 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Transfer of Pretrained Large Visual Model for Fabric Defect Segmentation via Specifc Knowledge Injection
Jun 28, 2023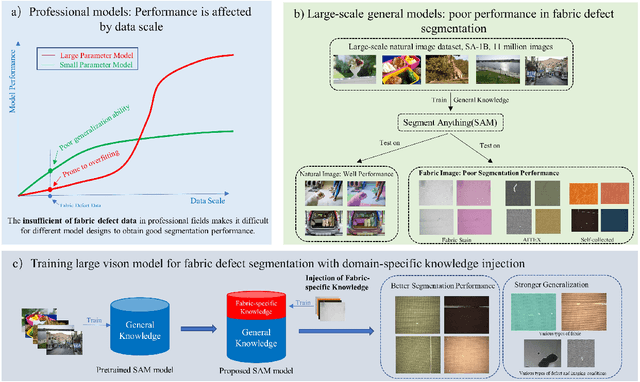
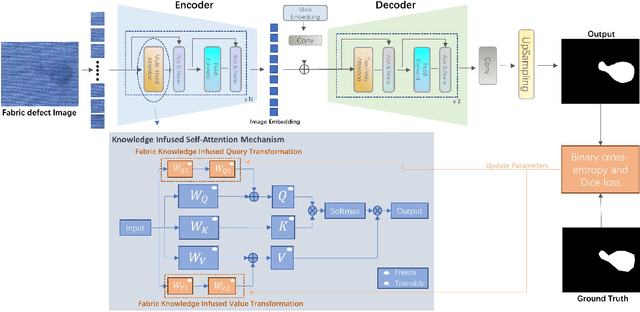


Fabric defect segmentation is integral to textile quality control. Despite this, the scarcity of high-quality annotated data and the diversity of fabric defects present significant challenges to the application of deep learning in this field. These factors limit the generalization and segmentation performance of existing models, impeding their ability to handle the complexity of diverse fabric types and defects. To overcome these obstacles, this study introduces an innovative method to infuse specialized knowledge of fabric defects into the Segment Anything Model (SAM), a large-scale visual model. By introducing and training a unique set of fabric defect-related parameters, this approach seamlessly integrates domain-specific knowledge into SAM without the need for extensive modifications to the pre-existing model parameters. The revamped SAM model leverages generalized image understanding learned from large-scale natural image datasets while incorporating fabric defect-specific knowledge, ensuring its proficiency in fabric defect segmentation tasks. The experimental results reveal a significant improvement in the model's segmentation performance, attributable to this novel amalgamation of generic and fabric-specific knowledge. When benchmarking against popular existing segmentation models across three datasets, our proposed model demonstrates a substantial leap in performance. Its impressive results in cross-dataset comparisons and few-shot learning experiments further demonstrate its potential for practical applications in textile quality control.
Physically-Constrained Transfer Learning through Shared Abundance Space for Hyperspectral Image Classification
Aug 30, 2020

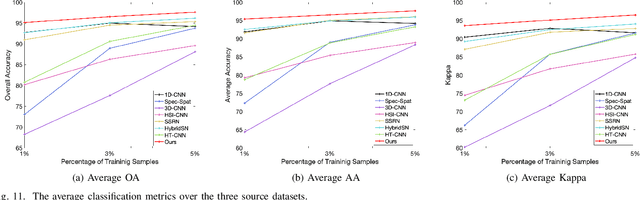
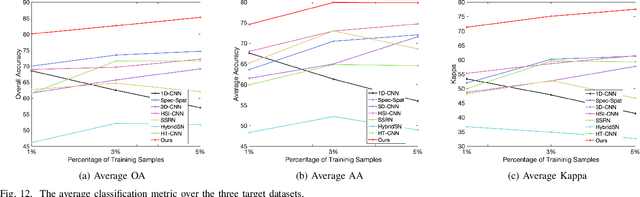
Hyperspectral image (HSI) classification is one of the most active research topics and has achieved promising results boosted by the recent development of deep learning. However, most state-of-the-art approaches tend to perform poorly when the training and testing images are on different domains, e.g., source domain and target domain, respectively, due to the spectral variability caused by different acquisition conditions. Transfer learning-based methods address this problem by pre-training in the source domain and fine-tuning on the target domain. Nonetheless, a considerable amount of data on the target domain has to be labeled and non-negligible computational resources are required to retrain the whole network. In this paper, we propose a new transfer learning scheme to bridge the gap between the source and target domains by projecting the HSI data from the source and target domains into a shared abundance space based on their own physical characteristics. In this way, the domain discrepancy would be largely reduced such that the model trained on the source domain could be applied on the target domain without extra efforts for data labeling or network retraining. The proposed method is referred to as physically-constrained transfer learning through shared abundance space (PCTL-SAS). Extensive experimental results demonstrate the superiority of the proposed method as compared to the state-of-the-art. The success of this endeavor would largely facilitate the deployment of HSI classification for real-world sensing scenarios.
