 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysically-Constrained Transfer Learning through Shared Abundance Space for Hyperspectral Image Classification
Aug 30, 2020

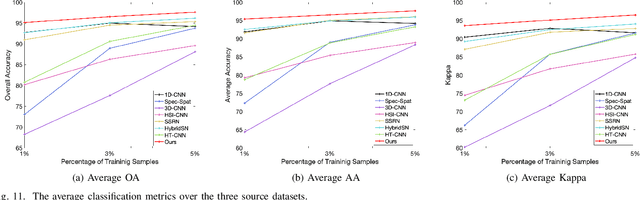
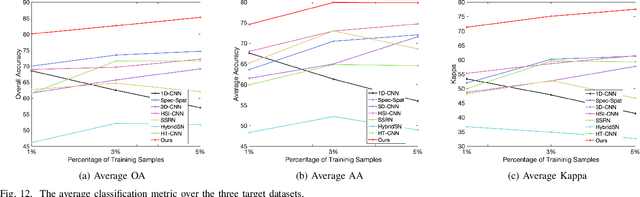
Hyperspectral image (HSI) classification is one of the most active research topics and has achieved promising results boosted by the recent development of deep learning. However, most state-of-the-art approaches tend to perform poorly when the training and testing images are on different domains, e.g., source domain and target domain, respectively, due to the spectral variability caused by different acquisition conditions. Transfer learning-based methods address this problem by pre-training in the source domain and fine-tuning on the target domain. Nonetheless, a considerable amount of data on the target domain has to be labeled and non-negligible computational resources are required to retrain the whole network. In this paper, we propose a new transfer learning scheme to bridge the gap between the source and target domains by projecting the HSI data from the source and target domains into a shared abundance space based on their own physical characteristics. In this way, the domain discrepancy would be largely reduced such that the model trained on the source domain could be applied on the target domain without extra efforts for data labeling or network retraining. The proposed method is referred to as physically-constrained transfer learning through shared abundance space (PCTL-SAS). Extensive experimental results demonstrate the superiority of the proposed method as compared to the state-of-the-art. The success of this endeavor would largely facilitate the deployment of HSI classification for real-world sensing scenarios.
Representative-Discriminative Learning for Open-set Land Cover Classification of Satellite Imagery
Jul 21, 2020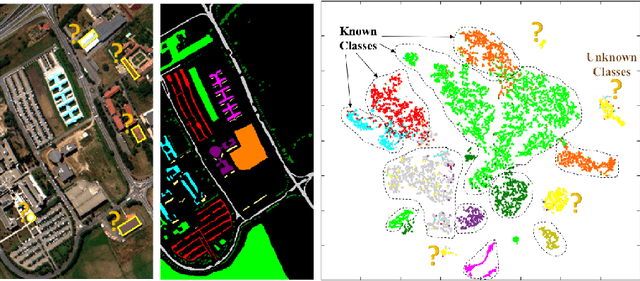

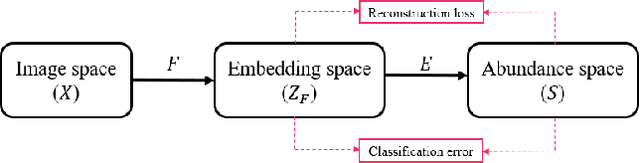
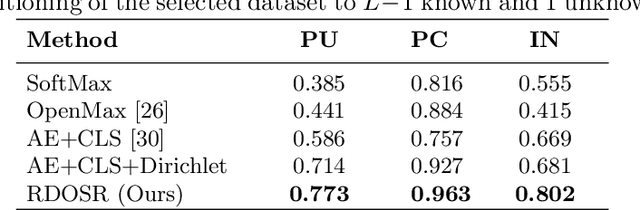
Land cover classification of satellite imagery is an important step toward analyzing the Earth's surface. Existing models assume a closed-set setting where both the training and testing classes belong to the same label set. However, due to the unique characteristics of satellite imagery with an extremely vast area of versatile cover materials, the training data are bound to be non-representative. In this paper, we study the problem of open-set land cover classification that identifies the samples belonging to unknown classes during testing, while maintaining performance on known classes. Although inherently a classification problem, both representative and discriminative aspects of data need to be exploited in order to better distinguish unknown classes from known. We propose a representative-discriminative open-set recognition (RDOSR) framework, which 1) projects data from the raw image space to the embedding feature space that facilitates differentiating similar classes, and further 2) enhances both the representative and discriminative capacity through transformation to a so-called abundance space. Experiments on multiple satellite benchmarks demonstrate the effectiveness of the proposed method. We also show the generality of the proposed approach by achieving promising results on open-set classification tasks using RGB images.
Unsupervised Pansharpening Based on Self-Attention Mechanism
Jun 16, 2020

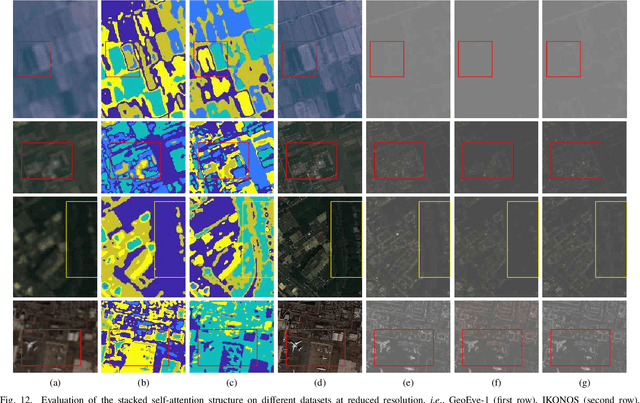

Pansharpening is to fuse a multispectral image (MSI) of low-spatial-resolution (LR) but rich spectral characteristics with a panchromatic image (PAN) of high-spatial-resolution (HR) but poor spectral characteristics. Traditional methods usually inject the extracted high-frequency details from PAN into the up-sampled MSI. Recent deep learning endeavors are mostly supervised assuming the HR MSI is available, which is unrealistic especially for satellite images. Nonetheless, these methods could not fully exploit the rich spectral characteristics in the MSI. Due to the wide existence of mixed pixels in satellite images where each pixel tends to cover more than one constituent material, pansharpening at the subpixel level becomes essential. In this paper, we propose an unsupervised pansharpening (UP) method in a deep-learning framework to address the above challenges based on the self-attention mechanism (SAM), referred to as UP-SAM. The contribution of this paper is three-fold. First, the self-attention mechanism is proposed where the spatial varying detail extraction and injection functions are estimated according to the attention representations indicating spectral characteristics of the MSI with sub-pixel accuracy. Second, such attention representations are derived from mixed pixels with the proposed stacked attention network powered with a stick-breaking structure to meet the physical constraints of mixed pixel formulations. Third, the detail extraction and injection functions are spatial varying based on the attention representations, which largely improves the reconstruction accuracy. Extensive experimental results demonstrate that the proposed approach is able to reconstruct sharper MSI of different types, with more details and less spectral distortion as compared to the state-of-the-art.