 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Object Detection in Medical Image Analysis through Multiple Expert Annotators: An Empirical Investigation
Mar 29, 2023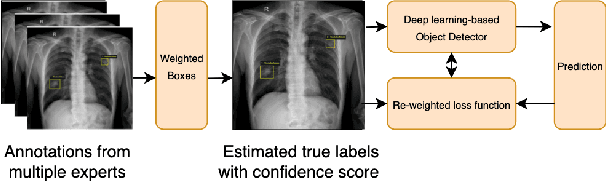

The work discusses the use of machine learning algorithms for anomaly detection in medical image analysis and how the performance of these algorithms depends on the number of annotators and the quality of labels. To address the issue of subjectivity in labeling with a single annotator, we introduce a simple and effective approach that aggregates annotations from multiple annotators with varying levels of expertise. We then aim to improve the efficiency of predictive models in abnormal detection tasks by estimating hidden labels from multiple annotations and using a re-weighted loss function to improve detection performance. Our method is evaluated on a real-world medical imaging dataset and outperforms relevant baselines that do not consider disagreements among annotators.
Learning for Amalgamation: A Multi-Source Transfer Learning Framework For Sentiment Classification
Mar 16, 2023



Transfer learning plays an essential role in Deep Learning, which can remarkably improve the performance of the target domain, whose training data is not sufficient. Our work explores beyond the common practice of transfer learning with a single pre-trained model. We focus on the task of Vietnamese sentiment classification and propose LIFA, a framework to learn a unified embedding from several pre-trained models. We further propose two more LIFA variants that encourage the pre-trained models to either cooperate or compete with one another. Studying these variants sheds light on the success of LIFA by showing that sharing knowledge among the models is more beneficial for transfer learning. Moreover, we construct the AISIA-VN-Review-F dataset, the first large-scale Vietnamese sentiment classification database. We conduct extensive experiments on the AISIA-VN-Review-F and existing benchmarks to demonstrate the efficacy of LIFA compared to other techniques. To contribute to the Vietnamese NLP research, we publish our source code and datasets to the research community upon acceptance.
Enhancing Deep Learning-based 3-lead ECG Classification with Heartbeat Counting and Demographic Data Integration
Aug 15, 2022
