 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Dream of Ontologies?
Jan 26, 2024
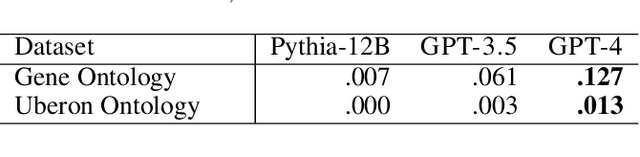
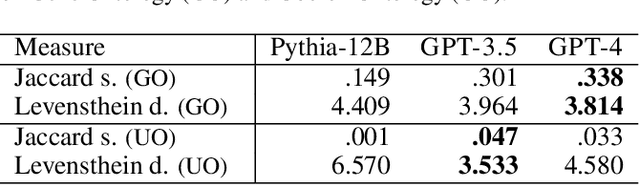

Large language models (LLMs) have recently revolutionized automated text understanding and generation. The performance of these models relies on the high number of parameters of the underlying neural architectures, which allows LLMs to memorize part of the vast quantity of data seen during the training. This paper investigates whether and to what extent general-purpose pre-trained LLMs have memorized information from known ontologies. Our results show that LLMs partially know ontologies: they can, and do indeed, memorize concepts from ontologies mentioned in the text, but the level of memorization of their concepts seems to vary proportionally to their popularity on the Web, the primary source of their training material. We additionally propose new metrics to estimate the degree of memorization of ontological information in LLMs by measuring the consistency of the output produced across different prompt repetitions, query languages, and degrees of determinism.
ZusammenQA: Data Augmentation with Specialized Models for Cross-lingual Open-retrieval Question Answering System
May 30, 2022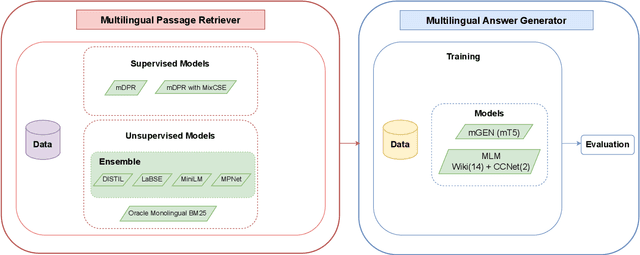

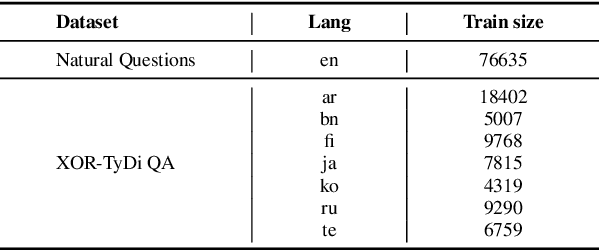

This paper introduces our proposed system for the MIA Shared Task on Cross-lingual Open-retrieval Question Answering (COQA). In this challenging scenario, given an input question the system has to gather evidence documents from a multilingual pool and generate from them an answer in the language of the question. We devised several approaches combining different model variants for three main components: Data Augmentation, Passage Retrieval, and Answer Generation. For passage retrieval, we evaluated the monolingual BM25 ranker against the ensemble of re-rankers based on multilingual pretrained language models (PLMs) and also variants of the shared task baseline, re-training it from scratch using a recently introduced contrastive loss that maintains a strong gradient signal throughout training by means of mixed negative samples. For answer generation, we focused on language- and domain-specialization by means of continued language model (LM) pretraining of existing multilingual encoders. Additionally, for both passage retrieval and answer generation, we augmented the training data provided by the task organizers with automatically generated question-answer pairs created from Wikipedia passages to mitigate the issue of data scarcity, particularly for the low-resource languages for which no training data were provided. Our results show that language- and domain-specialization as well as data augmentation help, especially for low-resource languages.