 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCFTrack: Center-based Radar and Camera Fusion for 3D Multi-Object Tracking
Jul 11, 2021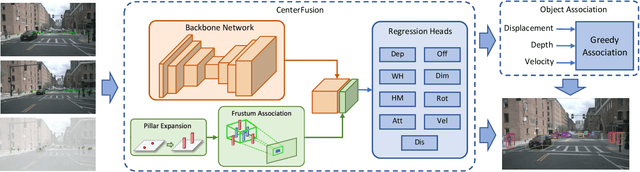
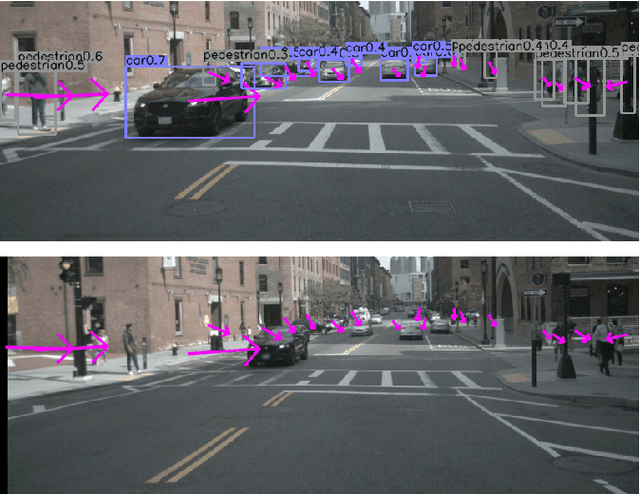
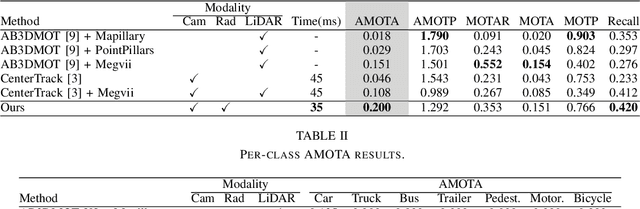
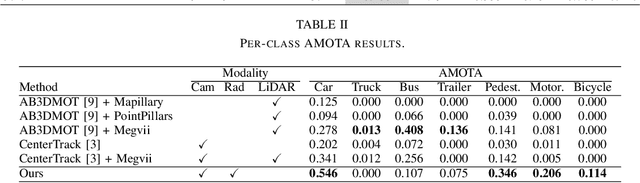
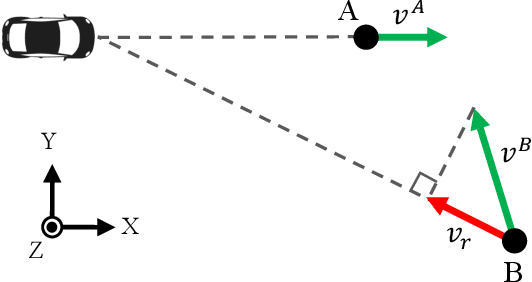
3D multi-object tracking is a crucial component in the perception system of autonomous driving vehicles. Tracking all dynamic objects around the vehicle is essential for tasks such as obstacle avoidance and path planning. Autonomous vehicles are usually equipped with different sensor modalities to improve accuracy and reliability. While sensor fusion has been widely used in object detection networks in recent years, most existing multi-object tracking algorithms either rely on a single input modality, or do not fully exploit the information provided by multiple sensing modalities. In this work, we propose an end-to-end network for joint object detection and tracking based on radar and camera sensor fusion. Our proposed method uses a center-based radar-camera fusion algorithm for object detection and utilizes a greedy algorithm for object association. The proposed greedy algorithm uses the depth, velocity and 2D displacement of the detected objects to associate them through time. This makes our tracking algorithm very robust to occluded and overlapping objects, as the depth and velocity information can help the network in distinguishing them. We evaluate our method on the challenging nuScenes dataset, where it achieves 20.0 AMOTA and outperforms all vision-based 3D tracking methods in the benchmark, as well as the baseline LiDAR-based method. Our method is online with a runtime of 35ms per image, making it very suitable for autonomous driving applications.
