 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDISTO: Evaluating Textual Distractors for Multi-Choice Questions using Negative Sampling based Approach
Paper and Code
Apr 10, 2023


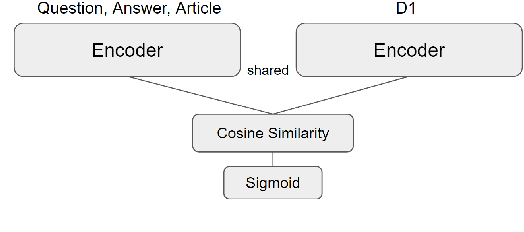
Multiple choice questions (MCQs) are an efficient and common way to assess reading comprehension (RC). Every MCQ needs a set of distractor answers that are incorrect, but plausible enough to test student knowledge. Distractor generation (DG) models have been proposed, and their performance is typically evaluated using machine translation (MT) metrics. However, MT metrics often misjudge the suitability of generated distractors. We propose DISTO: the first learned evaluation metric for generated distractors. We validate DISTO by showing its scores correlate highly with human ratings of distractor quality. At the same time, DISTO ranks the performance of state-of-the-art DG models very differently from MT-based metrics, showing that MT metrics should not be used for distractor evaluation.