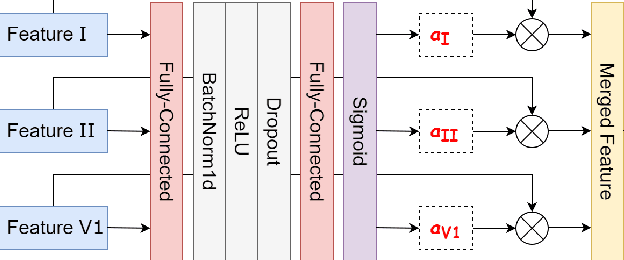
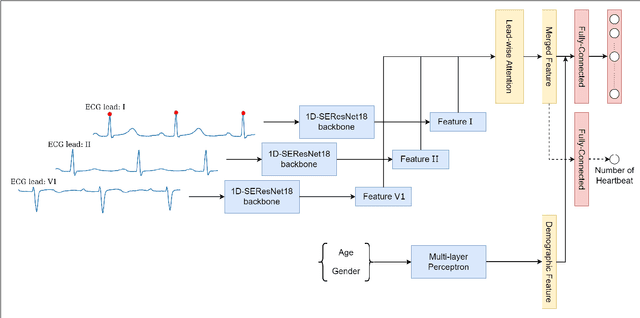
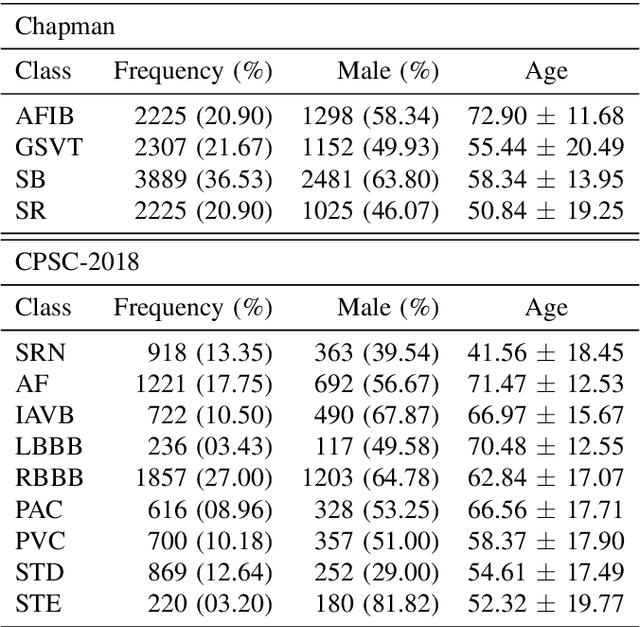
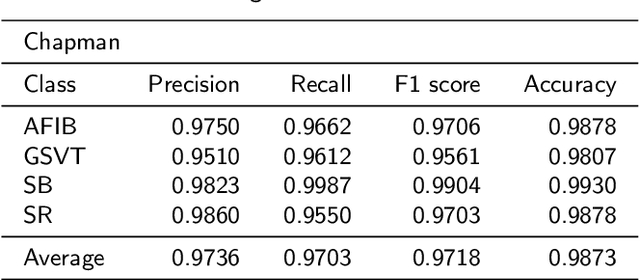
Nowadays, an increasing number of people are being diagnosed with cardiovascular diseases (CVDs), the leading cause of death globally. The gold standard for identifying these heart problems is via electrocardiogram (ECG). The standard 12-lead ECG is widely used in clinical practice and the majority of current research. However, using a lower number of leads can make ECG more pervasive as it can be integrated with portable or wearable devices. This article introduces two novel techniques to improve the performance of the current deep learning system for 3-lead ECG classification, making it comparable with models that are trained using standard 12-lead ECG. Specifically, we propose a multi-task learning scheme in the form of the number of heartbeats regression and an effective mechanism to integrate patient demographic data into the system. With these two advancements, we got classification performance in terms of F1 scores of 0.9796 and 0.8140 on two large-scale ECG datasets, i.e., Chapman and CPSC-2018, respectively, which surpassed current state-of-the-art ECG classification methods, even those trained on 12-lead data. To encourage further development, our source code is publicly available at https://github.com/lhkhiem28/LightX3ECG.
LightX3ECG: A Lightweight and eXplainable Deep Learning System for 3-lead Electrocardiogram Classification
Jul 25, 2022
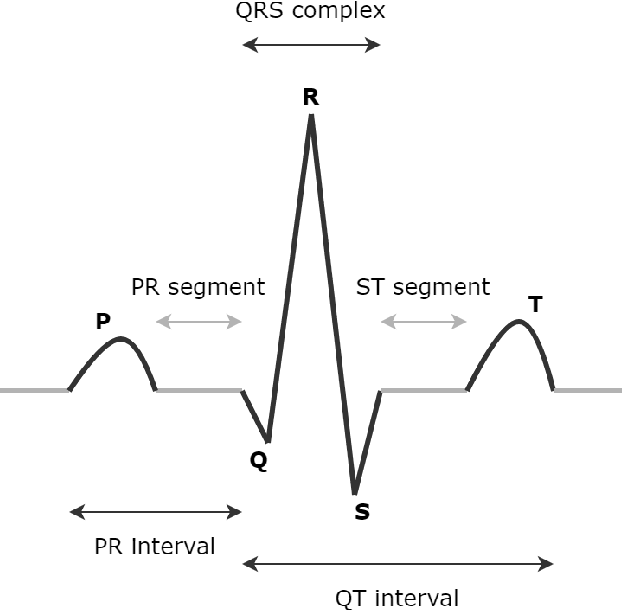
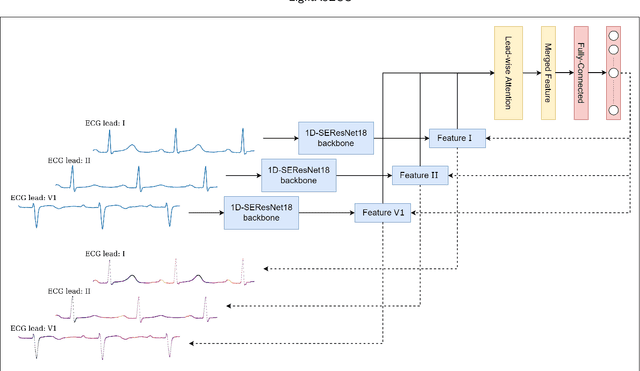
Cardiovascular diseases (CVDs) are a group of heart and blood vessel disorders that is one of the most serious dangers to human health, and the number of such patients is still growing. Early and accurate detection plays a key role in successful treatment and intervention. Electrocardiogram (ECG) is the gold standard for identifying a variety of cardiovascular abnormalities. In clinical practices and most of the current research, standard 12-lead ECG is mainly used. However, using a lower number of leads can make ECG more prevalent as it can be conveniently recorded by portable or wearable devices. In this research, we develop a novel deep learning system to accurately identify multiple cardiovascular abnormalities by using only three ECG leads.