CenterFusion: Center-based Radar and Camera Fusion for 3D Object Detection
Nov 10, 2020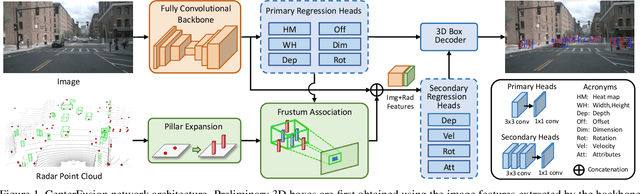
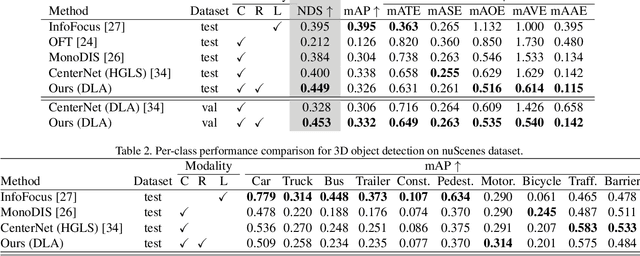

The perception system in autonomous vehicles is responsible for detecting and tracking the surrounding objects. This is usually done by taking advantage of several sensing modalities to increase robustness and accuracy, which makes sensor fusion a crucial part of the perception system. In this paper, we focus on the problem of radar and camera sensor fusion and propose a middle-fusion approach to exploit both radar and camera data for 3D object detection. Our approach, called CenterFusion, first uses a center point detection network to detect objects by identifying their center points on the image. It then solves the key data association problem using a novel frustum-based method to associate the radar detections to their corresponding object's center point. The associated radar detections are used to generate radar-based feature maps to complement the image features, and regress to object properties such as depth, rotation and velocity. We evaluate CenterFusion on the challenging nuScenes dataset, where it improves the overall nuScenes Detection Score (NDS) of the state-of-the-art camera-based algorithm by more than 12%. We further show that CenterFusion significantly improves the velocity estimation accuracy without using any additional temporal information. The code is available at https://github.com/mrnabati/CenterFusion .
Radar-Camera Sensor Fusion for Joint Object Detection and Distance Estimation in Autonomous Vehicles
Sep 17, 2020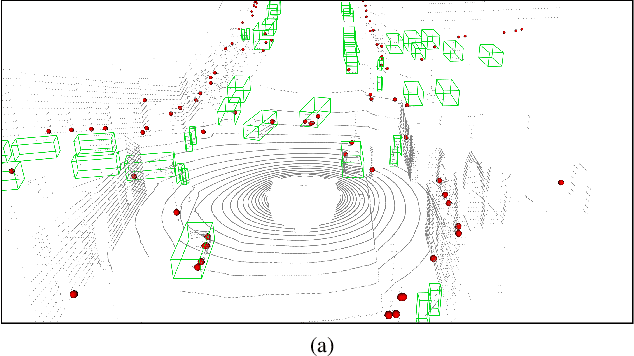
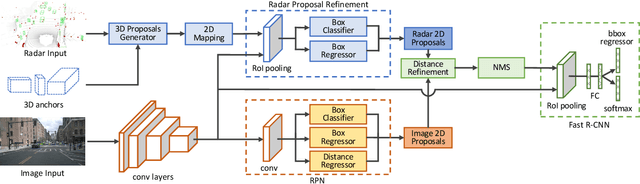


In this paper we present a novel radar-camera sensor fusion framework for accurate object detection and distance estimation in autonomous driving scenarios. The proposed architecture uses a middle-fusion approach to fuse the radar point clouds and RGB images. Our radar object proposal network uses radar point clouds to generate 3D proposals from a set of 3D prior boxes. These proposals are mapped to the image and fed into a Radar Proposal Refinement (RPR) network for objectness score prediction and box refinement. The RPR network utilizes both radar information and image feature maps to generate accurate object proposals and distance estimations. The radar-based proposals are combined with image-based proposals generated by a modified Region Proposal Network (RPN). The RPN has a distance regression layer for estimating distance for every generated proposal. The radar-based and image-based proposals are merged and used in the next stage for object classification. Experiments on the challenging nuScenes dataset show our method outperforms other existing radar-camera fusion methods in the 2D object detection task while at the same time accurately estimates objects' distances.