Representative-Discriminative Learning for Open-set Land Cover Classification of Satellite Imagery
Jul 21, 2020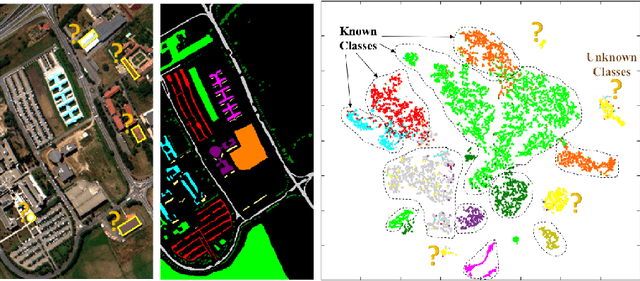

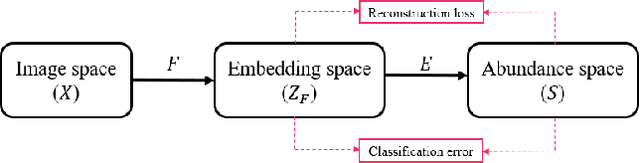
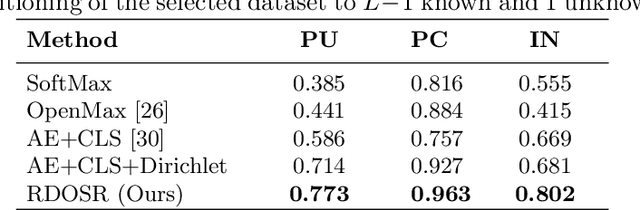
Land cover classification of satellite imagery is an important step toward analyzing the Earth's surface. Existing models assume a closed-set setting where both the training and testing classes belong to the same label set. However, due to the unique characteristics of satellite imagery with an extremely vast area of versatile cover materials, the training data are bound to be non-representative. In this paper, we study the problem of open-set land cover classification that identifies the samples belonging to unknown classes during testing, while maintaining performance on known classes. Although inherently a classification problem, both representative and discriminative aspects of data need to be exploited in order to better distinguish unknown classes from known. We propose a representative-discriminative open-set recognition (RDOSR) framework, which 1) projects data from the raw image space to the embedding feature space that facilitates differentiating similar classes, and further 2) enhances both the representative and discriminative capacity through transformation to a so-called abundance space. Experiments on multiple satellite benchmarks demonstrate the effectiveness of the proposed method. We also show the generality of the proposed approach by achieving promising results on open-set classification tasks using RGB images.
