure, hinder information flow and constrain the expressiveness of GNNs. In this survey, we examine graph rewiring techniques, a class of methods designed to address these structural bottlenecks by modifying graph topology to enhance information diffusion. We provide a comprehensive review of state-of-the-art rewiring approaches, delving into their theoretical underpinnings, practical implementations, and performance trade-offs.
Knowledge Graph Refinement based on Triplet BERT-Networks
Nov 18, 2022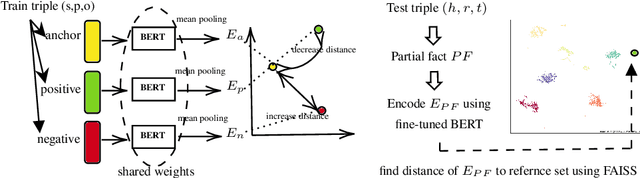
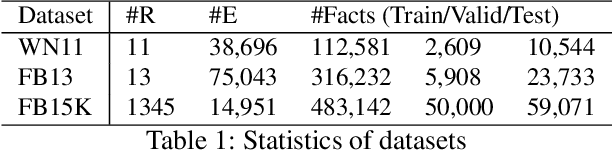
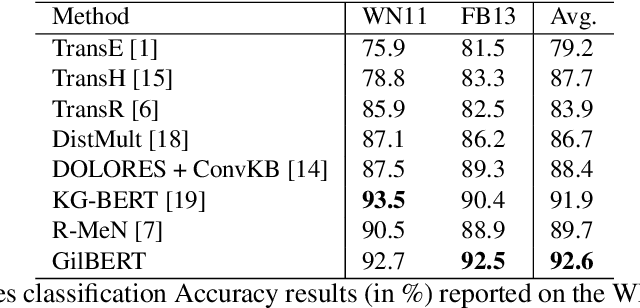
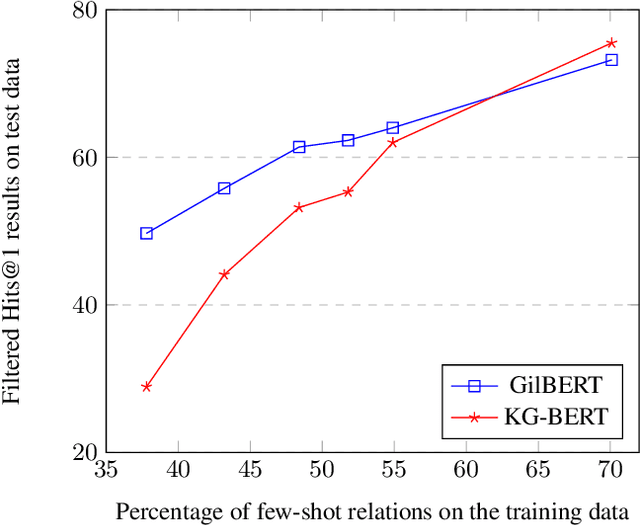
Knowledge graph embedding techniques are widely used for knowledge graph refinement tasks such as graph completion and triple classification. These techniques aim at embedding the entities and relations of a Knowledge Graph (KG) in a low dimensional continuous feature space. This paper adopts a transformer-based triplet network creating an embedding space that clusters the information about an entity or relation in the KG. It creates textual sequences from facts and fine-tunes a triplet network of pre-trained transformer-based language models. It adheres to an evaluation paradigm that relies on an efficient spatial semantic search technique. We show that this evaluation protocol is more adapted to a few-shot setting for the relation prediction task. Our proposed GilBERT method is evaluated on triplet classification and relation prediction tasks on multiple well-known benchmark knowledge graphs such as FB13, WN11, and FB15K. We show that GilBERT achieves better or comparable results to the state-of-the-art performance on these two refinement tasks.
The sameAs Problem: A Survey on Identity Management in the Web of Data
Jul 24, 2019


In a decentralised knowledge representation system such as the Web of Data, it is common and indeed desirable for different knowledge graphs to overlap. Whenever multiple names are used to denote the same thing, owl:sameAs statements are needed in order to link the data and foster reuse. Whilst the deductive value of such identity statements can be extremely useful in enhancing various knowledge-based systems, incorrect use of identity can have wide-ranging effects in a global knowledge space like the Web of Data. With several works already proven that identity in the Web is broken, this survey investigates the current state of this "sameAs problem". An open discussion highlights the main weaknesses suffered by solutions in the literature, and draws open challenges to be faced in the future.