Learning from Multiple Expert Annotators for Enhancing Anomaly Detection in Medical Image Analysis
Mar 20, 2022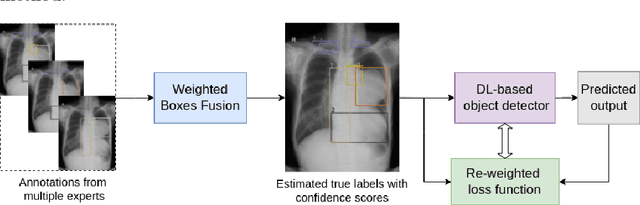
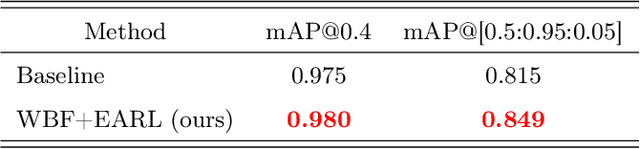
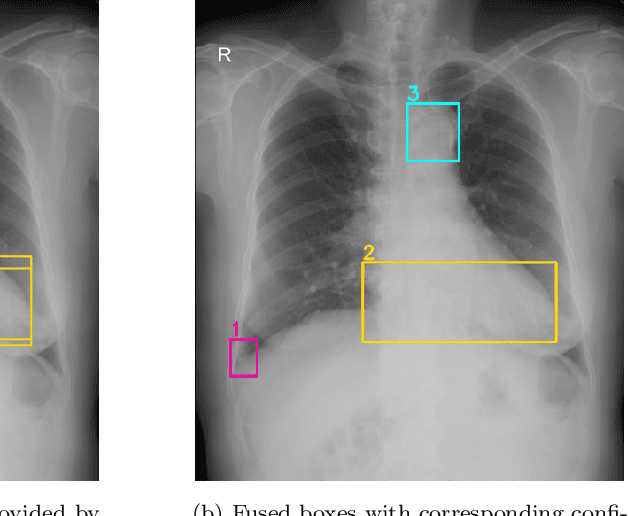
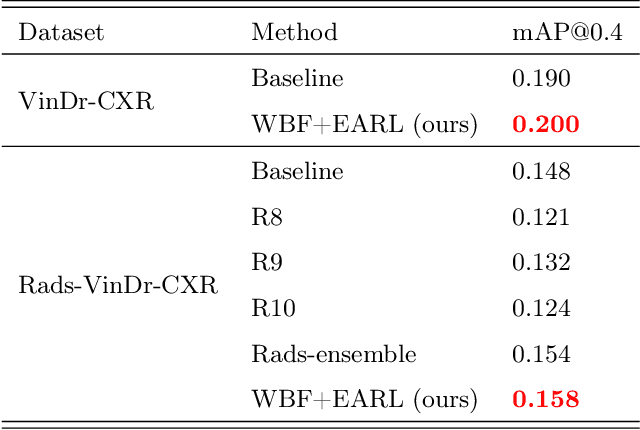
Building an accurate computer-aided diagnosis system based on data-driven approaches requires a large amount of high-quality labeled data. In medical imaging analysis, multiple expert annotators often produce subjective estimates about "ground truth labels" during the annotation process, depending on their expertise and experience. As a result, the labeled data may contain a variety of human biases with a high rate of disagreement among annotators, which significantly affect the performance of supervised machine learning algorithms. To tackle this challenge, we propose a simple yet effective approach to combine annotations from multiple radiology experts for training a deep learning-based detector that aims to detect abnormalities on medical scans. The proposed method first estimates the ground truth annotations and confidence scores of training examples. The estimated annotations and their scores are then used to train a deep learning detector with a re-weighted loss function to localize abnormal findings. We conduct an extensive experimental evaluation of the proposed approach on both simulated and real-world medical imaging datasets. The experimental results show that our approach significantly outperforms baseline approaches that do not consider the disagreements among annotators, including methods in which all of the noisy annotations are treated equally as ground truth and the ensemble of different models trained on different label sets provided separately by annotators.