 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminative models for robust image classification
Mar 08, 2016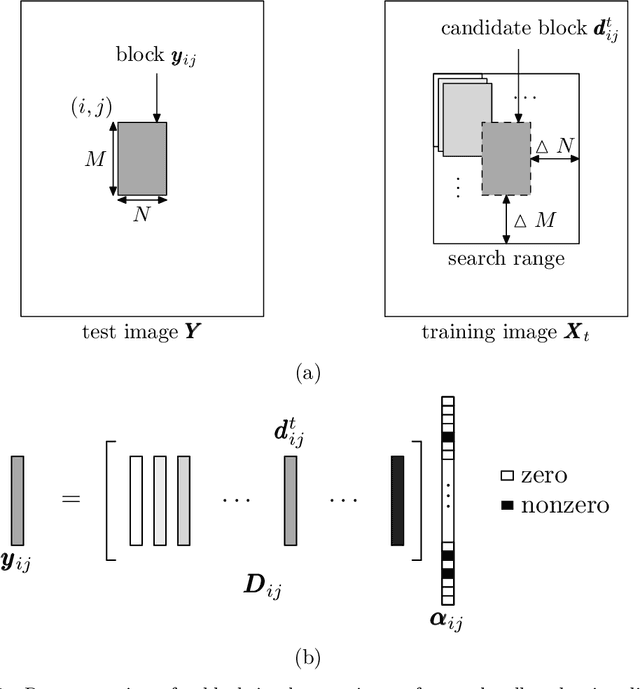

A variety of real-world tasks involve the classification of images into pre-determined categories. Designing image classification algorithms that exhibit robustness to acquisition noise and image distortions, particularly when the available training data are insufficient to learn accurate models, is a significant challenge. This dissertation explores the development of discriminative models for robust image classification that exploit underlying signal structure, via probabilistic graphical models and sparse signal representations. Probabilistic graphical models are widely used in many applications to approximate high-dimensional data in a reduced complexity set-up. Learning graphical structures to approximate probability distributions is an area of active research. Recent work has focused on learning graphs in a discriminative manner with the goal of minimizing classification error. In the first part of the dissertation, we develop a discriminative learning framework that exploits the complementary yet correlated information offered by multiple representations (or projections) of a given signal/image. Specifically, we propose a discriminative tree-based scheme for feature fusion by explicitly learning the conditional correlations among such multiple projections in an iterative manner. Experiments reveal the robustness of the resulting graphical model classifier to training insufficiency.
Multi-task Image Classification via Collaborative, Hierarchical Spike-and-Slab Priors
Jan 30, 2015

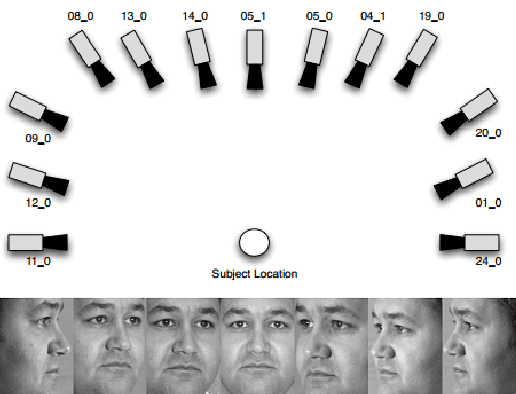
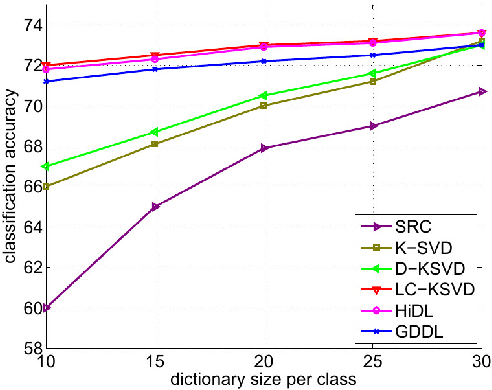
Promising results have been achieved in image classification problems by exploiting the discriminative power of sparse representations for classification (SRC). Recently, it has been shown that the use of \emph{class-specific} spike-and-slab priors in conjunction with the class-specific dictionaries from SRC is particularly effective in low training scenarios. As a logical extension, we build on this framework for multitask scenarios, wherein multiple representations of the same physical phenomena are available. We experimentally demonstrate the benefits of mining joint information from different camera views for multi-view face recognition.
Structured Dictionary Learning for Classification
Jun 08, 2014

