 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptBPE: From General Purpose to Specialized Tokenizers
Jan 29, 2026Subword tokenization methods, such as Byte-Pair Encoding (BPE), significantly impact the performance and efficiency of large language models (LLMs). The standard approach involves training a general-purpose tokenizer that uniformly processes all textual data during both training and inference. However, the use of a generic set of tokens can incur inefficiencies when applying the model to specific domains or languages. To address this limitation, we propose a post-training adaptation strategy that selectively replaces low-utility tokens with more relevant ones based on their frequency in an adaptation corpus. Our algorithm identifies the token inventory that most effectively encodes the adaptation corpus for a given target vocabulary size. Extensive experiments on generation and classification tasks across multiple languages demonstrate that our adapted tokenizers compress test corpora more effectively than baselines using the same vocabulary size. This method serves as a lightweight adaptation mechanism, akin to a vocabulary fine-tuning process, enabling optimized tokenization for specific domains or tasks. Our code and data are available at https://github.com/vijini/Adapt-BPE.git.
An Ensemble Method Based on the Combination of Transformers with Convolutional Neural Networks to Detect Artificially Generated Text
Oct 26, 2023Thanks to the state-of-the-art Large Language Models (LLMs), language generation has reached outstanding levels. These models are capable of generating high quality content, thus making it a challenging task to detect generated text from human-written content. Despite the advantages provided by Natural Language Generation, the inability to distinguish automatically generated text can raise ethical concerns in terms of authenticity. Consequently, it is important to design and develop methodologies to detect artificial content. In our work, we present some classification models constructed by ensembling transformer models such as Sci-BERT, DeBERTa and XLNet, with Convolutional Neural Networks (CNNs). Our experiments demonstrate that the considered ensemble architectures surpass the performance of the individual transformer models for classification. Furthermore, the proposed SciBERT-CNN ensemble model produced an F1-score of 98.36% on the ALTA shared task 2023 data.
A Benchmark Corpus for the Detection of Automatically Generated Text in Academic Publications
Feb 04, 2022



Automatic text generation based on neural language models has achieved performance levels that make the generated text almost indistinguishable from those written by humans. Despite the value that text generation can have in various applications, it can also be employed for malicious tasks. The diffusion of such practices represent a threat to the quality of academic publishing. To address these problems, we propose in this paper two datasets comprised of artificially generated research content: a completely synthetic dataset and a partial text substitution dataset. In the first case, the content is completely generated by the GPT-2 model after a short prompt extracted from original papers. The partial or hybrid dataset is created by replacing several sentences of abstracts with sentences that are generated by the Arxiv-NLP model. We evaluate the quality of the datasets comparing the generated texts to aligned original texts using fluency metrics such as BLEU and ROUGE. The more natural the artificial texts seem, the more difficult they are to detect and the better is the benchmark. We also evaluate the difficulty of the task of distinguishing original from generated text by using state-of-the-art classification models.
A Multi-language Platform for Generating Algebraic Mathematical Word Problems
Nov 19, 2019

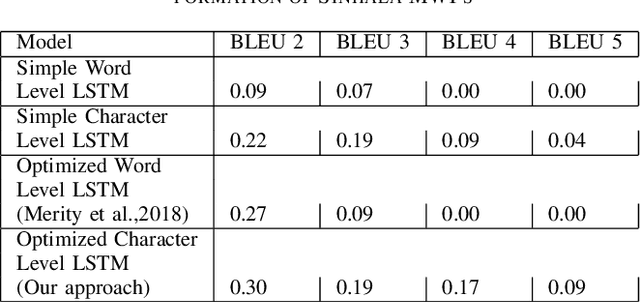

Existing approaches for automatically generating mathematical word problems are deprived of customizability and creativity due to the inherent nature of template-based mechanisms they employ. We present a solution to this problem with the use of deep neural language generation mechanisms. Our approach uses a Character Level Long Short Term Memory Network (LSTM) to generate word problems, and uses POS (Part of Speech) tags to resolve the constraints found in the generated problems. Our approach is capable of generating Mathematics Word Problems in both English and Sinhala languages with an accuracy over 90%.