Unsupervised Pansharpening Based on Self-Attention Mechanism
Jun 16, 2020

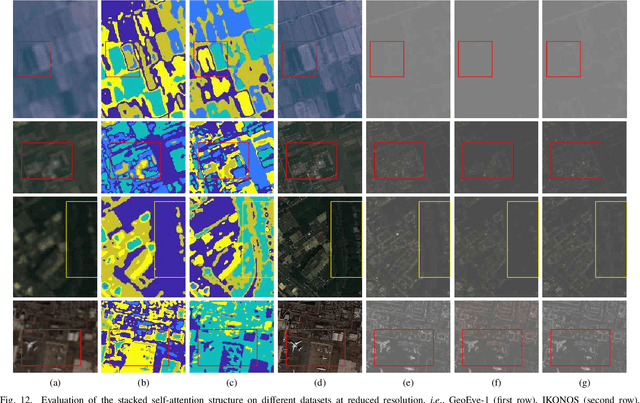

Pansharpening is to fuse a multispectral image (MSI) of low-spatial-resolution (LR) but rich spectral characteristics with a panchromatic image (PAN) of high-spatial-resolution (HR) but poor spectral characteristics. Traditional methods usually inject the extracted high-frequency details from PAN into the up-sampled MSI. Recent deep learning endeavors are mostly supervised assuming the HR MSI is available, which is unrealistic especially for satellite images. Nonetheless, these methods could not fully exploit the rich spectral characteristics in the MSI. Due to the wide existence of mixed pixels in satellite images where each pixel tends to cover more than one constituent material, pansharpening at the subpixel level becomes essential. In this paper, we propose an unsupervised pansharpening (UP) method in a deep-learning framework to address the above challenges based on the self-attention mechanism (SAM), referred to as UP-SAM. The contribution of this paper is three-fold. First, the self-attention mechanism is proposed where the spatial varying detail extraction and injection functions are estimated according to the attention representations indicating spectral characteristics of the MSI with sub-pixel accuracy. Second, such attention representations are derived from mixed pixels with the proposed stacked attention network powered with a stick-breaking structure to meet the physical constraints of mixed pixel formulations. Third, the detail extraction and injection functions are spatial varying based on the attention representations, which largely improves the reconstruction accuracy. Extensive experimental results demonstrate that the proposed approach is able to reconstruct sharper MSI of different types, with more details and less spectral distortion as compared to the state-of-the-art.
One-Shot Mutual Affine-Transfer for Photorealistic Stylization
Jul 24, 2019

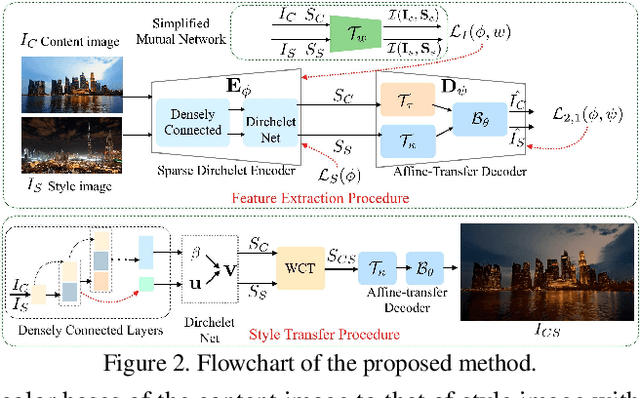
Photorealistic style transfer aims to transfer the style of a reference photo onto a content photo naturally, such that the stylized image looks like a real photo taken by a camera. Existing state-of-the-art methods are prone to spatial structure distortion of the content image and global color inconsistency across different semantic objects, making the results less photorealistic. In this paper, we propose a one-shot mutual Dirichlet network, to address these challenging issues. The essential contribution of the work is the realization of a representation scheme that successfully decouples the spatial structure and color information of images, such that the spatial structure can be well preserved during stylization. This representation is discriminative and context-sensitive with respect to semantic objects. It is extracted with a shared sparse Dirichlet encoder. Moreover, such representation is encouraged to be matched between the content and style images for faithful color transfer. The affine-transfer model is embedded in the decoder of the network to facilitate the color transfer. The strong representative and discriminative power of the proposed network enables one-shot learning given only one content-style image pair. Experimental results demonstrate that the proposed method is able to generate photorealistic photos without spatial distortion or abrupt color changes.