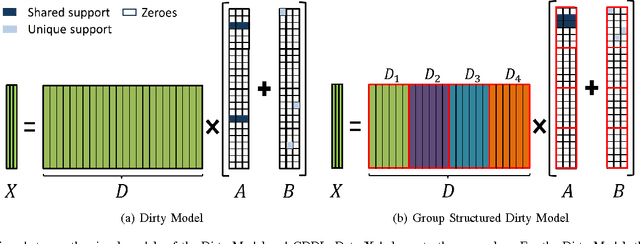
Sparsity driven signal processing has gained tremendous popularity in the last decade. At its core, the assumption is that the signal of interest is sparse with respect to either a fixed transformation or a signal dependent dictionary. To better capture the data characteristics, various dictionary learning methods have been proposed for both reconstruction and classification tasks. For classification particularly, most approaches proposed so far have focused on designing explicit constraints on the sparse code to improve classification accuracy while simply adopting $l_0$-norm or $l_1$-norm for sparsity regularization. Motivated by the success of structured sparsity in the area of Compressed Sensing, we propose a structured dictionary learning framework (StructDL) that incorporates the structure information on both group and task levels in the learning process. Its benefits are two-fold: (i) the label consistency between dictionary atoms and training data are implicitly enforced; and (ii) the classification performance is more robust in the cases of a small dictionary size or limited training data than other techniques. Using the subspace model, we derive the conditions for StructDL to guarantee the performance and show theoretically that StructDL is superior to $l_0$-norm or $l_1$-norm regularized dictionary learning for classification. Extensive experiments have been performed on both synthetic simulations and real world applications, such as face recognition and object classification, to demonstrate the validity of the proposed DL framework.
Discriminative Local Sparse Representations for Robust Face Recognition
Nov 08, 2011
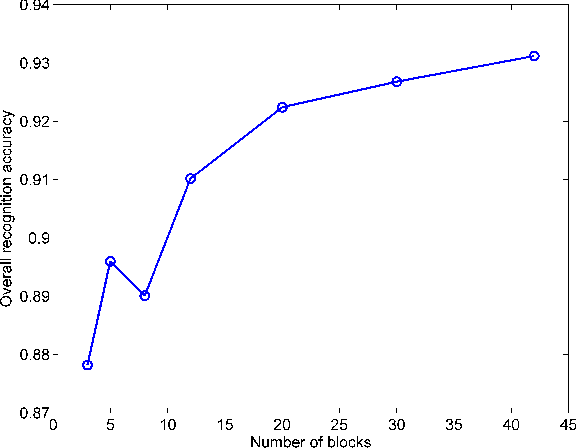
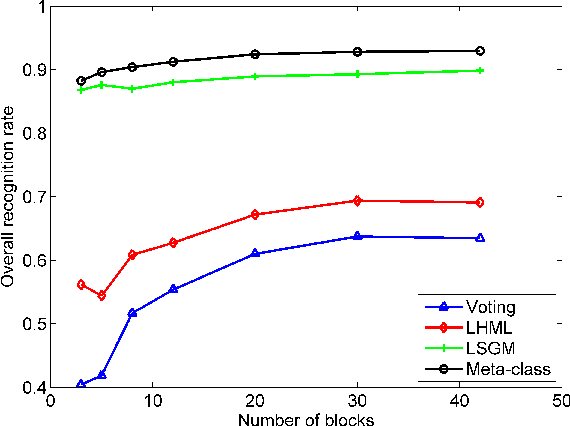
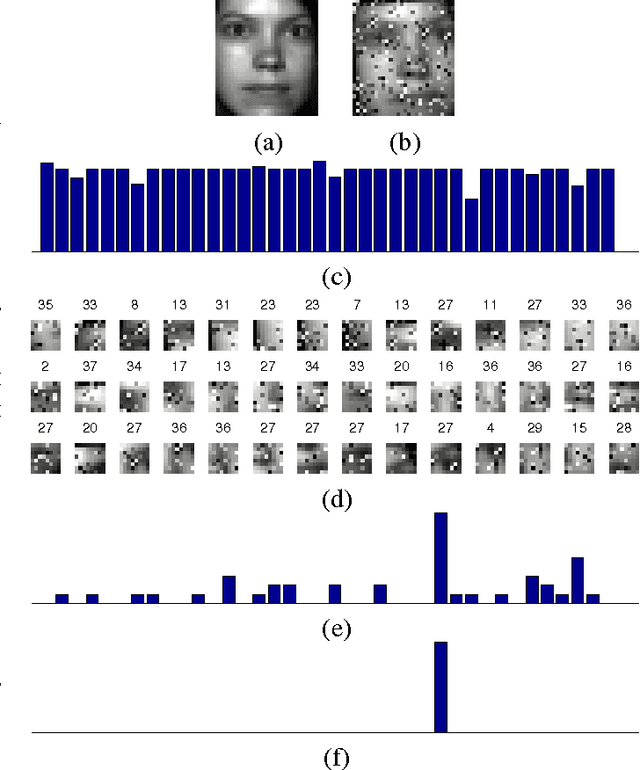
A key recent advance in face recognition models a test face image as a sparse linear combination of a set of training face images. The resulting sparse representations have been shown to possess robustness against a variety of distortions like random pixel corruption, occlusion and disguise. This approach however makes the restrictive (in many scenarios) assumption that test faces must be perfectly aligned (or registered) to the training data prior to classification. In this paper, we propose a simple yet robust local block-based sparsity model, using adaptively-constructed dictionaries from local features in the training data, to overcome this misalignment problem. Our approach is inspired by human perception: we analyze a series of local discriminative features and combine them to arrive at the final classification decision. We propose a probabilistic graphical model framework to explicitly mine the conditional dependencies between these distinct sparse local features. In particular, we learn discriminative graphs on sparse representations obtained from distinct local slices of a face. Conditional correlations between these sparse features are first discovered (in the training phase), and subsequently exploited to bring about significant improvements in recognition rates. Experimental results obtained on benchmark face databases demonstrate the effectiveness of the proposed algorithms in the presence of multiple registration errors (such as translation, rotation, and scaling) as well as under variations of pose and illumination.