 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKIPPO: Koopman-Inspired Proximal Policy Optimization
May 20, 2025Reinforcement Learning (RL) has made significant strides in various domains, and policy gradient methods like Proximal Policy Optimization (PPO) have gained popularity due to their balance in performance, training stability, and computational efficiency. These methods directly optimize policies through gradient-based updates. However, developing effective control policies for environments with complex and non-linear dynamics remains a challenge. High variance in gradient estimates and non-convex optimization landscapes often lead to unstable learning trajectories. Koopman Operator Theory has emerged as a powerful framework for studying non-linear systems through an infinite-dimensional linear operator that acts on a higher-dimensional space of measurement functions. In contrast with their non-linear counterparts, linear systems are simpler, more predictable, and easier to analyze. In this paper, we present Koopman-Inspired Proximal Policy Optimization (KIPPO), which learns an approximately linear latent-space representation of the underlying system's dynamics while retaining essential features for effective policy learning. This is achieved through a Koopman-approximation auxiliary network that can be added to the baseline policy optimization algorithms without altering the architecture of the core policy or value function. Extensive experimental results demonstrate consistent improvements over the PPO baseline with 6-60% increased performance while reducing variability by up to 91% when evaluated on various continuous control tasks.
Defect Detection in Tire X-Ray Images: Conventional Methods Meet Deep Structures
Feb 28, 2024This paper introduces a robust approach for automated defect detection in tire X-ray images by harnessing traditional feature extraction methods such as Local Binary Pattern (LBP) and Gray Level Co-Occurrence Matrix (GLCM) features, as well as Fourier and Wavelet-based features, complemented by advanced machine learning techniques. Recognizing the challenges inherent in the complex patterns and textures of tire X-ray images, the study emphasizes the significance of feature engineering to enhance the performance of defect detection systems. By meticulously integrating combinations of these features with a Random Forest (RF) classifier and comparing them against advanced models like YOLOv8, the research not only benchmarks the performance of traditional features in defect detection but also explores the synergy between classical and modern approaches. The experimental results demonstrate that these traditional features, when fine-tuned and combined with machine learning models, can significantly improve the accuracy and reliability of tire defect detection, aiming to set a new standard in automated quality assurance in tire manufacturing.
CFTrack: Center-based Radar and Camera Fusion for 3D Multi-Object Tracking
Jul 11, 2021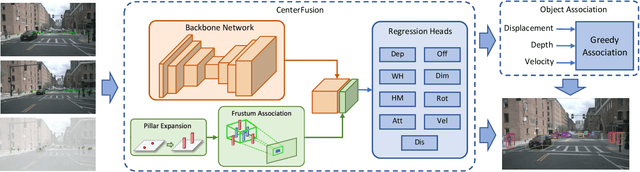
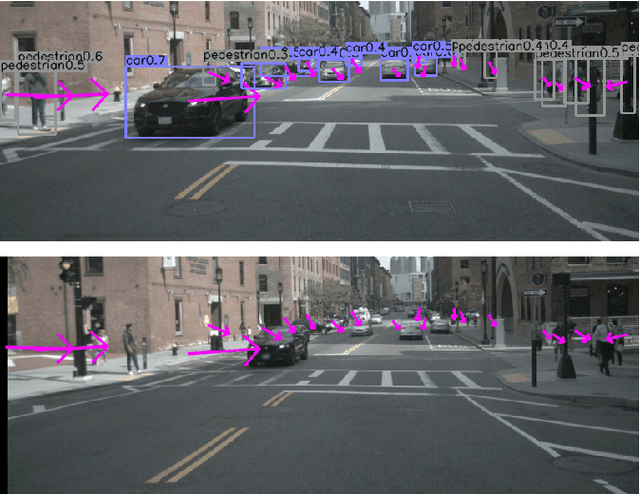
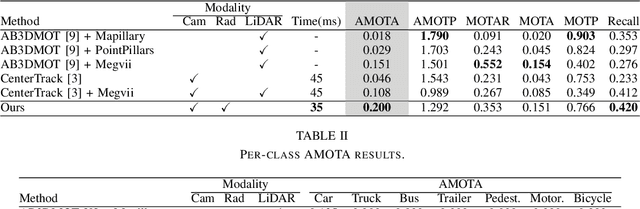
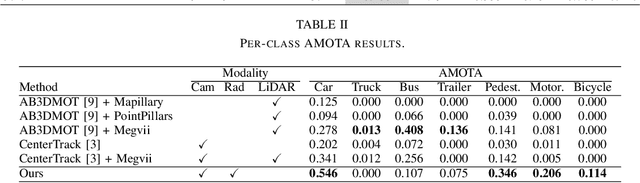
3D multi-object tracking is a crucial component in the perception system of autonomous driving vehicles. Tracking all dynamic objects around the vehicle is essential for tasks such as obstacle avoidance and path planning. Autonomous vehicles are usually equipped with different sensor modalities to improve accuracy and reliability. While sensor fusion has been widely used in object detection networks in recent years, most existing multi-object tracking algorithms either rely on a single input modality, or do not fully exploit the information provided by multiple sensing modalities. In this work, we propose an end-to-end network for joint object detection and tracking based on radar and camera sensor fusion. Our proposed method uses a center-based radar-camera fusion algorithm for object detection and utilizes a greedy algorithm for object association. The proposed greedy algorithm uses the depth, velocity and 2D displacement of the detected objects to associate them through time. This makes our tracking algorithm very robust to occluded and overlapping objects, as the depth and velocity information can help the network in distinguishing them. We evaluate our method on the challenging nuScenes dataset, where it achieves 20.0 AMOTA and outperforms all vision-based 3D tracking methods in the benchmark, as well as the baseline LiDAR-based method. Our method is online with a runtime of 35ms per image, making it very suitable for autonomous driving applications.