Unsupervised and Unregistered Hyperspectral Image Super-Resolution with Mutual Dirichlet-Net
May 10, 2019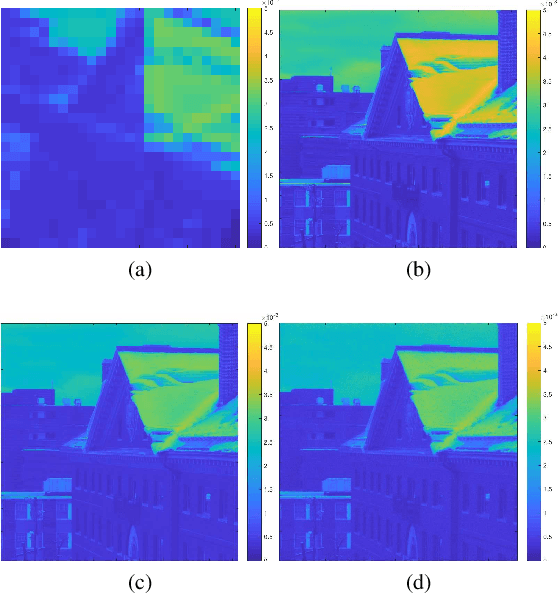


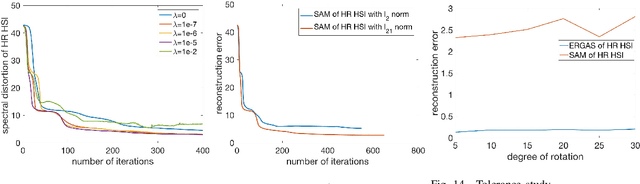
Hyperspectral images (HSI) provide rich spectral information that contributed to the successful performance improvement of numerous computer vision tasks. However, it can only be achieved at the expense of images' spatial resolution. Hyperspectral image super-resolution (HSI-SR) addresses this problem by fusing low resolution (LR) HSI with multispectral image (MSI) carrying much higher spatial resolution (HR). All existing HSI-SR approaches require the LR HSI and HR MSI to be well registered and the reconstruction accuracy of the HR HSI relies heavily on the registration accuracy of different modalities. This paper exploits the uncharted problem domain of HSI-SR without the requirement of multi-modality registration. Given the unregistered LR HSI and HR MSI with overlapped regions, we design a unique unsupervised learning structure linking the two unregistered modalities by projecting them into the same statistical space through the same encoder. The mutual information (MI) is further adopted to capture the non-linear statistical dependencies between the representations from two modalities (carrying spatial information) and their raw inputs. By maximizing the MI, spatial correlations between different modalities can be well characterized to further reduce the spectral distortion. A collaborative $l_{2,1}$ norm is employed as the reconstruction error instead of the more common $l_2$ norm, so that individual pixels can be recovered as accurately as possible. With this design, the network allows to extract correlated spectral and spatial information from unregistered images that better preserves the spectral information. The proposed method is referred to as unregistered and unsupervised mutual Dirichlet Net ($u^2$-MDN). Extensive experimental results using benchmark HSI datasets demonstrate the superior performance of $u^2$-MDN as compared to the state-of-the-art.
Unsupervised Trajectory Segmentation and Promoting of Multi-Modal Surgical Demonstrations
Oct 01, 2018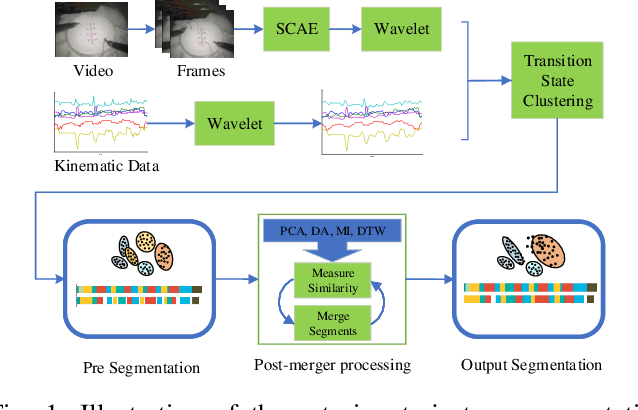
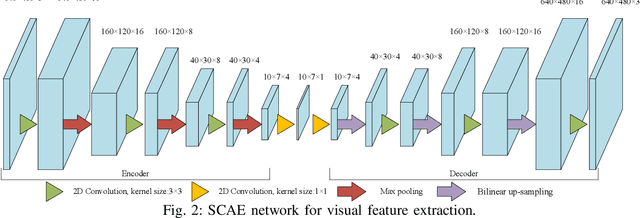
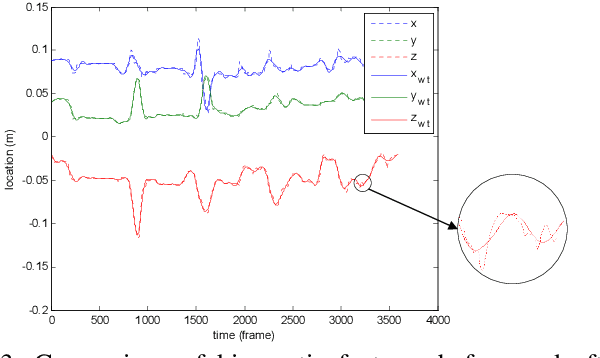
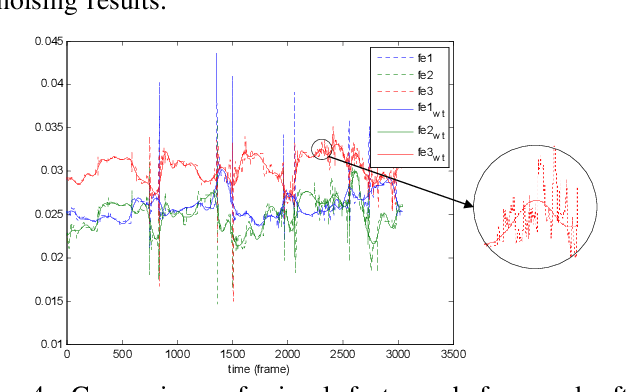