RRPN: Radar Region Proposal Network for Object Detection in Autonomous Vehicles
May 15, 2019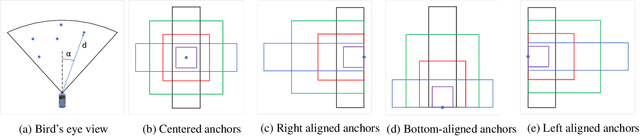

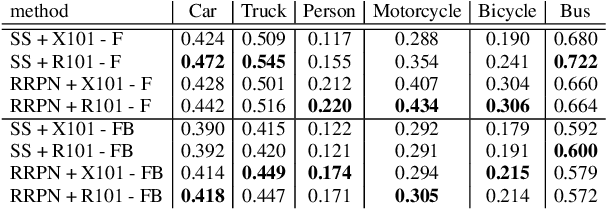
Region proposal algorithms play an important role in most state-of-the-art two-stage object detection networks by hypothesizing object locations in the image. Nonetheless, region proposal algorithms are known to be the bottleneck in most two-stage object detection networks, increasing the processing time for each image and resulting in slow networks not suitable for real-time applications such as autonomous driving vehicles. In this paper we introduce RRPN, a Radar-based real-time region proposal algorithm for object detection in autonomous driving vehicles. RRPN generates object proposals by mapping Radar detections to the image coordinate system and generating pre-defined anchor boxes for each mapped Radar detection point. These anchor boxes are then transformed and scaled based on the object's distance from the vehicle, to provide more accurate proposals for the detected objects. We evaluate our method on the newly released NuScenes dataset [1] using the Fast R-CNN object detection network [2]. Compared to the Selective Search object proposal algorithm [3], our model operates more than 100x faster while at the same time achieves higher detection precision and recall. Code has been made publicly available at https://github.com/mrnabati/RRPN .
Machine-assisted annotation of forensic imagery
Feb 28, 2019
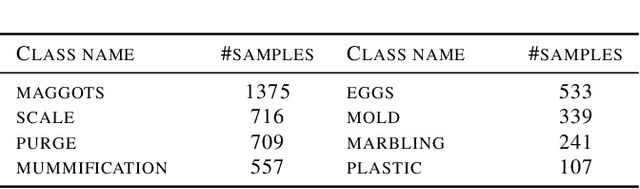
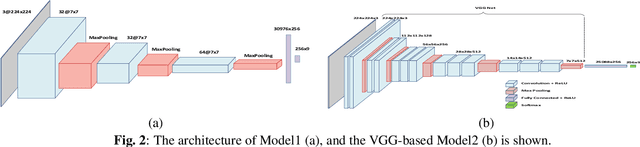
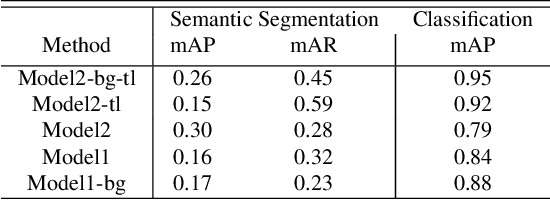
Image collections, if critical aspects of image content are exposed, can spur research and practical applications in many domains. Supervised machine learning may be the only feasible way to annotate very large collections, but leading approaches rely on large samples of completely and accurately annotated images. In the case of a large forensic collection, we are aiming to annotate, neither the complete annotation nor the large training samples can be feasibly produced. We, therefore, investigate ways to assist manual annotation efforts done by forensic experts. We present a method that can propose both images and areas within an image likely to contain desired classes. Evaluation of the method with human annotators showed highly accurate classification that was strongly helped by transfer learning. The segmentation precision (mAP) was improved by adding a separate class capturing background, but that did not affect the recall (mAR). Further work is needed to both increase the accuracy of segmentation and enhances prediction with additional covariates affecting decomposition. We hope this effort to be of help in other domains that require weak segmentation and have limited availability of qualified annotators.