 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrExMe! Large Scale Prompt Exploration of Open Source LLMs for Machine Translation and Summarization Evaluation
Paper and Code
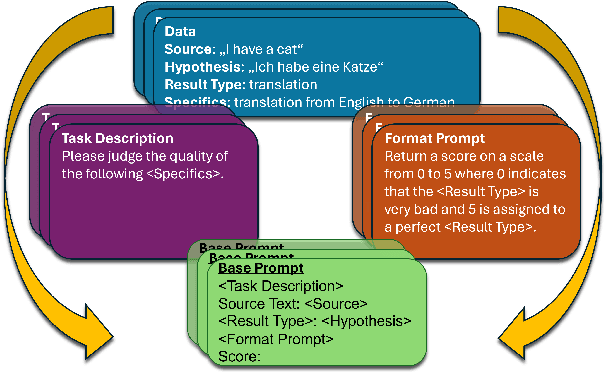

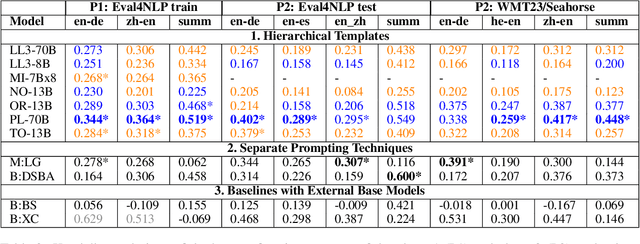
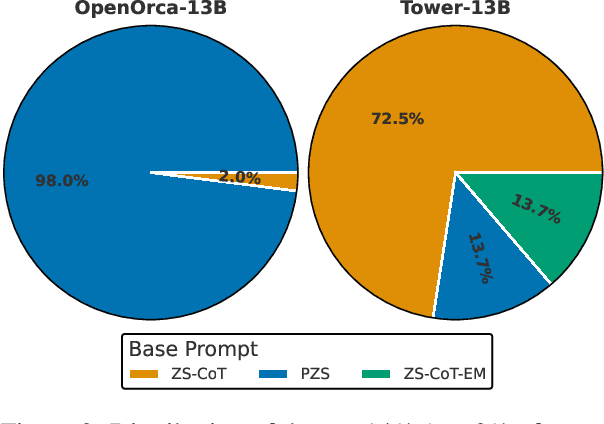
Large language models (LLMs) have revolutionized the field of NLP. Notably, their in-context learning capabilities also enable their use as evaluation metrics for natural language generation, making them particularly advantageous in low-resource scenarios and time-restricted applications. In this work, we introduce PrExMe, a large-scale prompt exploration for metrics, where we evaluate more than 720 prompt templates for open-source LLM-based metrics on machine translation (MT) and summarization datasets, totalling over 6.6M evaluations. This extensive comparison (1) serves as a benchmark of the performance of recent open-source LLMs as metrics and (2) explores the stability and variability of different prompting strategies. We discover that, on the one hand, there are scenarios for which prompts are stable. For instance, some LLMs show idiosyncratic preferences and favor to grade generated texts with textual labels while others prefer to return numeric scores. On the other hand, the stability of prompts and model rankings can be susceptible to seemingly innocuous changes. For example, changing the requested output format from "0 to 100" to "-1 to +1" can strongly affect the rankings in our evaluation. Our study contributes to understanding the impact of different prompting approaches on LLM-based metrics for MT and summarization evaluation, highlighting the most stable prompting patterns and potential limitations.