To improve the efficiency of surgical trajectory segmentation for robot learning in robot-assisted minimally invasive surgery, this paper presents a fast unsupervised method using video and kinematic data, followed by a promoting procedure to address the over-segmentation issue. Unsupervised deep learning network, stacking convolutional auto-encoder, is employed to extract more discriminative features from videos in an effective way. To further improve the accuracy of segmentation, on one hand, wavelet transform is used to filter out the noises existed in the features from video and kinematic data. On the other hand, the segmentation result is promoted by identifying the adjacent segments with no state transition based on the predefined similarity measurements. Extensive experiments on a public dataset JIGSAWS show that our method achieves much higher accuracy of segmentation than state-of-the-art methods in the shorter time.
Unsupervised Sparse Dirichlet-Net for Hyperspectral Image Super-Resolution
Jul 15, 2018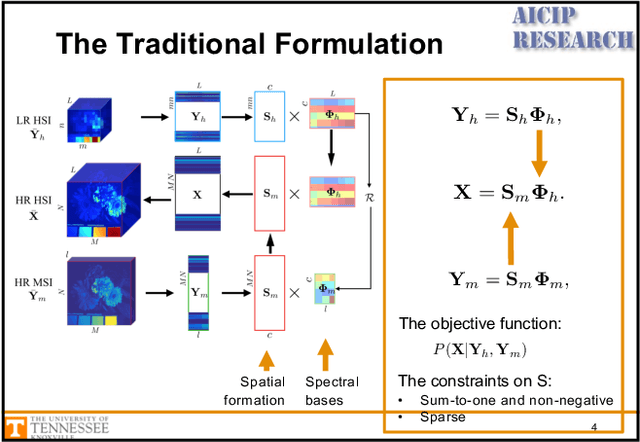
In many computer vision applications, obtaining images of high resolution in both the spatial and spectral domains are equally important. However, due to hardware limitations, one can only expect to acquire images of high resolution in either the spatial or spectral domains. This paper focuses on hyperspectral image super-resolution (HSI-SR), where a hyperspectral image (HSI) with low spatial resolution (LR) but high spectral resolution is fused with a multispectral image (MSI) with high spatial resolution (HR) but low spectral resolution to obtain HR HSI. Existing deep learning-based solutions are all supervised that would need a large training set and the availability of HR HSI, which is unrealistic. Here, we make the first attempt to solving the HSI-SR problem using an unsupervised encoder-decoder architecture that carries the following uniquenesses. First, it is composed of two encoder-decoder networks, coupled through a shared decoder, in order to preserve the rich spectral information from the HSI network. Second, the network encourages the representations from both modalities to follow a sparse Dirichlet distribution which naturally incorporates the two physical constraints of HSI and MSI. Third, the angular difference between representations are minimized in order to reduce the spectral distortion. We refer to the proposed architecture as unsupervised Sparse Dirichlet-Net, or uSDN. Extensive experimental results demonstrate the superior performance of uSDN as compared to the state-of-the-art.